本文来自微信公众号“半导体产业纵横(ID:ICVIEWS)”,编译自idtechex。
2025年,GPU的部署量将呈指数级增长。
人工智能数据中心和云计算需要世界各国大力投资。“自主人工智能”一词在各国纷纷建设自主人工智能基础设施的过程中变得日益流行,人工智能数据中心甚至被称为“人工智能工厂”。随着这些数据中心的日益普及,其所需的加速计算芯片在当今市场上炙手可热。这些芯片包括先进的CPU、GPU、ASIC以及新兴的人工智能芯片技术。
IDTechEx估计,GPU(图形处理器)将在2024年占据AI芯片总收入的82%,而到2025年,GPU的部署量将呈指数级增长。这主要由科技巨头NVIDIA引领,该公司于2024年推出了最新的Blackwell GPU,并在2025年全年加大了部署力度。然而,AMD目前凭借其MI300和最新的MI350系列,是数据中心GPU市场的有力竞争者,这些系列也赢得了大规模GPU集群的大量出货订单。主要买家仍然是美国超大规模计算平台AWS、微软、Meta和甲骨文。
NVIDIA在2025年5月告诉投资者,主要的超大规模提供商每周都会部署近1,000个NVL72机架(72,000个)Blackwell GPU,据报道,保守估计2025年Blackwell GPU(GB200)的出货量将达到250万个。AMD的MI350系列出货量不断增长,并将于2025年6月开始量产。AMD最大的交易之一是与Humane进行数十亿美元的合作,以构建完全基于AMD CPU、GPU和软件的AI基础设施,同时还与Oracle达成了多达130,000个MI355X GPU的交易。
GPU最初是图形处理器,现在是训练AI的支柱
自20世纪70年代以来,图形处理单元(GPU)就一直用于图形渲染和计算。IBM和Itari是首批芯片设计公司之一,他们开发了用于个人电脑和街机的图形硬件,用于处理简单的2D渲染操作。20世纪90年代迎来了技术的新一轮繁荣,3D图形技术逐渐受到青睐。
进入21世纪,GPU开始用于科学计算,例如模拟和图像处理,并使用专门为充分利用并行处理能力而创建的软件库。21世纪末,NVIDIA发布了CUDA,AMD发布了Stream SDK(现为ROCm),这在学术界之外得到了广泛应用。这至关重要地允许开发人员将GPU用于通用计算,而不仅仅是图形处理。
2010年代初,人们对人工智能的兴趣开始普及,当时出现了一些著名的人工智能模型,如AlexNet、ResNet和Transformers,它们都展示了深度学习和自然语言处理能力。这些模型针对NVIDIA GPU进行了优化,并利用了NVIDIA的库和框架。这些模型使用GPU,为各种人工智能任务设定了新的性能基准。现在,GPU因其执行大规模并行处理、达到高数据吞吐量以及支持高级库(例如cuBLAS和cuDNN)的能力而被广泛使用,这些库为线性代数和深度学习提供了高性能例程。这正是训练当今最大型人工智能模型所需要的,包括OpenAI的ChatGPT、Anthropic的Claude或Google的Gemini等。
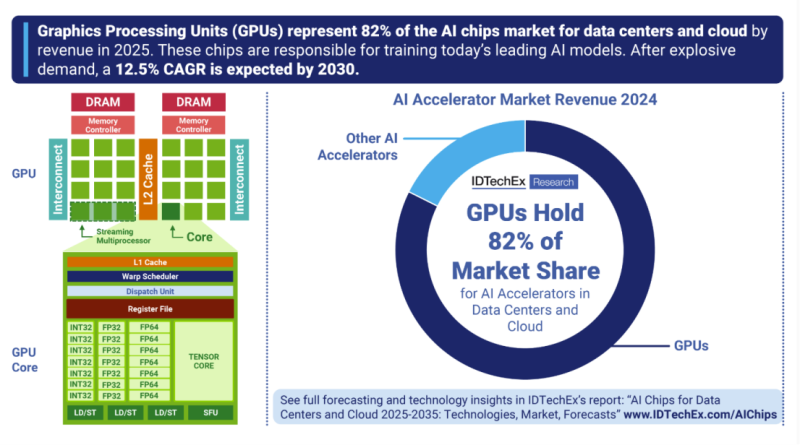
GPU的技术基础
GPU(图形处理单元)由数千个并行执行指令的核心组成。每个核心都经过优化,可同时在多个数据点执行同一条指令,这被称为SIMD(单指令多数据)。每个核心都比CPU中的内核简单得多。
与CPU相比,GPU的缓存系统略逊一筹,但它们拥有更多专用于计算的晶体管,因此可以牺牲延迟优化来获得高吞吐量。这种架构使GPU能够以更快的吞吐量和更高的效率执行需要矩阵乘法和并行计算的任务。
每个GPU核心都能够以特定数据格式执行不同精度的计算(例如,FP32精度较高,而FP4精度较低),这使得它们适用于各种AI工作负载。事实上,这些数据中心GPU拥有称为张量核心的特定核心,这些核心专为神经网络训练和推理所需的矩阵乘法而设计。
低精度、混合精度和专用数据格式是当今高端GPU的基础。低精度尤其有利于快速AI推理:NVIDIA已将低精度精度降至FP4,AMD也宣布其MI355X处理器兼容FP4。
对于GPU设计师来说,拥有能够有效利用这些核心的软件是一个关键障碍,而这正是市场领导者具有优势的地方,尤其是在拥有庞大的开发者社区的情况下。
数据中心GPU的关键技术趋势和挑战
高性能GPU持续采用更先进的晶体管,2nm和18A节点将于2026年起发布。这些先进节点通过提高晶体管密度来提升GPU的性能。然而,这些先进节点需要ASML的高数值孔径EUV(极紫外)光刻设备,每台设备的成本将高达7.8亿美元。
其他挑战包括低良率、高发热量、高研发成本以及材料挑战。追求更小节点的经济价值越来越不明确,投资的合理性也越来越难以证明。
许多厂商正在增加硅片的总面积,这意味着增加芯片中的晶体管数量。关键技术策略包括将芯片拼接在一起(例如,NVIDIA的Blackwell GPU和Cerebras的非GPU晶圆级引擎),以及采用3D堆叠的chiplet技术。chiplet技术可以提高良率,但可能会降低内存带宽。
先进封装至关重要。NVIDIA和AMD使用台积电的2.5D CoWoS封装。台积电的CoWoS封装已达到产能上限,这意味着其他代工厂可能会使用类似技术来满足需求。AMD也面临同样的问题,日月光(ASE)、安靠(Amkor)、力成(Powertech)和京元电子(KYEC)等公司都可能是AMD的潜在合作伙伴,为其提供替代的先进封装技术。
高带宽内存(HBM)已得到广泛采用,用于提供大型AI模型所需的内存。HBM主要由三星、SK海力士和美光三大厂商提供,目前这些厂商的顶级GPU已开始采用HBM3e。HBM4预计将于2025年下半年实现量产(SK海力士)。

AI芯片市场持续发展,尽管GPU仍占据主导地位,但也面临挑战。其他AI芯片包括超大规模厂商开发的定制ASIC(专用集成电路),以及各家初创公司利用新兴芯片技术开发的GPU替代方案。
