本文来自微信公众号“数世咨询”。
2025年11月,奥地利开发者Peter Steinberger作为周末项目发布了OpenClaw第一个版本。2026年5月10日,它已经发布了第143个版本。
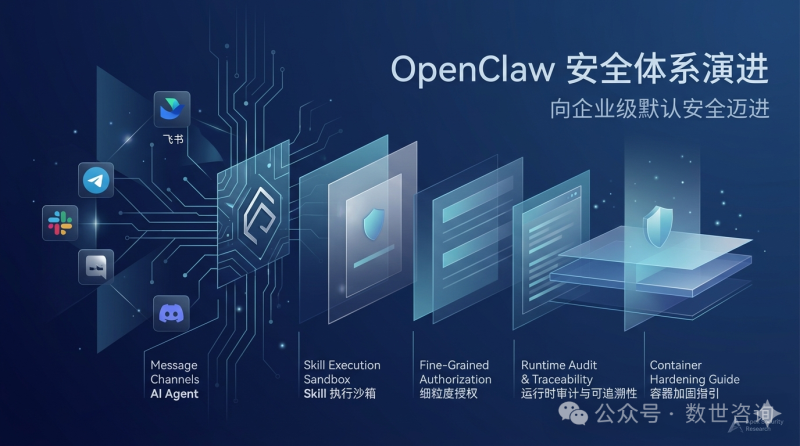
不到半年,143次更新,最后长出了一套企业级安全体系。
这个故事的真正有趣之处,不在于它有多少安全功能,而在于这些安全能力是怎么"长出来"的。不是蓝图,不是设计文档,是一次又一次被真实威胁逼到墙角后的工程选择。
不到半年的项目,143个版本。这个频率本身就说明了很多。
一、OpenClaw的安全起点:功能优先,信任链式扩展
要理解OpenClaw今天的安全体系,先要理解它的安全起点。
OpenClaw最早期的设计哲学,是典型的"功能优先"思维。一个能在20个消息渠道上跑AI Agent的网关工具,最初吸引用户的是什么?多渠道覆盖、API灵活接入、记忆和会话管理。这些能力是真实的,也是OpenClaw早期增长的核心驱动力。
但"功能优先"的另一面,是安全模型建立在隐式信任的基础上——而且,这个"早期"距离今天只有不到半年。
第一层信任:用户信任自己安装的Skill。Skill是OpenClaw的扩展机制,每一个Skill都是一个带有执行权限的代码包。早期版本中,Skill的权限边界是宽松的——安装在本地目录后,就可以访问Gateway进程范围内的几乎所有资源。一旦用户安装了一个来源可信度不高的Skill,攻击者就拥有了和Gateway同等的操作权限。
第二层信任:Gateway信任所有连接的消息渠道。OpenClaw作为消息网关,需要处理来自Telegram、Slack、Discord、飞书等不同渠道的消息。早期版本中,渠道接入的认证模型相对简单,部分渠道的allowFrom规则依赖配置而非强制执行。
第三层信任:workspace信任所有环境变量。OpenClaw的workspace目录可以存放.env文件。早期版本中,workspace下的.env文件可以注入带有OPENCLAW_*前缀的运行时控制键。
这套信任模型,在个人使用场景下不是问题。但当OpenClaw的部署量快速增长、企业用户开始评估它的生产可用性时,这套模型的脆弱性开始暴露。
关键在于,从第一个版本到第一个重大安全响应,之间只隔了不到半年。这个时间窗口比大多数安全团队的预期短得多。
二、真实威胁如何驱动安全体系"长出来"
OpenClaw安全能力的演化,不是遵循一份预定的安全路线图,而是被一系列真实发生的安全事件推动的。
第一个转折点:ClawHub恶意Skill事件
2026年初,安全研究人员发现了ClawHub(OpenClaw官方Skill市场)上的多个恶意Skill。这些Skill使用了有诱惑力的名称和描述,诱导用户安装,执行时却在后台运行恶意代码。攻击者利用了OpenClaw对Skill执行权限的宽松配置,获得了和Gateway进程同等的操作权限。
这个事件暴露了一个根本性矛盾:Skill的扩展性是OpenClaw最重要的能力之一,但这个扩展性建立在对Skill来源和行为的信任之上。一旦这个信任被打破,攻击者就可以利用Skill的高权限属性,将OpenClaw实例变成攻击跳板。
事件之后,OpenClaw在近期版本中引入了skills.install.allowUploadedArchives opt-in门控:用户必须显式允许,才能上传和安装zip格式的Skill归档文件。这是一个关键的安全范式转变——从"信任扩展"到"最小权限扩展"。配置默认关闭,而不是默认开放。
第二个转折点:容器逃逸链的公开
