本文来自微信公众号“电子发烧友网Elecfans”。
电子发烧友网综合报道最近理想官宣了其自研AI芯片马赫M100,并将在刚刚上市的全新一代理想L9车型上搭载。不出意外的话,与蔚来、小鹏类似,理想在后续车型中也将会陆续更换自研自动驾驶芯片。

在官方宣传中,马赫M100是全球首款基于数据流架构的大算力端侧推理芯片,为AI原生设计。单芯片算力达到1280TOPS,采用车规级5nm工艺,端到端响应时间小于300ms。
值得关注的是,这颗芯片架构上与目前市面上常见的自动驾驶芯片都有明显区别,也就是前面提到的数据流架构。那么什么是数据流架构?为什么理想要选择这样的路线?优势又是什么?这些问题在此前理想在《M100:An Orchestrated Dataflow Architecture Powering General AI Computing》论文中,已经有所解答。
简单来说,传统的CPU、GPU采用的冯·诺依曼架构可以理解为是“指令驱动”的架构,处理器从内存中取出指令,再取出数据,执行指令,结果写回内存。计算顺序由指令的序列严格规定。如果数据没准备好,计算单元就必须挂起等待;为了掩盖这种高延迟,芯片不得不设计极其复杂的缓存层级和分支预测技术。
而数据流架构的核心思想是,计算不由指令序列触发,而由数据的就绪来触发。只要输入数据就绪,就自动触发计算,计算完把结果送给下一个单元,形成流水线。全程数据自己“流”过芯片,不用硬件反复调度。
理想选择数据流架构,是针对当前AI计算困境的精准破局。目前自动驾驶(如端到端VLA模型、UniAD等拓扑架构)以及智能座舱的大语言模型,其底层几乎100%是规则的矩阵、张量运算,这种工作负载的数据流向在编译期是高度确定且可预测的。
在车规级场景下,功耗和散热受到极严格的限制,无法像数据中心那样无限制地堆砌高带宽内存。传统GPU依赖高昂的自动缓存来搬运数据,不仅功耗极高,而且由于缓存命中率的波动,会导致时延产生不可预测的抖动。这对于需要绝对确定性、低时延的自动驾驶安全系统来说,是一个巨大的隐患。
如果做纯专用芯片ASIC,把固定的卷积流水线死死地刻在硬件上,虽然效率极高,但只要AI算法一变,芯片可能刚量产就过时了。
所以理想在数据流架构的基础上,加入了“周密编排”能力,通过软件编译器来动态编排硬件上的数据流动,既保留了专用芯片的超高效能,又具备了通过软件升级来兼容未来新算法的灵活性。
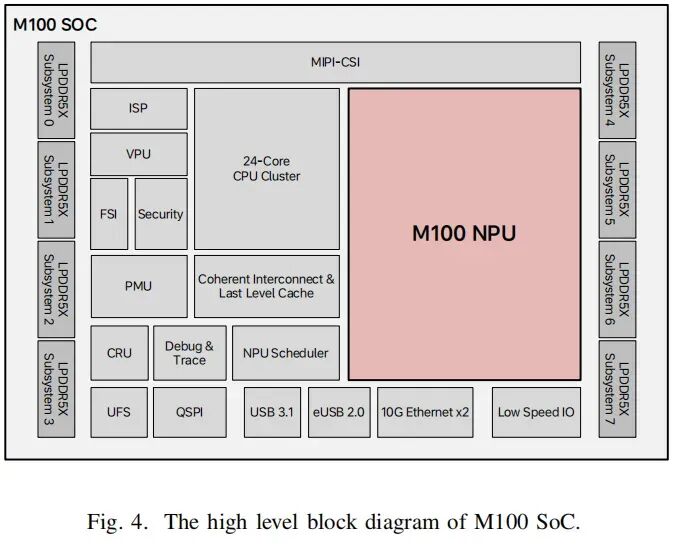
在算力设计上,M100以张量为基础数据单元,构建张量、向量、标量三级异构算力体系。NPU核心的Tensor Processing Block(TPB)集成Tensor Computing Unit(TCU),采用8×64 MAC阵列设计,单周期可完成4维点积运算,专为卷积、矩阵乘等AI核心算子优化,配合双缓冲机制持续跑出峰值算力。Configurable Vector Unit(CVU)则以模块化可重构流水线,高效支持Softmax、LayerNorm、池化等向量操作,完美适配Transformer与车载大模型推理。轻量级RISC‑V核心专注处理标量与不规则运算,让专用算力不被杂务占用,实现算力分层、各司其职。
存储与互联是M100另一大亮点。它几乎完全摒弃多级缓存,改用高带宽片上存储+可编程DMA的显式数据搬运方案。每个TPB内置2MB高带宽共享内存(HBSM),采用32组交错存储Bank,单周期提供32字节访问带宽,计算单元直连流式读写,消除缓存冲突与一致性开销。中央控制块(CCB)集成32MB SRAM,配合多通道DMA实现片上存储与DDR的高效数据交互,让计算与数据搬运重叠执行,充分压榨带宽利用率。
为适配车载大规模并行计算,M100采用双互联架构:2D Mesh总线提供高带宽点到点通信,满足灵活的数据交互;Data Ring Bus(DRB)提供256GB/s确定性广播能力,专为权重多播、特征分发优化。指令则通过Instruction Chain Bus(ICB)链式下发,长张量指令虽体积庞大,但执行周期远长于传输周期,调度全程无瓶颈。
同步机制上,M100用硬件同步计数器(SC)替代传统原子操作与缓存一致性同步,采用生产者‑消费者双向同步模型。生产者写入数据后更新计数器,消费者监测计数器就绪后执行,全程硬件加速、延迟极低。该机制支持Barrier、Broadcast、Reduction等多种同步模式,可跨TPB、跨NPU扩展,为大规模并行推理提供确定性低延迟保障。
车规级特性与可扩展设计,让M100真正适配量产汽车场景。其NPU由1个中央控制块与14个TPB集群组成,支持缺陷集群屏蔽,屏蔽2个集群仍可保留86%算力,显著提升芯片良率。算力支持多域隔离分配,8个集群专注自动驾驶感知规划,6个集群支撑座舱大模型与交互,多任务并行且互不干扰,满足车载混合负载需求。同时芯片集成功能安全岛(FSI)与安全引擎,符合车规功能安全要求。
软硬件全栈协同是M100发挥性能的关键。编译器时空调度器将神经网络子图空间映射到硬件,张量切分后以流水线方式流式执行,最大化硬件利用率。图编译层实现张量融合、代数化简、布局转换等优化,后端配合固件JIT动态生成最优指令,适配从传统CNN到端到端Transformer、MoE大模型的全谱系算法。
实测数据也印证了架构先进性:同功耗、同273GB/s DDR带宽下,M100在自动驾驶UniAD场景实现30FPS实时推理,性能达NVIDIA Thor‑U的3.8倍;LLaMA2‑7B预填充阶段提速1.95倍;自研MindVLA模型解码与预填充分别实现3倍、2.1倍加速。更小的399.8mm²芯片面积与N5A工艺,让M100在成本与能效上具备量产优势。
总结下来,相比传统的自动驾驶芯片,理想马赫M100芯片所采用的周密编排数据流架构,相比传统芯片有四大优势:极致的硬件利用率与能效比、降低数据搬运延迟、确定性的“超低延迟”、零开销的硬件级别同步。
理想选择数据流架构,实质上是完成了“用软件编译器的确定性,去换取硬件的极致精简、低成本与高能效”的底层逻辑闭环。可以期待一下接下来搭载这款芯片的车型上市后,其辅助驾驶系统的实际表现。
