本文来自微信公众号“twt企业IT社区”,作者/白鳝,南京基石数据技术有限责任公司技术总监,在软件开发、系统运维、信息系统优化、信息系统国产化替代等领域从事技术研究近30年,曾主持开发了国内首套电信级联机实时计费系统、国内首套三检合一的检验检疫管理系统、银行综合大前置平台(IPP)等大型系统。著有《Oracle RAC日记》、《Oracle DBA优化日记》和《DBA的思想天空》等技术专著。信息无障碍研究会专职顾问,深圳市鲲鹏产业联盟高级顾问,Oracle ACE,POSTGRESQL ACE DIRECTOR。个人微信公众号:白鳝的洞穴
现在PG数据库在用户侧的应用场景日益丰富,很多国产数据库也与PG开源项目有着很深的渊源,在使用过程中的一些基本运维规则也与PG开源数据库十分近似。今天我们从操作系统的角度来看一看PG数据库日常运维中需要关注的一些问题。
目前大多数用户侧的PG数据库规模都比较小,应用系统也都不太复杂,因此大多数情况下,数据库日常运维的难度并不大,不像Oracle这样复杂的数据库系统,遇到些问题还不太容易处理。在PG数据库日常运维上,只要关注下总会话数,活跃会化,并发访问,TOP SQL,一般也就够用了。反而在操作系统层面,需要多加关注。
在这种情况下,操作系统的各种资源是否充足是决定数据库运行是否稳定的十分重要的因素。CPU、内存、IO、存储容量这四种资源是否充足决定了PG数据库的运行是否稳定。网络是否存在丢包、延时过大的问题,则会影响SQL语句执行的效率。一般情况下对这些多做关注,基本上就没有太大的问题了。
对于CPU资源,首先要观察在业务高峰期,r队列的数量长时间超过CPU线程数,甚至超过2倍。如果业务高峰期操作系统r队列的长度经常长时间(超过10分钟)超过CPU线程数,那么说明当前CPU资源在系统高峰期存在不足的问题,如果经常超过2倍,那么久应该准备扩容了。
对于内存资源,我们需要关注的是可用内存和交换器使用率这两个指标,因为OS内存中很多内存是用于CACHE/BUFFER的,所以空闲内存的指标指示性不够准确,使用可用内存可能更为准确一些,这个指标是说操作系统中还有多少真正可用于分配的内存。
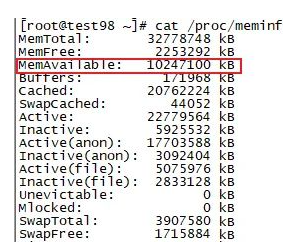
MemAvailable指标的含义是当前内存中还可用于分配的所有内存的总和。如果这个值比较小了,说明当前的OS中可以用于分配的内存过小,系统存在隐患。
另外一个需要关注的指标是SWAP使用率,有些PG的使用攻略中甚至建议大家关闭SWAP,从而避免因为SWAP带来的性能不稳定。这种建议实际上是因为无法控制SWAP,以及控制SWAP带来的负面影响而采用的一种极端的措施。在当前的LINUX内核下,SWAP产生的原因十分复杂,因此干脆通过关闭SWAP来避开SWAP了。这种做法实际上是不可取的,因为你都没办法搞明白SWAP产生的原因,那么如果关闭了SWAP,一旦SWAP需要产生的时候,那么OS会采取更为极端的方式来对待,那就是OOM KILLER进程杀掉某些进程。如果正好Postmaster正好是那个倒霉蛋,那么就不是PG性能受到影响了,而是PG库就宕了。目前我们常用的Linux 7、8核心的swap算法已经都比较完善了,大多数情况下,SWAP不会对影响PG数据库性能比较严重的匿名块做SWAP,而会尽可能交换CACHE/BUFFER,因此只要基础的LINUX VM参数设置的比较合理,就无需惧怕SWAP的产生。而当系统的SWAP使用率一直居高不下(比如超过90%),才需要重点关注。
IO延时也是我们运维PG数据库时需要关注的,因为PG数据库的DOUBLE BUFFER特性,实际上IO延时对PG数据库的影响并不一定像对Oracle那么直接。有时候IO延时挺高了,但是PG数据库的性能似乎受到的影响还不算大。不过不管怎么样,IO延时低于20毫秒是运维PG数据库的一个基本底线。过高的IO延时肯定会对PG数据库长期稳定运行存在隐患(当PG数据库负载较小的时候,这种影响还不一定会体现出来)。在一个相对稳定的运行环境中,如果IO总量变化不大的时候,IO延时应该也是相对稳定的,如果IO总量不变的情况下,IO延时越来越长,那么说明底层IO设备或者后端存储存在问题,我们需要尽早关注,以免出现大问题。存储子系统的问题,对于数据库来说往往是致命的。
另外一个容易受到忽视,但是一旦出现问题就容易引发大问题的是操作系统层面的进程的状态。如果进程中出现了几类特殊的非正常进程,那么我们就需要加以关注了。如果这些进程属于postgres用户,那么就需要额外关注了。一般进程状态有r(运行或可允许),S(可中断的休眠状态),这两种状态的进程都是正常的。而处于D(不可中断的休眠状态)的进程往往是在等待IO完成等内核调用,这个状态如果短时存在,并且很快消失了,那很可能是IO性能存在问题,并不危险,如果系统中经常有大量进程处于D状态,那么就需要关注了,是不是OS在IO层面存在问题了。而且随着D状态的进程数量愈来愈多,OS的风险也越来越大,服务器从长远看,存在比较大的风险。另外T状态的进程也应该是一个临时状态,等进程归还资源后应该就立即被关闭了,如果有进程长期处于T状态,那么系统肯定存在某些风险,需要关注。同理是Z状态的进程(僵死)。关注OS中的这些非正常状态的进程的数量变化以及某个非正常状态的进程是否长期处于该状态,是我们PG DBA运维数据库系统时应该关注的。
OS层面需要关注的内容还有很多,比如通过lsof看看打开文件句柄的总数是否存在不合理的增长,ulimit参数的限制是否会出现风险,OS进程数量是否异常,dmesg和messages是否存在异常报错等,都是PG DBA需要经常去检查检查的。这些检查十分琐碎,有些也过于专业。因此PG DBA也需要构建一些工具,定期自动的去做巡检,从而确保数据库所运行的OS环境是安全的。