2026年第一季度,多个安全社区和研究人员公开了OpenClaw Docker部署环境下的容器逃逸攻击路径(最早被分配编号CNVD-2026-13380)。攻击者通过已知公开技术细节,可以在5个步骤内从Docker容器逃逸到宿主机,获取系统敏感文件并植入持久后门。整个攻击链不需要零日漏洞,是工程配置问题而非代码漏洞——这暴露出早期部署文档在生产环境安全配置指引(Hardening Guide)上的缺失。
OpenClaw官方在近期版本中强化了Docker安全相关的文档和默认配置,特别是DOCKER-USER iptables链的配置要求。这是一个典型的"被问题逼出来的安全加固"——在事件公开之前,这个配置缺陷没有在官方文档中得到明确说明。
第三个转折点:三大厂商的同期安全公告
2026年3月,CrowdStrike、Cisco和Microsoft在不到30天内,各自发布了针对OpenClaw部署的安全公告。安全行业极为罕见的同期独立公告模式——不是各自发现了不同漏洞,而是各自面对同一个体系性风险。
三份公告的核心信息相同:OpenClaw实例被攻破后,攻击者获得的不是一个小工具,而是一套覆盖整个业务运营的"管理平面"。OpenClaw作为消息网关,通常持有多个渠道的访问权限、API密钥以及对内部系统的调用能力。这个管理平面一旦被攻破,攻击者可以用它来横向移动、数据窃取和持久化驻留。
这三份公告推动OpenClaw社区对安全架构的全面重新评估。从那时起,安全更新不再只是修复具体技术漏洞,而是开始收紧默认安全边界,重新设计关键操作的权限模型。
跑马圈地:中国OpenClaw安全防护产品盘点
三、四层防护体系的生长逻辑
从真实威胁的反馈中,OpenClaw的安全架构逐渐形成了一个四层防护体系。每一层都对应着一个具体的安全问题和对应的工程响应。
第一层:身份层——从"配置可选"到"强制执行"
核心问题是:谁有权限访问OpenClaw实例,以及他们可以执行什么操作。
近期版本中,OpenClaw在身份层做了大量收紧工作。channels..allowFrom规则的强制执行,不再只是建议配置;dmPolicy和allowFrom配置别名统一化,让跨渠道访问控制策略保持一致;配对设备的可见性收紧,移动节点和桌面客户端的配对信息不再默认对所有会话可见,需要显式授权。
这些变化的共同特征是:把原来"推荐的最佳实践"变成了"不可绕过的默认"。不是安全功能的增加,而是安全默认值的迁移。
第二层:执行层——从"开放扩展"到"最小权限"
核心问题是:Skill和插件可以在OpenClaw环境中执行什么操作,它们如何获得执行权限。
before-tool-call授权钩子的引入是这个层面的关键变化。在执行任何Skill或插件工具之前,OpenClaw现在会先检查一个授权层——允许管理员定义细粒度操作策略,例如禁止某个Skill访问文件系统、禁止执行特定的系统命令、或者要求对高风险操作进行人工确认。
inline skill dispatch的权限收紧同样是重要变化。在此之前,Skill的工具分发没有显式授权检查——现在,这个过程必须经过before-tool授权钩子,任何没有明确授权的Skill操作都会被拒绝或要求确认。
第三层:数据层——从"默认明文"到"默认保护"
核心问题是:OpenClaw运行过程中产生的数据——日志、会话历史、API密钥缓存——如何得到保护。
近期版本中,日志redact机制得到了显著强化。所有日志中的auth、cookie相关头部信息,现在都会被自动检测和脱敏处理。这意味着即使用户在调试时导出了OpenClaw日志,也不会意外泄露敏感的认证凭据。
敏感payload的持久化检测同样在加强。OpenClaw明确增加了对"secret-shaped payload"的检测和redact规则——任何看起来像API密钥、Token、密码的字符串,都会在写入磁盘之前被标记和脱敏。这个能力对企业在合规审计场景下尤其重要——日志中不能出现的敏感信息,不应该依赖人工处理,而应该在系统层面被默认过滤。
