首先提出这样的问题是比较常见的现象。即看到一种火热的技术现象,产生对事物的一种浅层认知后,想获得一个比较深刻的认识。
大数据具有社会化,技术性的重要特点。
从社会化看
先说这个“大”,也就是大数据最早的定义:速度、类型和容量,所谓的3V。实际上大数据的发展早已经突破了这个定义。数据体现的不是所谓的“大小”,而是规模。
每个人的手机,都是一部随时产生数据的设备,我们时刻发着消息,每次点击APP,都生产一条事件数据,无论这个操作单独看起来,有多么无价值,但它仍然会被云端记录,因为其只是大数据总体价值的一个原子单位;工业上因为物联网技术的实施,加剧了大规模数据的汇聚,目前工业上谈数据汇聚,都是上千个采集点,每秒上百万的实时数据该怎么去处理;
人、车的移动与地标、建筑形成的坐标网,可以绘制城市的动态画像,而不是过去靠电话线、TV和人力上报统计来完成,这就是智慧城市的大数据鲜活力的表现。
我们再说数据的流动性,或者说数据的生命周期。数据在过去的流向基本都是数据坟墓,也就是有一个启动点,亦会有一个终点。
在大数据的时代,数据有时候可能会在流动的中途就消失了,但新形式的数据又会产生,也可能会在一个阶段后就不在被使用,其流动性越来越强,可是又提倡了和以前截然相反的存储方式:数据的原始形态越来越早的被存储,而不是经过ETL的加工形成固有设定的样子而沉寂下去。
因为越早的原始数据被存储,就能为数据在生命周期内的不同阶段提供给分析者更全面数据特征,利用价值关系提取,但终将会在生命周期结束时清理掉,无论是因为政策、技术存量还是设计思想。
社会化的另一个问题就是数据的多样性,城市视频采集,每天需要经历PT级别的多媒体数据需要进行清洗;
工业设备会以设备类型+时间戳+状态值的形式源源不断的传递来时间序列数据,需要存储、回放和监测;
社交网络吸引着大量的用户流量,流量的关键媒体就是图、文、短视频;
搜索引擎爬虫每天要一遍接着一遍的对所有登记注册的网站重新抓取更新页面,计算页面在互联网上影响力,这一切都是过去在传统数据结构下,用结构化的设计思路难以想象的事情。
最后再说说大数据的开放性,这就和“小数据”具有了非常明显的不同,大数据讲究开放,通过共享的平台实现数据的接入,也同样实现数据的对外连接。
事实上,大数据的发展步伐太快,隐私政策和信息法都被甩在了身后,所以才会出现大家所痛恨的不良商家对个人隐私的侵犯。当大数据的规模到了临界点的时候,尤其是电子商务平台和社交平台,那么这种脚步就会放缓,目前看隐私政策法规已经逐步清晰多了。
反观小数据,实际上就是一个社会化的一种长尾的表现,
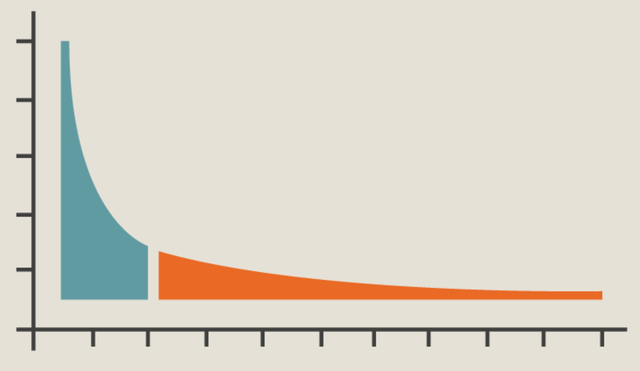
大数据集中在蓝色部分,被少量的大厂、政府机构、公共事业部门所拥有,那么这些数据无论面向社会的那个领域,都趋向于数据的统一结构化、标准化和共享性,不过社会大量的企业、软件服务商的信息库中都存有各式各样设计的数据表,就是黄色部分一样形成长长的尾巴。因此小数据是趋向于结构设计的多样性,而且因为不具备共享技术的投入和动力,大量的小数据大多数都是封闭的。
从技术看
谈完了大数据的社会化特点,我们再说说大数据的技术问题。大数据的规模化导致了原先传统技术的数据处理系统无法实现正常的操作了,甚至已经远远达不到向客户承诺的SLA(服务级别协议)——品质、水准、性能,才会有大数据技术的出现。
就追溯大数据技术的源头,谈谈Google,当年Google打遍天下无敌手的Page Rank算法,运行在传统的昂贵的商业单机数据库上,结果可想而知,存储规模远远超过单机所能承受的极限。Google遵循的是一种简单直接的设计风格,设计出了GFS分布式文件系统,更让人大跌眼镜的是,居然没有设计索引?
