靶点发现:创新药研发的"牛鼻子"为何这么难牵
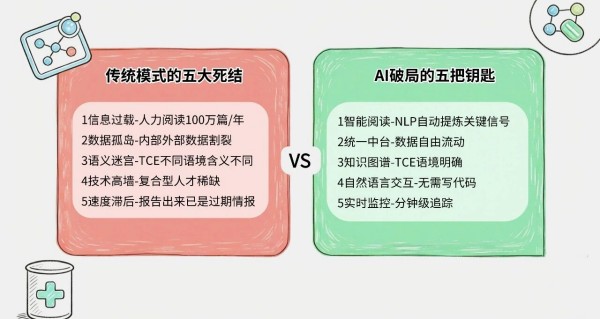
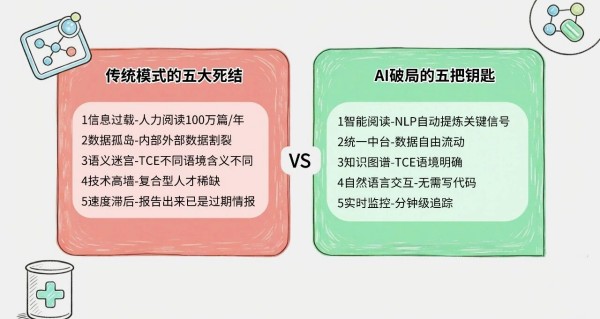
靶点发现,是创新药研发的起点,也是决定成败的"牛鼻子"。一个靶点选对了,后续的药物设计、临床试验才有意义;选错了,数十亿研发投入可能打水漂,数年的宝贵时间付诸东流。这个道理,每个药研人都懂。但现实是,找到一个靠谱的靶点,行业平均耗时36个月——整整三年。三年里,药研团队在经历什么?信息分散在几十个数据库,每一个都是孤岛,每一个都要单独登录、单独导出、单独整理。数据孤岛难以打通,成了第一道坎。好不容易把数据汇总到Excel里,又是新一轮的煎熬。人肉阅读文献、人工提取数据、人工比对分析——一个靶点的系统性评估,耗时数月是常态。遇上热门靶点,文献上千篇,根本读不过来;遇上冷门靶点,证据零散,拼图拼到怀疑人生。更扎心的是,结论难验证、容易出错。文献里A说有效、B说无效,你信谁?临床数据更新了,竞品动态变化了,你的分析结论还能站住脚吗?
36个月
这不只是时间成本,更是机会成本——竞争对手可能正在某个你没注意到的靶点上加速冲刺。
怎么办?
神州问学靶点情报分析系统正在改变这一切。
我们用AI重构了靶点发现的全流程,将这一周期从36个月压缩至12个月以内,效率提升66%。这不是简单的速度提升,而是研发范式的根本性转变。
潜入数据海洋:3500万文献背后的硬实力
任何智能分析系统的基石,都是数据。空有算法,无异于巧妇难为无米之炊。神州问学靶点情报分析系统构建了医药研发数据底座,为精准洞察提供了坚实保障。
学术深海:3500万篇以上的生物医学文献,PubMed全量数据每日更新,年增超过百万篇。这是理解靶点生物学机制的基石。
临床航道:99.8万项全球I-IV期临床试验数据被实时追踪。从这里,可以掌握任何在研药物的最新疗效与安全性证据。
商业暗流:整合超过35个权威商业数据源。市场竞争格局、专利布局、交易动态,在此一览无余。
组学宝藏:超过1000万个基因组、转录组等多组学样本数据,从分子层面为靶点提供多维度的生物学证据链。
这不仅仅是数据的简单堆砌。在数据入库时,系统进行严格的"数据治理"——将不同来源的企业名称(如某创新药企的拼音、汉字、缩写)统一归整到唯一的公司ID下。在检索时,它又能智能联想,把用户查询的词条自动关联到具体药物名称上,确保搜索既全面又精准。有了这片数据海洋,AI才能化身成为经验丰富的导航员,为我们绘制出清晰的靶点探索地图。
三大智能体协同解题:一场自动化的深度研究
拥有了海量数据和强大的数据底座,如何将这些碎片信息转化为可直接用于决策的"洞察"?
