
超算是国之重器,体现了一个国家的科技发展水平。过去很长一段时间,超算以算为主,通过TOP500打榜,彰显国家的超算实力。
截止2021年6月,中国在TOP500中超级计算机数量达到188台,远超美国的122台。神威太湖之光,接力天河2号、天河3号连续10次夺得世界第一,中国已经成为事实上的超算大国。
但是,近年来,随着互联网的兴起,新的技术热点层出不穷,大数据、人工智能、区块链等降低了社会对于超算技术的关注度。同时登顶世界后,超算产业进入“无人区”,从跟随者转身为引领者的不适应,以及面对新的技术趋势的消化不良,导致近年来超算届逐步形成了五个典型的认知误区。这五个误区直接影响到了超算产业的发展,直接制约到了中国从超算大国走向超算强国的进程。
误区1:超算是传统算力,智算是先进算力,两者是竞争关系?
真相1:这一误区的来源是AI算力的兴起,以及AI背后的一系列应用的发展,如图像识别、语音识别、自动驾驶等,智算和超算开始并驾齐驱。但是,应该了解到的是,长期以来,AI的算力一直作为超算算力的补充存在,首先超算的算力异构化趋势由来已久,通过GPU加速来补充CPU算力的不足,尤其是在大规模矩阵运算的不足,国内的天河系统和神威系统早已具备CPU+GPU异构算力,全球Top20能效的超算70%使用了异构算力,Top50的超算应用,68%支持GPU加速。其次,近年来,有一些科学应用被证明可以通过机器学习而不是传统的偏微分方程的算法来进行模拟,如2020年获得戈登贝尔奖的北大分子动力学场景,尝试通过机器学习的方式来进行计算模拟,取得了和传统偏微分方程模拟的类似效果,这就是AI技术对于传统超算算法的一直替代。第三,也是最重要的,今年超算产业联盟年会,新当选的联盟理事长郑纬民院士从整个超算产业的视角提出,大计算与大数据相伴,HPDA,即HPC+AI+Bigdata的技术融合,从关注单点应用的HPC,走向支持复杂应用的全流程计算HPDA是未来的发展方向。
误区2:超算就是计算,数据不重要?
真相2:传统超算的商业模式就是依靠算力来变现,机时是衡量超算中心经营的唯一标准,这种模式最大的问题是超算中心完全管道化,不能和客户的应用产生粘性,超算中心之间的竞争退变为电费的竞争,无法分享企业数字化大潮的红利。不过,伴随着HPDA的发展,越来越多的新增业务场景都为数据密集型应用,不少超算中心逐步转型为数据服务提供商,关注数据价值变现。以济南国超为例,着重关注数据的积累,打通了医疗数据、健康数据、安全数据的供应及存储通路,进入了良性的发展通道。贵安区超也结合贵州省大数据产业的大势,提出“两大一超”的发展战略,即围绕生物大数据和天文大数据,打造有区域影响力的超算中心。
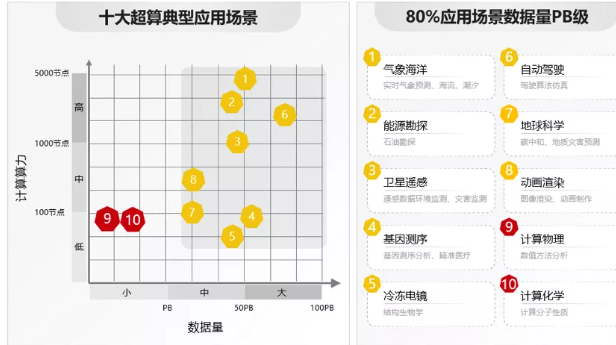
误区3:超算的存储不重要,服务器JBOD就够了?
