本文来自微信公众号“DeepTech深科技”,【作者】加洋。

4月29日下午,DeepSeek多模态团队负责人陈小康(Xiaokang Chen)在X发布动态:“Now,we see you.👀”,配图为两只DeepSeek鲸鱼logo,一只仍戴着海盗眼罩,一只已经睁开眼睛。这是他在24小时内第二次释放类似信号。前一天,他曾发布措辞为“Soon,we see you”的同主题预告,随后该推文被删除。
图丨相关推文(来源:X)
陈小康目前在DeepSeek负责多模态预训练与后训练,统领DeepSeek大模型的多模态能力建设。其北大博士阶段导师为曾刚教授,研究方向涵盖视觉-语言模型、半监督分割、masked image modeling等。
与预告同步,部分用户已在DeepSeek官方App中灰度到“识图模式”(可惜笔者和同事们都没能被灰度测试到)。截图显示,App输入栏上方除原有的“快速模式”“专家模式”外,新增“识图模式”按钮,并标注“图片理解功能内测中”。社交平台流出的内测截图显示,用户上传一张图片后,能够输出包括“分析用户需求”“分析图片”在内的结构化描述,识别图片具体内容。
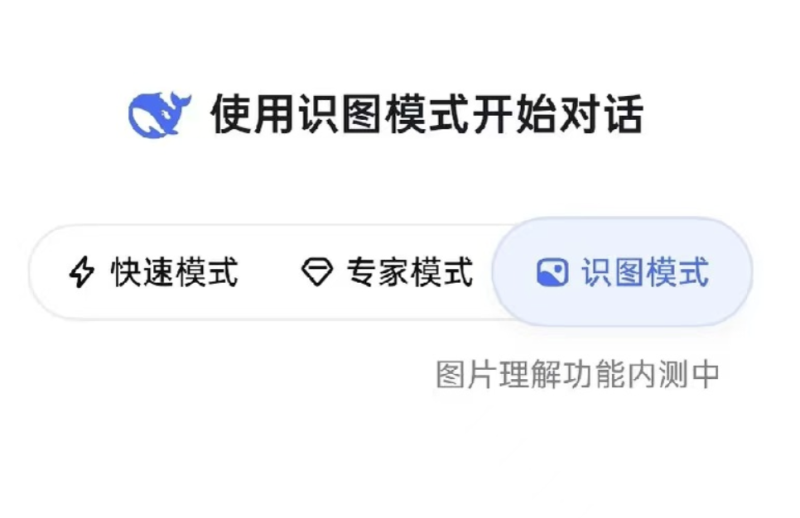
图丨新上的识图模式(来源:小红书云涧梦)
这是DeepSeek主线产品中首次出现具备图像理解能力的模式。此前4月8日,DeepSeek App完成第一轮模式分层改版,上线“快速模式”和“专家模式”,根据V4发布后的官方说明,前者由V4-Flash驱动,后者对应V4-Pro。当时已有微博用户(蚁工厂)放出含“快速/专家/视觉”三档选项的截图,但视觉一档迟迟未开放。从今天起,这一档开始进入小范围灰度。
这次内测距V4正式发布刚过5天。4月24日DeepSeek发布的V4系列预览版(V4-Pro 1.6T参数/V4-Flash 284B参数,均支持1M token上下文)仍是纯文本模型,这一点和此前外界关于“V4将原生多模态”的密集传闻不符。V4技术报告第6节“Conclusion,Limitations,and Future Directions”中明确写道,下一步工作之一是“将多模态能力融入模型体系”。
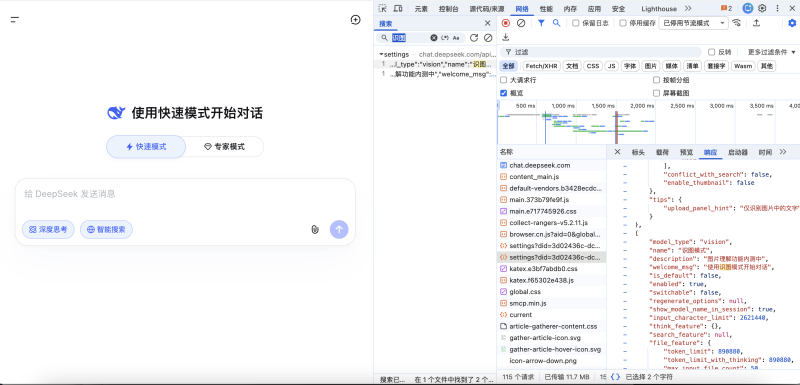
图丨通过浏览器开发者工具抓取chat.deepseek.com的settings接口可以看到该模式的后端配置已经下发:"model_type":"vision"、"name":"识图模式"、"description":"图片理解功能内测中"、"enabled":true、"is_default":false、"switchable":false。也就是说,识图模式已经在后端启用,但默认关闭、不允许用户手动切换。(来源:DeepTech)
值得注意的是,V4发布前后曾有一系列围绕DeepSeek多模态人才流失的报道。4月12日,自动驾驶公司元戎启行确认DeepSeek多模态模型核心贡献者阮翀已加盟出任首席科学家;DeepSeek-OCR系列核心作者魏浩然在春节前后离职。此次陈小康的两次预告与识图模式灰度上线,是DeepSeek多模态团队近三个月来第一次以产品形式对外释放进展。
不过,目前可观察到的能力仍限于图像理解(vision-language understanding),而非外界过去半年反复猜测的“原生多模态生成”。从App灰度截图的输出风格判断,识图模式更接近一个挂载在V4主干上的视觉理解模块。
DeepSeek官方目前未对识图模式的开放范围、正式发布时间、底层模型来源做出说明。但从陈小康从“Soon”到“Now”的两次发帖节奏判断,更大范围的开放或许在数日之内。
参考资料:
1.https://x.com/PKUCXK/status/2049381471669080209
注:封面/首图由 AI 辅助生成
