本文来自微信公众号“半导体产业纵横”,【作者】鹏程。
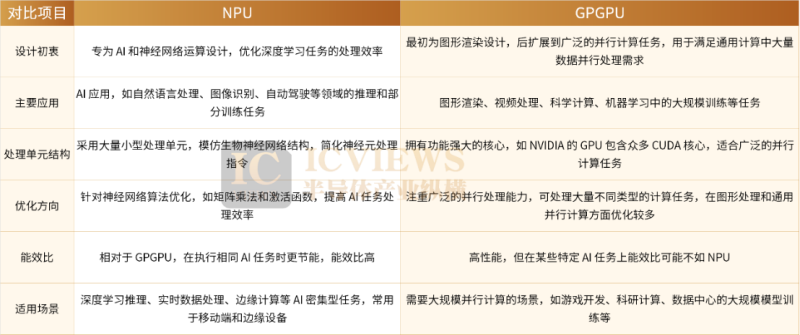
NPU(Neural network Processing Unit,神经网络处理器)是专为人工智能计算设计的专用芯片,核心优势在于高效执行神经网络相关运算(如矩阵乘法、卷积操作、激活函数计算等)。相较于传统CPU与GPU,NPU在能效比和运算速度上表现更优,尤其适配移动设备、边缘计算及嵌入式AI等场景。
近年来,NPU也被尝试应用于AI大模型的训练与推理领域,市面上不少产品采用NPU架构为AI网络推理提供硬件支持。企业对NPU的青睐,核心原因在于其芯片设计具备可控性与可靠性。然而,随着AI技术的演进,NPU的局限性逐渐显现,而GPGPU(General-Purpose computing on Graphics Processing Units,通用图形处理器)却被认为是更适配未来需求的解决方案。近期甚至有消息称,国内某厂商正重构其AI芯片,将由NPU转向GPGPU。
01
NPU和GPGPU的区别
GPU最初为加速图形渲染而生,专注于处理计算机图形学中的并行任务——如顶点变换、光照计算、纹理映射等。随着技术演进,其强大的并行计算能力推动其向通用计算领域延伸,形成了GPGPU,广泛应用于科学计算、深度学习训练、视频编解码等场景。
NPU则是为人工智能(AI)与机器学习(ML)任务量身设计的专用芯片,尤其针对深度学习中的神经网络推理与训练。其架构深度优化了矩阵运算、卷积操作及激活函数(如ReLU、Softmax、Pooling)等核心任务,通过大规模乘加器(MAC)阵列高效执行矩阵乘法与卷积运算;同时优化数据流传输,减少存储器与计算单元间的数据交互开销,大幅提升能效比。不过,NPU的指令集与硬件设计高度专用化,仅适配特定神经网络模型,对其他任务支持有限;且其生态系统较新,需依赖芯片厂商提供的专用SDK与工具链(如华为达芬奇架构、谷歌Edge TPU工具链),开发者需针对特定架构优化,灵活性较低但部署效率高。
从架构核心差异来看,GPGPU采用SIMT((Single Instruction Multiple Threads,单指令多线程)前端(本质是封装了SIMT前端的SIMD),通过通用调度机制与友好的编程接口,实现了“开箱即用”的高性能;而NPU/TPU仍沿用传统SIMD(单指令多数据)架构,需手动编排流水线,时延隐藏效率远不及SIMT,导致编写高性能内核难度大、效率低,既难以实现易用性,生态完善程度也远落后于GPGPU。(SIMT是GPU架构中的核心并行计算模型,通过单一指令流驱动多线程并行执行,每个线程处理独立数据集。其核心机制是将线程按32线程组成线程束,通过锁步执行与动态掩码控制实现分支逻辑处理)
因此近年来,一些NPU芯片开始引入SIMT前端(整体仍偏向异构流水线)。此外,GPGPU虽控制单元很孱弱,但这些控制单元仍具备针对并行计算的优化设计——如硬件线程切换、访存控制、延迟隐藏等;而NPU几乎无控制单元,若按传统硬件分类,称其为“处理器(PU)”稍显牵强,更适合定义为“计算器/协处理器”。
若按传统“处理器-协处理器”体系结构框架分析,两者的定位可总结为:NPU的典型架构是“CPU+NPU”;而GPGPU则为“CPU+GPU+DSA(领域专用架构)”,以NVIDIA的实现为例,即“CPU+CUDA Core+Tensor Core”。需注意的是,这里的GPU与DSA并非平行的协处理器,而是形成“CPU控制GPU,GPU再控制DSA”的层级关系。
02
为什么需要GPGPU?
那么,为何需要GPU来控制领域专用架构(DSA)?或者更根本地说,GPU为何需要控制单元?