真相3:长期以来,中国的超算中心建设存在重算力、轻存储的现象,据估算,中国超算中心的存算比(即存储容量PB的比值和计算算力PFLOPS)一般在1:3甚至更低,而且存储大量使用服务器JBOD方案,尤其是高校科研用途的超算,更是较少采用专业的外部存储。带来的后果是数据存储的可靠性没有保证,大规模数据读写的性能没有保证。本地盘存储能力不足,跨服务器数据共享访问能力不足,都会带来性能的急剧下降,只能依靠建设高速缓存层来解决,这又带来的成本的急剧上升。反观美国的超算,超算中心的存算比普遍一般在1:2以上,美国能源研究与科学计算中心(NERSC)第八代超算集群存算比高达1:1,最新的第九大超算集群Perlmutter更加重视超算存储的能力,为此配备了35PB的全闪存,成为全球首个全闪存超算。
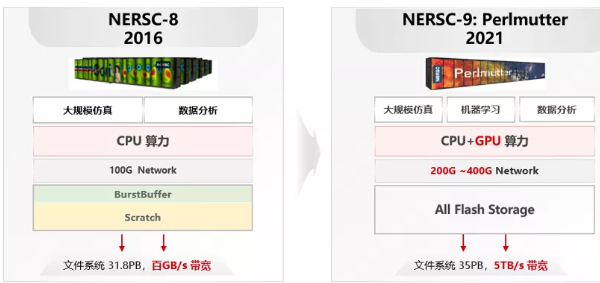
误区4:超算的存储不需要统一规划,需要的时候再扩容就够了?
真相4:超算的算力每3~5年就会更新,超算中心也会按需引进一些新机器,但是由于在建设之初,缺少对存储的统一规划,往往是算力更新换代,存储也要更新换代,数据也要随之迁移;部署新的机器,就要部署新的存储,逐步形成一系列的数据孤岛。以国家地震局数据中心为例,为了打破数据孤岛,只能增加多个数据副本,最多的一份数据有27个副本,大幅提高了数据中心的建设成本。另外,近年来超算存储的建设呈现出分层建设的趋势,即根据数据的热温冷规划存储,热数据一般使用高速缓存层,温数据一般规划专业的固态存储,冷数据则采用HDD或蓝光归档介质,各层统一规划,对外提供多种协议接口,供多元算力访问,对内数据可以分级管理,自由流动。
误区5:超算存储系统就用开源Lustre挺好,不需要国产自研?
真相5:Lustre是由Intel主导开源的并行文件系统,目前Lustre广泛部署于HPC系统中,TOP100超算中60%使用了Lustre。但天下没有免费的午餐,近年来,Lustre面对超算产业的发展,也出现了应对乏力。首先,Lustre接口比较单一,只支持与Posix兼容的文件系统,但是HPC走向HPDA,AI需要S3的对象结构,大数据需要HDFS接口,这些Lustre都不具备。第二,Lustre是非全对称架构,MDS负责元数据管理,OSS负责数据管理,MDT和OST是对应的存储空间,访问数据要从MDS->MDT->OSS->OST,访问路径长,访问性能低,而且MDS不可扩展,大文件访问还能接受,小文件基本不可接受。第三,Lustre没有EC和副本冗余,可靠性均依靠后端存储系统,MDT和OST存储一般使用基于JBOD的SAN存储,可靠性也无从保证。第四,Lustre不支持多租户和数据隔离,在超算中心走向服务化的大背景下,不能适应。最后我们从自主可控的角度来看,我们从Google的“开源”也可以得到启示。中国的超算有必要也必须逐步构建在国产自研的根基之上,以应对釜底抽薪的风险。
以上五个认知误区,并不是否定中国超算取得的巨大成就,一定程度也是中国超算从跟随者走向引领者必然阶段。这五个认知误区的本质还是,长期以来,超算的发展对于数据不重视,对于数据基础设施建设不重视的结果。
值得关注的是,九月底在兰州的第九届超算创新联盟大会,正式成立了一个数据密集型超算工作组,把数据能力上升到和算力同样的高度,提出超算中心从算力服务时代迈向数据价值时代,数据密集型超算正当时。近日在呼和浩特召开的第七届科学数据大会,拥有最核心的数据资产20家国家科学数据中心共聚一堂,数据密集型超算也成为热议的话题。打破认知误区,或许进一步重视数据,发展数据密集型超算才是中国的超算强国之路。