难道Google的设计师在设计索引的时候睡着了,醒来就忽略了吗?其实不然,这就是Google设计理念的关键,抓住问题的本质,目标是能在分布式的环境下更快、更多的存储原始数据,不去设计索引,就能大大减轻了数据存储的负担。Google的目标是对抓取的页面分析价值、影响,然后形成排名,再写入到页面查询索引的数据库。那么这个分析的过程,可以批量的、顺序的、大块的读取数据,然后并行任务的去提升效率分析处理。
GFS的设计方法很有效,简单直接,就像二战苏军的t43坦克一样,没有德军虎式精密,但是可以大量廉价的生产,发挥战争中的规模效应,互联网战场也一样,迅速的扩大占领区。
GFS的开源版,就是大名鼎鼎的Hadoop了,看着Hadoop,就跟看见他大哥GFS一个模子,HDFS可以说把大文件的高效、分块、顺序读写发挥到了极致。
当面对社会化大数据的快速发展,而设计出了的最简单、直接、高效的技术手段去解决之后,在做一些精细化的发展,例如:GFS之上就有了BigTable,开源的HDFS之上就是HBase,通过SSTable+LSM树的数据结构建立符合大数据写入和回放的索引机制,完全不同于传统的关系型数据库的B树索引了!这种索引机制也是NoSQL的基石。
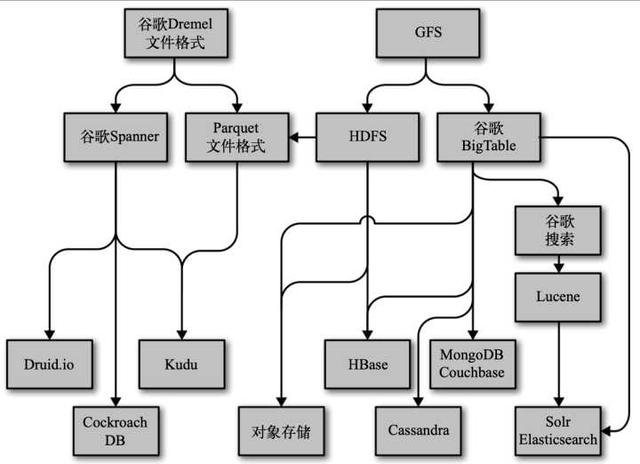
这张图就是大数据存储的谱系,可以看到顶端数据存储部分追溯到了Google的GFS。
Google这是引领了大数据时代的技术,让我们能更加从容的去应对大数据带来的数据系统冲击,关键还是我们实实在在的大数据需求,需要在这个庞大的技术生态中寻找到合适的组合方案,这才是大数据技术应用的关键。
所以曾经言必大数据的火热期早已经过去了,无论从客户方,还是技术方都在探寻什么才是真正的大数据,但至少知道挂一个大屏,展示几个统计图的那个所谓的“大数据”形式,早已成为过去的笑谈。
真正的大数据时代已经来临,而且懂得如何利用技术去解决大数据问题,产生出以前不敢想的数据价值,或者以前难以轻松做到的事情,现在很多都将变为可能。
无论是使用批量技术用Spark将数据集和机器学习算法进行连接也好,还是用Kafka实现每天百亿数据的汇聚分发也罢,都是为了使得让更大量的数据形成流动的价值,为不同类型的用户提供独具特色的数据服务。
这时候数据的产出过程更像流动的血液,社会的血液,让我们的生活表现得更生动、活跃。
