随着各个行业信息化的快速发展,当今各个垂直领域的数据越来越多,而其中有很多数据都是无用的,不需特殊处理。如何快速、高效从垂直领域内的海量数据中检索、智能挖掘出有用的信息成为现在智能搜索引擎发展的一大难题。随着搜索引擎技术的发展,出现了各种各样的搜索引擎技术,但绝大部分搜索引擎技术针对特殊领域中的特殊术语和特殊表达方式不能进行有效的检索和智能推荐,所以传统的搜索引擎技术不能满足当前行业的需求,这就促进了分布式智能搜索引擎的发展。
分布式智能搜索引擎不仅仅只是根据各个垂直领域的不同进行自适应处理,而且还能在提高检索精度和检索效率的基础上,针对已有的海量数据检索、挖掘出用户潜在关注的一些信息,让搜索引擎能够提供更加友好、智能的为用户提供交互。
01
Elasticsearch 基础概念
Elasticsearch(ES)是一个高度可伸缩的开源全文搜索和分析引擎。它允许以近实时的方式快速存储、搜索和分析大量的数据。Elaticsearch有很好的查询性能以及强大的查询语法。在一定场合下可以替代RDBMS做为OLAP的用途。但是其官方查询语法并不是SQL,而是其独创的DSL。
近实时:首先,从写入数据到数据可以被搜索到有一个小延迟(大概1 秒);其次,执行搜索和分析可以达到秒级。
Cluster(集群):集群的每个节点属于哪个集群是通过配置(集群名称,默认是elasticsearch)决定的,对于中小型应用一个集群通常就一个节点。
Node(节点):节点也有名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时候),默认节点会去加入一个名为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个elasticsearch集群。
Index(索引-数据库):索引包含一堆有相似结构的文档数据,比如客户索引、商品分类索引、订单索引,索引有一个名称。一个索引包含很多document,一个索引就代表了一类类似的或者相同的document。
Type(类型-表):每个索引里都可以有一个或多个类型,类型是索引中的一个逻辑数据分类,一个类型下的document,都有相同的field。比如博客系统,有一个索引,可以定义用户数据type、博客数据type、评论数据type。
Document(文档-行):文档是ES中的最小数据单元,一个document可以是一条客户数据、商品分类数据或者订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。
Field(字段-列):Field是Elasticsearch的最小单位。一个document里面有多个field,每个field就是一个数据字段。
mapping(映射-约束):数据如何存放到索引对象上,需要有一个映射配置,包括:数据类型、是否存储、是否分词等。
02
与关系型数据库(RDBMS)的类比
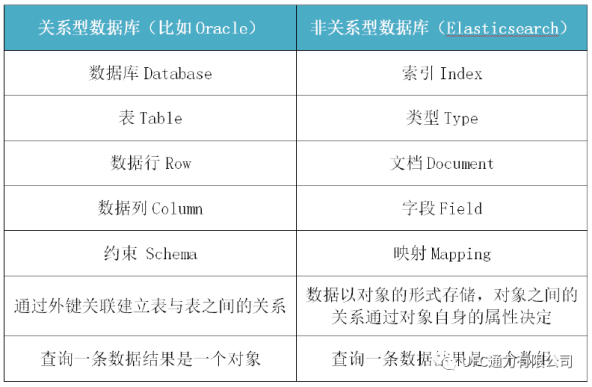
将ES与关系型数据库的相应字段对比
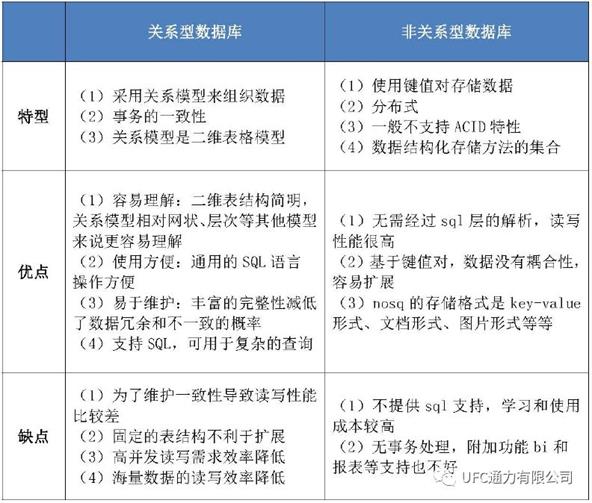
两种类型的优缺点对比
03
Elasticsearch 作为数据库的特型
无事务:Lucene是ES的构建的基础,没有事务的概念。ES对于已经提交的文档无法回滚, 使用者也不能提交一组文档并且为它们全部或一部分建立索引。它具备的是一个用来确保业务过程持久性而不用做昂贵的Lucene提交的预写日志。也可以指定索引操作的一致性级别,以确保在返回之前有多少副本可以拿来确认操作条件。默认的是法定人数,例如?n2? 在逐个切片进行处理的方式中,当一个索引被刷新时,默认是一秒钟一次,就需要对变更的可见性进行控制。ES追求的是分布式事务的速度,不支持分布式事务会使得很多事情变得更容易,只要能接受读取到的数据有些陈旧,而且所有人看到的是同一时间点的数据,ES就可以利用缓存提供很多服务。
模式灵活:ES不要求先指定模式,扔给它一个JSON文档它就会进行一些训练有素的猜测来推断其类型。对于数值、布尔、时间戳它可以做的很好。对于字符串,它会使用“标准化”的分析,它是有商榷的“无模式”,在这个意义上不必指定一个模式。为了开发大规模的搜索、分析,确实需要对模式进行微调。ES有大量的强大工具,例如动态模板、多字段对象等。
