本文来自微信公众号“ruby的数据漫谈”,作者/ruby。
随着湖仓一体技术架构的兴起,湖仓一体可以结合数据湖和数据仓库的优势,将会成为数据库行业的未来趋势,但是由于湖仓一体可以完成数据的统一存储和加工计算,可以为企业提供面向应用的统一供给,但是由于很多企业已经有数据仓库和数据库系统,湖仓一体技术架构无法解决架构升级带来的数据迁移的巨大成本,且部分数据仓库系统仍然可以发挥作用,因此,湖仓一体必须支持多种数据入湖的方式,兼顾成本和功能的作用。
01
数据入湖的方式
数据入湖的方式有多种,以下是一些常见的方式:
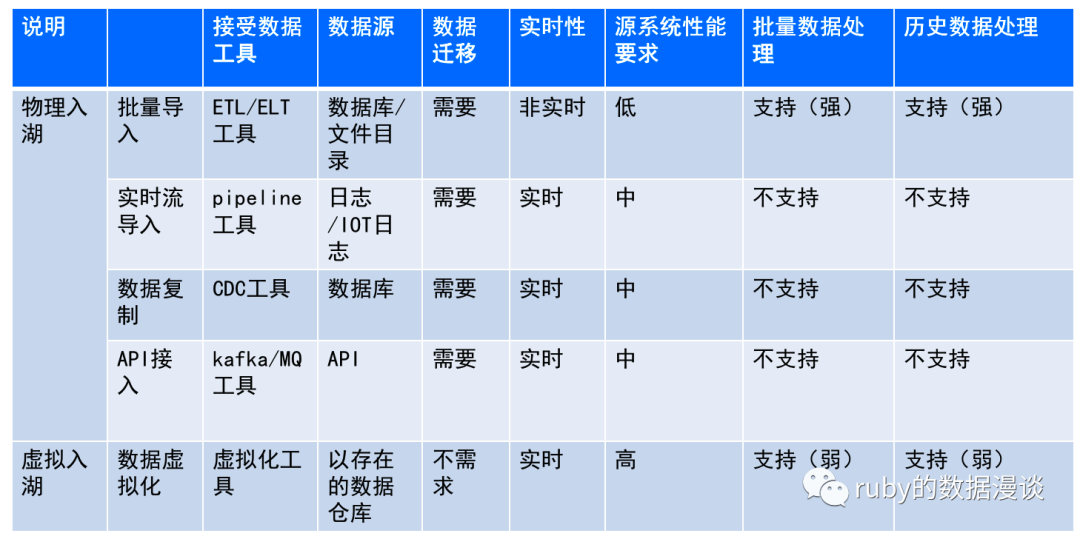
1.批量导入:将数据从现有的数据源中以批处理的方式导入数据湖中,可以使用ETL(Extract,Transform,Load)工具或编写脚本来完成。
应用场景:对于需要进行复杂数据清理和转换且数据量较大的场景,批量集成是首选。通常,调度作业每小时或每天执行,主要包含ETL、ELT和FTP等工具。批量集成不适合低数据延迟和高灵活性的场景。
2.实时流式导入:将数据以流的方式持续导入数据湖中,可以利用流处理引擎如Kafka、Flume、Spark Streaming等来实现。
应用场景:主要关注流数据的采集和处理,满足数据实时集成需求,处理每秒数万甚至数十万个事件流,有时甚至数以百万计的事件流。流集成不适合需要复杂数据清理和转换的场景。
3.数据复制:将数据从现有的数据库或数据仓库中复制到数据湖,可以使用复制工具或者数据湖服务来完成。使用基于日志的CDC捕获数据变更,实时获取数据。
应用场景:数据复制同步不适合处理各种数据结构以及需要清理和转换复杂数据的场景。
4.API接入:通过数据湖平台提供的API接口将数据直接导入数据湖中。
应用场景:通常通过API捕获或提取数据,适用于处理不同数据结构以及需要高可靠性和复杂转换的场景。尤其对于许多遗留系统、ERP和SaaS来说,消息集成是唯一的选择。消息集成不适合处理大量数据的场景。
5.数据虚拟化:数据入湖中的数据虚拟化是指在数据湖中使用虚拟化技术,将数据源的数据映射到数据湖中,而不需要复制或移动实际的数据。数据虚拟化通过创建虚拟视图来实现,它们是对实际数据源的查询和访问,但并不实际复制或移动数据。虚拟化技术提供了一个统一的数据访问接口,将不同数据源的数据视为一体,屏蔽了数据源背后的细节,使得用户可以方便地查询和分析数据。数据虚拟化产品的架构一般有两种实现方式,联邦查询和实时镜像。
其中数据虚拟化是不需要将数据复制到数据湖中,而是提供一个数据共享访问层实现数据的访问。这样避免了大量的数据复制工作,实时镜像还是有部分存储成本。
02
数据入湖方式的对比
不同入湖方式的实时性和对源系统的性能要求不同,以下是对照表:
03
非结构化数据入湖特殊说明
非结构化数据包括无格式的文本、各类格式的文档、图像、音频、视频等多样异构的格式文件。那么非结构化数据入湖在以上的5种入湖方式上需要进行特殊说明:
一、非结构化数据的元数据包含基本信息和内容增强类,具体可以参考都柏林核心元数据标准。非结构化数据的元数据包含基本信息主要包含名称、格式、存储大小、Owner、存储位置、创建时间、修改时间等基本特征。而增强内容特征主要包含标签、相似性检索、相似性连接等。
二、而非结构化数据入湖则可以包含元数据入湖和原始文件入湖两种类型,原始文件如何入湖可以参见以上的4种入湖方式,而元数据入湖主要包含3种类型:
1、基本特征元数据入湖:主要通过从源端集成的文档本身的基本信息入湖。入湖的过程中,数据内容仍存储在源系统,数据湖中仅存储非结构化数据的基本特征元数据。
2、文件解析内容入湖:对数据源的文件内容进行文本解析、拆分后入湖。入湖的过程中,原始文件仍存储在源系统,数据湖中仅存储解析后的内容增强元数据。
3、文件关系入湖:根据知识图谱等应用案例在源端提取的文件上下文关系入湖。入湖的过程中,原始文件仍存储在源系统,数据湖中仅存储文件的关系等内容增强元数据。
其中1是非结构化数据的基本信息,2和3是非结构化数据的增强内容特征,而这三种方式的原始数据依然存储在原始的存储系统中。
总结一下,通过数据虚拟化和非结构化数据的基本信息和内容增强内容入湖的方式可以减少湖仓一体新的技术架构建设过程中造成大量的数据迁移的成本。也可以实现湖仓一体的数据统一管理和处理。
