本文来自极客网,作者:极客君。
最近有很多关于ChatGPT模型(例如GPT-3.5和GPT-4)的性能随着时间的推移而下降的讨论,OpenAI公开否认了这些说法,真相到底是怎样的呢?

斯坦福大学和加州大学伯克利分校(UCLA)研究人员的一项新研究提供了一些证据,证明这些大型语言模型(LLM)的行为已经具有“实质性的漂移”——但并不一定等于能力退化。
这一发现对用户在ChatGPT等黑盒人工智能系统上构建应用的风险提出了警告,即随着时间的推移,这些应用可能会产生不一致或不可预测的结果。背后原因在于:GPT等模型的训练和更新方式缺乏透明度,因此无法预测或解释其性能的变化。
用户抱怨ChatGPT性能退化
早在今年5月,就有用户就在OpenAI论坛上抱怨GPT-4很难做到它以前做得很好的事情。一些用户不仅对性能下降感到不满,而且对OpenAI缺乏响应和解释感到不满。
据《商业内幕》在7月12日报道,与之前的推理能力和其他输出相比,用户认为GPT-4变得“更懒”或“更笨”。在OpenAI没有做出回应的情况下,行业专家开始猜测或探索GPT-4性能下降的原因。
一些人认为OpenAI在API背后使用了更小的模型,以降低运行ChatGPT的成本。其他人推测,该公司正在运行一种混合专家(MOE)方法,采用几个小型的专业模型取代一个通用的LLM。
面对种种质疑,OpenAI否认了故意让GPT-4变笨的说法。OpenAI产品副总裁Peter Welinder在推特上写道:“恰恰相反:我们让每一个新版本都比之前的版本更加智能。目前的假设是:当你大量使用它时,你就会开始注意到以前没有看到的问题。”
顶级大学测试ChatGPT表现
为了验证ChatGPT的行为如何随着时间的推移而变化,斯坦福大学和UCLA的研究人员分别在2023年3月和6月测试了两个版本的GPT-3.5和GPT-4。
他们在四个常见的基准任务上评估了这些模型:数学问题、回答敏感问题、代码生成和视觉推理。这些是评估LLM经常使用的多样化任务,而且它们相对客观,因此易于评估。
研究人员使用了两组指标来评估这两个模型的性能。主要的指标特定于任务(例如,数学的准确性以及编码的直接执行)。他们还跟踪了冗长度(输出的长度)和重叠度(两个LLM版本的答案之间的相似程度)。

3-6月ChatGPT表现确实在下滑
对于数学问题,研究人员使用了“思维链”提示,通常用于激发LLM的推理能力。他们的发现显示了模型性能的显著变化:从3月到6月,GPT-4的准确率从97.6%下降到2.4%,而其响应冗长度下降了90%以上。GPT-3.5表现出相反的趋势,准确率从7.4%上升到86.8%,冗长度增加了40%。
研究人员指出,“这一有趣的现象表明,由于LLM的性能漂移,采用相同的提示方法,即使是那些被广泛采用的方法(例如思维链),也可能导致显著不同的性能。”
在回答敏感问题时,对LLM进行评估的标准是它们回答有争议问题的频率。从3月到6月,GPT-4的直接回答率从21%下降到5%,这表明这个模型变得更加保守。与此同时,GPT-3.5的直接回答率从2%上升到8%。与3月的版本相比,这两种模型在6月份拒绝不恰当的问题时提供的解释也更少。
研究人员写道:“这些LLM服务可能变得更加保守,但也减少了拒绝回答某些问题的理由。”
在代码生成过程中,研究人员通过将LLM的输出提交给运行和评估代码的在线裁判来测试它们是否可直接执行。结果发现,在3月,5 0%以上的GPT-4输出是可直接执行的,但在6月只有10%。对于ChatGPT 3.5,可执行输出从3月的22%下降到6月的2%。6月的版本经常在代码片段周围添加不可执行的序列。
研究人员警告说:“当LLM生成的代码在更大的软件管道中使用时,要确定这一点尤其具有挑战性。”
对于视觉推理,研究人员对来自抽象推理语料库(ARC)数据集的示例子集的模型进行了评估。ARC是一个视觉谜题的集合,用于测试模型推断抽象规则的能力。他们注意到GPT-4和GPT-3.5的性能都有轻微的改善。但总体性能仍然较低,GPT-4为27.4%,GPT-3.5为12.2%。然而,6月版本的GPT-4在3月正确回答的一些问题上出现了错误。
研究人员写道:“这凸显了细粒度漂移监测的必要性,特别是在关键应用中。”
ChatGPT性能退化可能存在误解
在这篇论文发表之后,普林斯顿大学的计算机科学家、教授Arvind Narayanan和计算机科学家Sayash Kapoor认为,一些媒体误解了这一论文的结果,他们认为GPT-4已经变得更糟。
两人在一篇文章中指出,“不幸的是,这是媒体对于论文结果的过度简化。虽然研究结果很有趣,但其中一些方法值得怀疑。”
例如,评估中使用的所有500个数学问题都是“数字X是质数吗?”而数据集中的所有的数字都是质数。3月版本的GPT-4几乎总是猜测这个数是质数,而6月的版本几乎总是猜测它是合数。
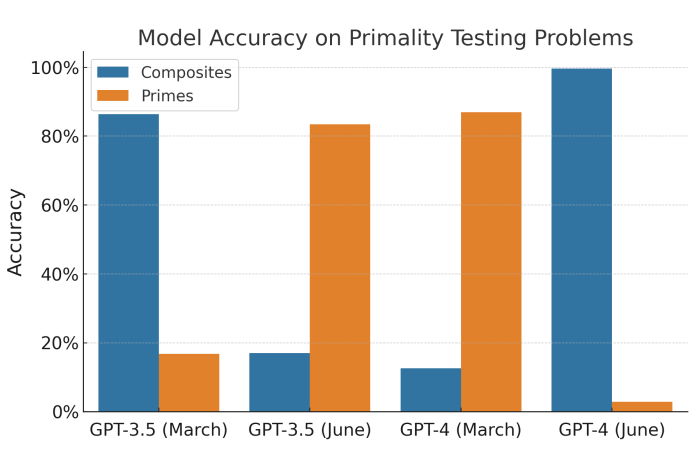
Narayanan和Kapoor在文中写道:“论文的作者将这种情况解释为性能的大幅下降,因为他们只测试了质数。当GPT-4在500个合数进行测试时,这种性能的下降就消失了。”
总而言之,Narayanan和Kapoor认为,ChatGPT的行为会改变,但这并不一定意味着它的能力下降了。
ChatGPT类AI应用还能信任吗?
虽然这篇论文的发现并不一定表明这些模型变得更糟,但确实证实了它们的行为已经改变。
研究人员据此得出结论,GPT-3.5和GPT-4行为的变化凸显了持续评估和评估LLM在生产应用中的行为的必要性。当我们构建使用LLM作为组件的软件系统时,需要开发新的开发实践和工作流程来确保可靠性和责任。
通过公共API使用LLM需要新的软件开发实践和工作流程。对于使用LLM服务作为其持续工作流程组成部分的用户和公司,研究人员建议他们应该实施持续的监控分析。
这一研究结果还强调,在训练和调整LLM的数据和方法方面需要提高透明度。如果没有这样的透明性,在它们之上构建稳定的应用就会变得非常困难。
