本文来自微信公众号“电子发烧友网”,【作者】吴子鹏。
电子发烧友网报道(文/吴子鹏)2025年中国政府工作报告提出,“持续推进‘人工智能+’行动”,并将“支持大模型广泛应用”首次写入报告。经过近几年的高速发展,大模型技术带动算力、算法、数据等基础要素全面升级,推动芯片、信息基础设施等硬科技与软件服务的协同进化,已形成技术生态闭环。同时,AI大模型正重构生产力要素,成为新质生产力发展的核心驱动引擎之一。
政策与市场需求双轮驱动下,中国AI大模型市场高速增长。根据IDC数据,2024年,中国大模型应用市场规模达到了47.9亿元人民币,预计2028年整体市场规模将达211亿元人民币。高速发展的AI大模型不仅拉动云端算力需求增长,还将在端侧广泛落地——在具身智能、人形机器人等领域,将形成“大模型+传感器+场景”的生态协同效应。
然而,在巨大的市场机遇背后,挑战亦不容忽视。典型挑战之一是:随着AI大模型部署在向更广泛、更深度、更高效方向演进,推理任务也正从集中化的云端向端侧延伸,这使得产业对高性能、低延迟、强本地处理能力的需求愈发迫切。
从云到端:AI大模型驱动计算需求升级
生成式AI的爆发式发展,推动大模型从云端集中式推理向“云-边-端”全栈部署演进。这一趋势对计算资源提出多维度严苛要求:云端需突破算力密度天花板,端侧则需追求极致能效比。
云端层面,大模型训练与推理的算力需求呈指数级增长,参数量从千亿级向万亿级跃进,训练阶段依赖万卡甚至十万卡GPU集群的分布式计算能力。云端推理成本随用户访问量也同步上升,实时响应需求加剧服务器负载。传统x86架构的数据中心面临严峻挑战,单服务器功耗、机架密度和推理成本均接近极限。
端侧层面,端侧AI通过模型剪枝、知识蒸馏等技术压缩大模型体积,以减少对云端算力的依赖,但这也使边缘端部署面临更严苛的约束,算力与能效的平衡成为核心挑战。端侧设备需适配高性能CPU、大显存显卡及高速存储模组以支持低延迟推理。当前,智能手机、车载终端等消费电子领域对计算资源的争夺已趋白热化,工业、医疗、教育等领域亦迸发出大量需求。
未来,AI大模型在端侧的增长潜力更强,其核心驱动力来自技术突破、场景需求及政策支持的三重叠加效应。与此同时,端云协同正逐渐成为行业发展的主流趋势——云端负责复杂训练与全局推理,端侧聚焦实时响应与隐私保护。企业需相应构建“云-边-端”一体化架构,通过模型压缩、硬件加速等技术突破,在智能制造、智能驾驶、智慧医疗等关键领域实现规模化应用。在这个过程中,Arm领先的计算平台凭借其高能效、高性能及灵活性优势正脱颖而出,为释放AI大模型的潜能提供强大支撑,助力大模型从云到端的高效部署与运行。
Arm技术全栈赋能AI大模型发展
面对AI大模型在云端、端侧及端云协同场景下的计算需求,Arm提供了从架构到平台、从硬件到软件的全栈解决方案。
在云端领域,早在AI时代全面到来之前,Arm Neoverse平台就凭借其卓越的高能效特性,在基础设施领域获得了广泛认可,特别是在AI推理这一对算力与能效有着严苛要求的场景中,展现出了不可比拟的独特优势。凭借出色的云端通用计算性能与能效表现,Arm Neoverse已成为云数据中心领域的事实标准。如今,Neoverse技术的部署更是达到了新的高度:2025年出货到头部超大规模云服务提供商的算力中,将有近50%是基于Arm架构。亚马逊云科技(AWS)、Google Cloud和Microsoft Azure等超大规模云服务提供商,均采用Arm Neoverse计算平台打造通用定制芯片,以优化数据中心和云计算的能源利用效率。