第四层:可观测层——从"黑盒运行"到"透明可见"
核心问题是:当OpenClaw出现异常行为时,运维人员能否快速看清状态、定位问题、追踪影响。
cron list--json和cron show--json的机器可读输出是这个层面的典型代表。在此之前,cron任务的状态信息主要是给人阅读的格式,在需要自动化监控或系统集成时会遇到困难。现在,关键运营数据的输出格式正在向"机器可读"方向迁移,使得企业级监控和告警体系可以更好地与OpenClaw对接。
deliverySucceeded=false的显式错误报告同样是重要变化。早期版本中,当消息发送操作失败时,系统有时会返回一个模糊的成功状态——操作"完成"了,但实际的投递结果并不明确。现在,失败状态会显式报告,运维人员可以更快地发现和响应问题。
session历史血缘追踪和model failover诊断OTLP事件的导出,是在更深层次解决"黑盒运行"的问题。当OpenClaw长时间运行后出现异常,运维人员需要能够追溯:这个问题是什么时候开始的、是什么操作触发的、影响范围有多大。这些可观测性能力,解决的是企业级运营中真实存在的痛点——而不是纸面上设计出来的需求。
四、为什么说它是"长出来"而不是"建出来的"
观察OpenClaw的安全演进,一个核心区别是:它的安全能力是应对真实威胁后的工程收敛,而不是从一开始就规划好的设计蓝图。
这个区别很重要。
如果安全是"建出来的",我们可以期待它有一份完整的架构图、一份详细的设计文档、一条清晰的从A点到B点的演进路径。但OpenClaw的安全演进没有这条路径。它的每一个重要安全更新,都对应着一个真实发生的事件:ClawHub事件触发了Skill权限的门控收紧;容器逃逸公开触发了Docker安全配置的强化;三大厂商的公告触发了整个供应链信任模型的重新评估。
这不是设计,是被迫的工程选择。
但这恰恰是OpenClaw安全体系最有价值的地方。一个从真实事件中被迫收敛的安全体系,比一个设计良好的安全体系更值得信任——因为前者经历了真实威胁的验证,而后者可能还停留在纸面上。
更关键的是,这种"被迫收敛"的演进模式,在最近几个版本中正在转化为更主动的安全设计。OpenClaw开始引入一些不再是单纯响应事件的安全更新:skills.install.allowUploadedArchives的opt-in设计、before-tool-call钩子的细粒度授权模型、workspace环境的更强隔离。这些更新不再是"这个问题不能再拖了",而是开始有了前瞻性的安全边界设计。
这意味着OpenClaw的安全体系正在从"被动响应"向"主动防御"过渡。但这个过渡还没有完成——它目前处于"有能力响应"和"尚未形成预防体系"之间的状态。这不是批评,而是企业用户在评估时需要知道的真实状态。
结语
回到本文开头的问题:OpenClaw的企业级安全体系是怎么"长出来"的?
答案是:它不是规划出来的,不是设计出来的,是被真实威胁一次又一次逼到墙角后,一次又一次选择"这个问题不能再拖了"之后,工程选择逐渐收敛的结果。
143个版本背后(根据公开release记录统计),不是143次功能增加,而是143次功能与安全完善的跃迁,OpenClaw至今仍处于极高速的迭代更新中。
这个逻辑,对每一个正在部署AI Agent的企业安全团队都值得关注。AI Agent的安全边界到底在哪里?它今天解决了哪些问题?它还有哪些没有被发现的盲点?这些问题没有简单的答案,但它们值得每一个决策者认真对待。
OpenClaw用143次版本更新证明了一件事:一个工具可以在被问题追着跑的同时,一步步建立起真正的安全体系。但这个证明的代价,是每一次"不能再拖"的选择背后的真实风险。理解这个逻辑,比记住它有多少安全功能重要得多。
本文基于截至2026年5月的第143个版本(根据公开release记录统计)分析,具体配置项请参考最新版官方文档。