关系和约束:ES更像是一种面向文档的数据库。想要对搜索的整个对象关系图都需要进行索引,在此之前,它们必须先被反规范化。反规范化提升了查询性能(不再需要关联查询),使用了更多存储空间(数据必须被存储多次)。但是,要保持数据一致性和实时性则更加困难(任何数据改变都必须被写入到所有实例中去)。不过,对于一次写入频繁读取的工作场景,它的表现相当优异。例如,想通过产品名字和客户姓名来查找数据库中订单,把客户和产品的所有必要信息都加进来。这样查询就非常简单,但是当改变某个产品的名字时,在规范化的关系型模型中,只需要修改该产品对应的单条记录就可以,而在反规范化的文档数据库中,将必须更新与该产品有关的所有订单。换句话说,在面向文档类型的数据库中(如ES), 对文档进行映射和存储设计只是为了优化查询和信息获取的性能。
鲁棒性:理想情况下一个耗费资源的查询应当可以被撤销,而不希望数据库停止工作。ES目前并没有很好的处理Out Of Memory 错误。所以,必须给ES配置足够多的内存,而且要谨慎运行那些无法预知将会耗费多少内存的查询。随着ES越来越成熟,在不断追求速度的目标下,这个问题会得到改善。
分布式:作为一个分布式的系统,ES的上手和使用都很简单。在一致性、可用性及分区容错性方面,ES是一个CP系统,如果有一个只读的工作负载,ES通过不严格的“最小主节点”要求(如不需要quorum)实现AP行为。写入一个配置错误的没有大量节点的集群,像“split brain”集群,可能引起无法恢复的数据丢失。事实上,在管理成百上千的集群时,常看到主节点选择问题,因此可以主动将主节点移入Zoo Keeper。在拓展性方面,索引被分到了一个或多个碎片中,这在索引创建时就指定了且不能改变。因此,随着数据的增长,应该合理的分割索引。随着越来越多的节点添加到ES集群中来,它在重新分配和移动碎片上表现良好。
安全:ES没有提供授权和认证特性,只要能连接到ES集群,就拥有了“超级用户”的权限,尤其是当ES的强大脚本功能被激活时。
04
Elasticsearch 对数据的存储
在系统中使用ES,ES会配置多个路径:
path.home:运行ES进程的用户的主目录。默认为Java系统属性user.dir,它是进程所有者的默认主目录。
path.conf:包含配置文件的目录。通常通过设置Java系统属性es.config来设置,因为在找到配置文件之前它必然会被解析。
(3)path.plugins:子文件夹为ES插件的目录。这里支持Sym-links,当从同一个可执行文件运行多个ES实例时,可用它来有选择地启用/禁用某个ES实例的一组插件。
path.logs:存储生成的日志的位置。如果其中一个卷的磁盘空间不足,则将它放在与数据目录不同的卷上可能是有意义的。
path.data:包含ES存储的数据的文件夹的路径。
由于Elasticsearch是使用Lucene来处理分片级别的索引和查询,因此,数据目录文件由ES和Lucene同时处理。两者的分工如下:
(1)Lucene负责对数据进行分词处理,以及存储与维护索引文件;
(2)ES负责编写与功能相关的元数据,例如字段映射,索引设置和其他集群元数据。
05
分析和结论
关系型数据库,适合于结构化数据存储和查询,数据查询默认返回所有满足匹配条件的记录。如果业务数据为结构化数据,同时不需要特别关注排名和智能分词模糊匹配查询等特性,采用关系型数据库并使用配套搜索引擎。传统数据的多表关联操作,在ES中处理会非常麻烦,因为传统数据库设计的初衷在于特定字段的关键词匹配查询;而ES倒排索引的设计更擅长全文检索。
ES作为NoSQL数据库代表之一,非常适合于非结构化文档类数据存储、支持智能分词匹配模糊查询。ES可以被用作其它数据库的补充,主数据库系统负责强大的数据约束保证、容错性和鲁棒性、高可用性和带事务支持的数据更新能力,它维护着核心数据,这些数据随后会被异步推送到ES中去,在与主数据库保持数据同步的前提下,使用ES 提供强大的搜索对数据进行各种搜索。