实际上早期的显卡,和今天的NPU除了任务不同之外,结构都差不多。但与浮点协处理器逐步集成到CPU、最终成为CPU一部分的路径不同,显卡从诞生起便是独立存在的。总线物理距离的限制,使得CPU对显卡的控制难以实现实时性;而随着任务复杂度的提升,将部分实时控制逻辑集成到显卡内部,便成了必然选择——这正是硬件设计中经典的“控制转移”策略。英伟达不仅内置了这类控制单元,更创新性地抽象出SIMT编程模型,这一突破堪称并行计算领域的里程碑。
而从近年来的AI芯片领域的实践经验来看,随着任务日趋复杂多变,控制单元的“膨胀”已成客观趋势——唯有强大的控制单元,才能适配不断变化的应用场景。尽管SIMT已非AI芯片的最优编程模型,但AI计算本质上仍属于并行计算范畴,必然会面临并行计算的共性问题。此时人们才发现,英伟达GPU的设计看似只是在原有架构上“打了个张量计算核心的补丁”,缺乏颠覆性创新,但其实际应用效果却远超预期,暗藏诸多可取之处。
GPGPU的重要性,根源在于研究人员无法预判未来5-10年AI技术的演进路径。若选择NPU,则需将适配压力完全转移到软件层面——尽管这类硬件设计可能是特定阶段的最优解,但副作用不容忽视。也正因如此,从训练场景的需求出发,下一代NPU引入SIMT前端,其实是顺理成章的选择。
客观而言,NPU在推理场景中表现尚可,是个不错的选项;但在训练场景中,其路径却异常艰难——难度至少比推理高一个数量级。即便NPU在性能功耗比上更具优势,也未能在实际表现中形成对GPU的碾压性突破;更何况云端场景对功耗的敏感度本就有限。
而在NPU实际落地中,还存在以下问题:
其一,易用性落后于GPU。正如PyTorch凭借易用性与开发体验击败静态图特性更利于性能优化的TensorFlow,实际上开发者对工具链的友好度感知尤为敏锐,更在乎易用性和体验。具体来看,NPU受限于简单的地址控制模块,仅能处理不同指令对相同地址的访问阻塞,缺乏SIMT架构中针对线程的延迟隐藏机制;若要让算子在NPU上充分释放性能,开发者必须深入理解其多级内存机制,设计针对性的切分方案——但L1级内存块受限于容量与存储体冲突问题,切分粒度极难把控,进一步加剧了使用门槛。再者NPU这样的DSA还未经残酷的收敛环节。目前做NPU芯片每家的架构隔代改动都很大,更别说不同公司提供的NPU架构则差异更大。
其二,生态壁垒高。国产GPU如果直接兼容CUDA生态,算子与推理引擎框架无需重写,仅需重新编译即可复用,大幅降低了迁移成本;而若投入NPU,软件侧则需付出巨大代价——开发者往往需要持续高强度加班以适配算子、优化性能、搭建深度学习引擎框架。除字节等少数具备雄厚实力的企业(甚至需要芯片厂商驻场支持),多数企业难以承担这样的成本。对客户而言,若没有“完全买不到GPU”的压力,显然不会选择在NPU上投入远超GPU的时间与精力。
其三,开发难度大且封闭性强,制约下游开发者的成长。在GPU生态中,开发者可自主开发算子、进行性能优化,且门槛相对较低;但在NPU体系下,除少数大厂外,多数开发者只能依赖厂商提供的SDK与解决方案,难以自主开展深度优化。
03
国内NPU企业或将引入SIMT前端,转向GPGPU路线
GPGPU的SIMT模型,其设计初衷是为高效处理大规模并行且数据密集型任务而生,在图形渲染与科学计算领域尤为适用。该模型允许一组线程(即一个warp)同步执行相同指令,同时每个线程可独立操作不同数据——这种特性使其在处理包含大量同质化操作的数据集时效率显著。对于复杂任务,尤其是那些可高度并行化、数据关联性低且分支行为趋同的场景,SIMT模型的优势更为突出。
从硬件特性来看,NPU确实具备诸多可取之处。这也解释了为何近年来GPGPU上的张量计算核心数量持续增加,甚至成为衡量性能的核心指标。可以说,NPU是为AI诞生的架构,但相比GPU诞生时的环境,以NPU为代表的领域专用架构(DSA)的成长之路更为坎坷:一方面要面对自身架构尚未成熟的阵痛,另一方面还要承受GPU对其技术特性的吸收与市场围剿,发展难度不言而喻。
针对大语言模型(LLM)这类场景——既包含大量矩阵乘法(GEMM)计算,又需持续响应新需求——若想降低软件开发门槛,要么采用SIMT模型,要么依赖乱序执行与数据预取机制。NPU的架构设计受限于当时的技术视野,难以预判未来趋势,因此很难简单判定早期选择NPU路线是战略失误。而SIMT+张量计算核心的技术路线,因能保持与CUDA的API及源代码兼容,成为当前英伟达竞争对手的主流选择,其优势不言而喻。
国内众多企业的NPU发展始于端侧场景,早期更侧重功耗优化,且当时AI算法种类有限;同时,NPU架构对带宽的敏感度较低,理论上可缓解HBM(高带宽存储器)相关的关键问题。但关键在于,这些AI芯片企业在早期并未完全预见AI大模型的爆发式增长——诸多因素叠加,导致早期架构设计方向与后期激增的AI算力需求出现了适配偏差。国内AI芯片领域存在一个核心问题:决策层对可编程性与通用性的重视不足。过多资源投入到特定场景的优化中,虽能在宣传数据上呈现亮眼表现,但一旦拓展至更广泛的应用场景,其平均性能便显得平庸。
回归本质,GPGPU与SIMT编程模型的核心逻辑,在于在保证芯片图灵完备性的基础上,满足大规模并行计算需求。而DSA的问题恰恰在于对易用性的忽视,如今不得不回头补课。值得关注的是,随着GPU引入张量核心与DMA(直接内存访问)机制,其原生SIMT模型已有所突破;而NPU也在逐步强化控制能力——两者在技术演进中呈现出“双向奔赴”的融合趋势。
不过,如今又消息称,后续国内企业也将在NPU中加入SIMT前端,逐渐补齐通用调度和编程易用方面的短板。