神州问学靶点情报分析系统给出的答案是:三大智能体协同。
这不是简单的检索,而是让三个AI Agent像三位分工明确的资深分析师一样,协同完成复杂的靶点研究任务。
研究规划智能体负责理解用户意图,将一个模糊的问题拆解为系统性的研究框架。它会像项目经理一样,先规划"研究路径",再按图索骥。
信息检索智能体负责从海量数据中精准抓取所需信息。它能同时并行查询结构化数据库和非结构化文档,并根据问题类型自动选择最优检索策略——确定性问题走NL2SQL,开放性问题走RAG。
综合分析智能体负责对检索结果进行交叉验证、冲突检测和维度聚合。它能发现不同来源间的数据矛盾,并主动寻找更多证据核实;也能将高额License交易与对应的临床数据进行关联,揭示背后的商业逻辑。
三个智能体各司其职、协同作战,确保分析过程既全面又严谨。
走进智能工厂:四层架构如何"生产"洞察
三大智能体背后,是神州问学靶点情报分析系统精心设计的四层技术架构,如同一条精密的情报生产流水线。
第一层:原料预处理车间(数据治理层)
杂乱无章的原始数据,在这里经过清洗、消歧、标准化,被贴上统一的"身份标签",变成格式规整的"标准原料"。
第二层:智能分拣中心(混合检索层)
系统在这里对问题进行分类,并路由到最佳生产线。如果问"某靶点相关的License交易平均首付款是多少",这是确定性问题,系统通过NL2SQL技术瞬间转化为数据库查询,秒级返回精准数字。如果问"这个靶点最新的耐药机制研究有哪些进展",这是开放性问题,系统启动RAG引擎,从千万篇文献中检索、理解并生成综合答案。
第三层:精密质检与合成车间(逻辑推理层)
这是产生"化学变化"的地方。系统能自动检测不同来源数据间的"矛盾"——比如A数据库显示某临床试验已终止,而最新文献却报告了积极结果。系统会标记此冲突,并主动交叉验证。更重要的是,它能进行"维度聚合"——将一笔高额License-in交易,与交易方刚公布的惊艳临床II期数据横向关联,自动揭示天价交易背后的商业逻辑。
第四层:标准化包装与溯源出口(生成溯源层)
所有产出的洞察报告,都以清晰的结构化格式呈现。最关键的是,报告中每一句话、每一个数据,都标注了来源。这确保了整个分析过程可追溯、可复核,极大提升了决策可信度。
实战演练:四代EGFR抑制剂全景分析
理论很美好,实战到底如何?让我们化身一位药研科学家,亲身体验一下。假设你正在评估非小细胞肺癌的靶点布局,你在神州问学靶点情报分析系统中输入一个问题:
"四代EGFR抑制剂的竞争格局怎么样?"
系统没有直接给你一堆零散的链接,而是瞬间启动了一位"虚拟行业分析师"模式。
这不是搜索,是协同研究。
系统首先将你的宏观问题,智能拆解成一个包含6个维度的完整研究计划:
1.全景扫描:全球及中国主要在研药物与公司图谱。
2.聚焦国内:BBT-176、IBI351、SH-1028等重点国产药物的临床进度与核心数据。
3.技术深剖:各药物对C797S突变活性如何?对野生型EGFR选择性怎样?入脑能力是否强劲?
4.策略洞察:主要玩家是自主研发,还是License-in/out?有没有布局组合疗法?
5.临床定位:瞄准哪些适应症赛道?未满足的临床需求是什么?在耐药后治疗中扮演什么角色?
6.市场预判:市场前景如何?预计的上市时间格局是怎样的?
接着,系统按照这个框架并行抓取信息。它同时查询结构化数据库(交易金额、临床阶段)和非结构化文档(文献、会议摘要)。
如果发现不同数据源对同一药物的临床阶段描述不一致,它会自动触发红色预警,进行多方复核,并在最终报告中明确标注此"信息争议点"。
最后,它交付给你的不是信息碎片,而是一份结构化的竞争情报报告。报告不仅告诉你"有什么",更分析"为什么"和"怎么办"。
例如,它会指出:
•A药物在抑制C797S突变上数据最亮眼,但血脑屏障穿透性一般;
•B药物活性中等,却因优异的入脑能力,在脑转移患者中可能成为"黑马"。
几分钟内,你获得的是一份经过深度加工、可直接上会讨论的决策支持文档。
效率,就是这样被重塑的。
三大核心能力:让每个人成为分析专家
支撑上述神奇体验的,是神州问学靶点情报分析系统沉淀在系统底层的三大核心能力。

能力一:NL2SQL,用说话代替编程
科学家只需用自然语言提问:"请列出过去三年,针对XX靶点、交易总额超过5亿美元的所有License-in交易,并按首付款排序。"
系统瞬间将其转化为复杂的数据库查询语句,秒级返回结果。数据团队从此解放,科学家真正实现了"数据民主"。
能力二:术语本体库,构建行业知识图谱
系统内建了一个庞大的医药知识网络,清楚定义了疾病、靶点、药物、基因间的所有关联。当查询"PD-1"时,它能自动联想到"纳武利尤单抗"、"帕博利珠单抗"等所有相关药物,以及"非小细胞肺癌"、"肝癌"等适应症,确保分析既全面又准确。
能力三:双维度竞争情报报告
系统产出的不是信息罗列,而是融合了科学价值与商业价值的立体评估。它让研发部门关注的"机制好不好",与BD部门关注的"市场大不大",在同一份报告里得到统一回答,彻底对齐了决策的标尺。
效率被重新定义,起点已被重塑
从36个月到12个月,神州问学靶点情报分析系统带来的价值清晰可见:
•效率革命:靶点发现周期压缩66%,为抢占市场先机赢得宝贵时间窗口。
•全面洞察:基于3500万文献与35+权威数据源的交叉分析,扫除信息盲区。
•智能决策:科学价值与商业价值双维度量化评估,每一结论均可溯源。
•降低门槛:NL2SQL让药研科学家无需技术背景也能进行复杂分析。
在药物研发这场高投入、高风险、长周期的竞赛中,信息处理的速度与质量,直接决定了创新的成败。
神州问学靶点情报分析系统不仅是工具的进化,更是研发范式的重塑。当效率成为核心竞争力,AI已从"锦上添花"的选项,变为"雪中送炭"的必备。
我们诚邀您,亲自体验神州问学靶点情报分析系统。

扫码咨询