以AWS Graviton4 CPU为例,该处理器基于64位Arm指令集架构的Arm Neoverse V2核心设计,为各类云应用提供高效且高性能的解决方案。通过在Graviton3(C7g.16xlarge)和Graviton4(C8g.16xlarge)实例上部署Llama 3 8B模型进行性能评估,结果显示:在提示词编码环节,Graviton4性能相较Graviton3提升14%-26%;词元生成性能方面,在不同用户批次大小测试中,Graviton4在较小批次下效率提升更为显著,达5%-50%。

从Graviton3(C7g.16xlarge)到Graviton4(C8g.16xlarge)运行Llama 3 8B模型的提示词编码所实现的性能提升。图源:Arm
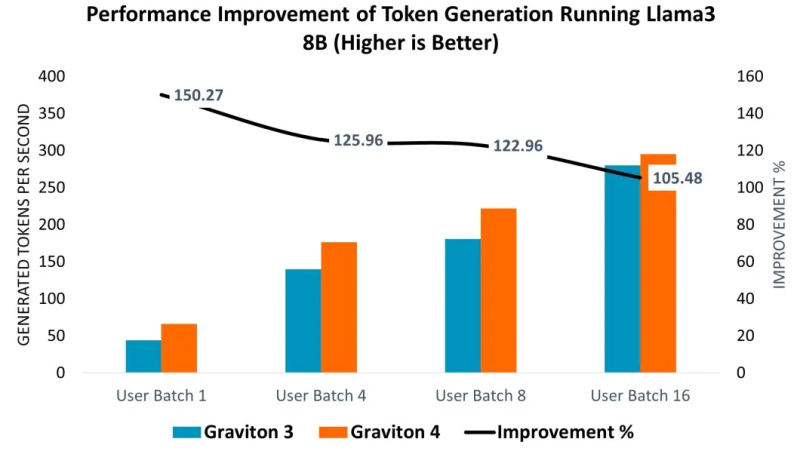
从Graviton 3(C7g.16xlarge)到Graviton 4(C8g.16xlarge)运行Llama 3 8B模型实现的词元生成性能提升。图源:Arm
在端侧领域,Arm终端CSS集成最新的Armv9.2 Cortex CPU集群、Arm Immortalis与Arm Mali GPU、CoreLink互连系统IP,以及知名代工厂基于三纳米工艺生产就绪的CPU和GPU物理实现。作为AI体验的计算基础,Arm终端CSS在消费电子设备中实现了性能、效率与可扩展性的跨越式提升。例如,Arm Cortex-X925的AI性能提升了41%,可显著增强设备端生成式AI(如LLM)的响应能力。
这里展开介绍一下Armv9架构,该架构集成了加速和保护LLM等先进生成式AI工作负载的关键特性,如可伸缩矩阵扩展(SME)和可伸缩矢量扩展(SVE2)。SME作为Armv9-A架构的指令集扩展,可加速AI/ML工作负载,为Arm CPU上运行的相关应用提供更高性能、能效与灵活性;SVE2则提升DSP任务性能,使复杂算法处理更快速高效,尤其适用于高算力需求的AI/ML场景。
在边缘AI领域,Arm今年还发布了全新边缘AI计算平台,以全新基于Armv9架构的超高能效CPU——Arm Cortex-A320及原生支持Transformer网络的Ethos-U85 AI加速器为核心,进一步助力AI大模型在端侧的落地。
在软件生态层面,Arm在2024年推出KleidiAI软件库,助力AI框架开发者在各类设备上充分发挥Arm CPU性能,支持Neon、SVE2和SME2等关键Arm架构功能。作为一套面向AI框架开发者的计算内核,KleidiAI可与PyTorch、TensorFlow、MediaPipe、Angel等热门AI框架集成,旨在加速Meta Llama 3、Phi-3、混元大模型等关键模型的性能表现,为生成式AI工作负载带来显著优化。此外,KleidiAI还具备前后兼容性,确保Arm在引入新技术的同时持续满足市场需求。目前,其支持范围已覆盖从基础设施、智能终端到物联网及汽车的全部Arm业务领域。
结语
从云端算力密度突破到端侧能效平衡,AI大模型的全面部署正重塑计算产业格局。Arm架构凭借“云-边-端”全链条技术协同优势,成为激活新质生产力的关键引擎——无论是Neoverse计算平台在数据中心打破x86架构的能效瓶颈,还是终端CSS以及边缘AI计算平台在端侧加速AI部署及应用,亦或是KleidiAI在软件生态中搭建框架与硬件的高效桥梁,Arm正以全栈式创新构建助推AI大模型发展的完整技术版图。
