本文来自微信公众号“白鳝的洞穴”,作者/白鳝。
昨天谈到在边缘侧计算领域,Oracle不是一个合适的选择,有些朋友不太理解,为啥边缘侧Oracle就不适合。我想这个朋友一定没有见过工业领域的应用场景。今天以电网的源网荷储友好互动的例子来介绍一下工业领域的边缘计算,这种计算模式广泛的存在于工业互联网。
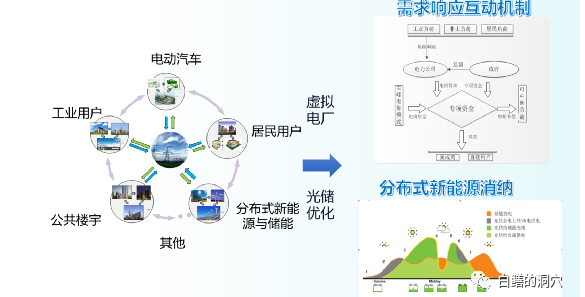
电网系统是一个十分复杂的系统,在源端以前接入的大多数都是相对稳定的电源。而随着新能源消纳的需求增加,光伏、风能、水电等不稳定电源的占比逐渐提高,电源侧变得极其不稳定。而在负荷侧,随着新能源汽车等电力驱动的设施越来越多,负荷波动也越来越不规律。电网是一个对供需平衡要求极为严苛的大型网络系统,这种源网荷波动极大的需求场景对电网提出了更高的要求。
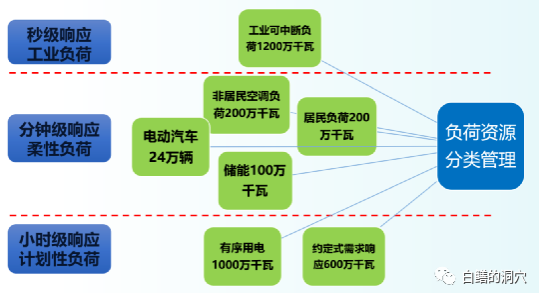
举个例子,比如某个省电力公司的负荷,计划性很强的有序用电大约1000万千瓦,约定式需求响应用电600万千瓦。这1600万千万的用电是相对稳定的,可以以小时为单位进行调度,属于计划性用电。而这些年里柔性响应负荷占比越来越高,这些负荷需要分钟级响应。比如数十万辆电动汽车随时存在充电需求,200万千瓦的非居民空调负荷在气候变化中随时需要响应,200万千瓦的居民负荷也必须保证供给。随着这些负荷占比的增加,对电网调平的要求也越来越高。因此就需要加大分钟级可响应的储能设施的建设。
虽然如此,电网调度也面临巨大的挑战,因为电源侧的输入与负荷端的电能消耗是随时波动的。如果我们无法精确、准确、及时地采集到这些数据,并且快速完成计算,反馈到电力调度中,那么就无法做到很精准的调度。当发电量大于消费量的时候,那么发电企业就要受到影响,部分电能无法上网,欧洲出现的0电价和负电价正是消费与供给不平衡的一种结果。而当消费端消耗过大,电网负荷无法供给的时候,那就需要进行拉闸限电了。为了确保电能的随时平衡,就需要一个巨大的随时可中断的负荷。这种负荷只能在工业领域去获得,比如这个例子中为了保证电网安全,需要有1200万千瓦的可秒钟级响应的工业负荷。
中断工业用电的后果是十分严重的,这会影响经济。虽然目前政府、电网和企业之间签订了一些对企业的补偿协议,让企业圈定部分可随时拉闸的负荷,同时给企业一定的经济补偿。不过拉闸限电就意味着经济损失,因此我们需要去尽可能避免,如何降低这部分负荷是电网友好互动的一个重要任务。为了实现这个目标,必须更加精准、快速的获得源网荷储相关的数据,因此需要在边缘侧投入巨大的算力。这部分算力所处的位置分布极其广泛,分布在储能、变电站、电厂、输电线路、配电房、分布式能源、充放电站、环境/气象监测设备等处。
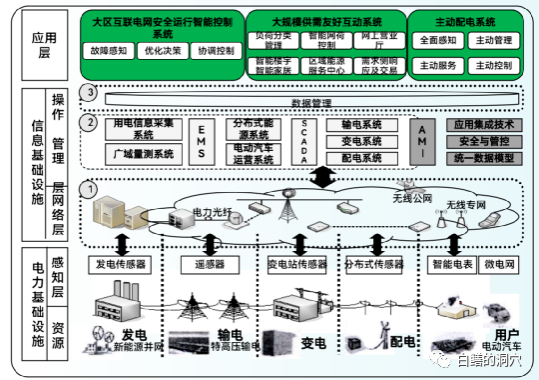
在电力基础设施层,以往都是将数据传输到云端进行计算,随着计算复杂度的增加,以及对计算实时性的要求不断提高,对网络与云端压力也很大。这种模式今后是不可持续的,大量的计算下沉到边缘侧计算已经成为了趋势,在边缘侧部署算力是必然的。
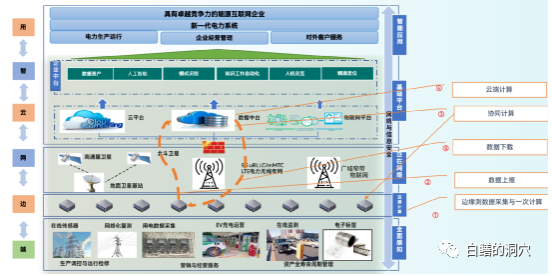
在边缘侧进行一次计算,既可以提高计算的实时性,也可以避免大量明细数据在边缘侧和云平台之间的传输。是今后必然被优先选择的计算模式。为了实现这种能够边缘计算,大部分计算单元被放置在没有专业IT管理的区域,甚至单元被放置在无人值守的场站中。这些IT设备必须是装备化设计的、自动化运行、免运维的。以处理的复杂度和规模来看,嵌入式数据库又太小,一个库的规模从几个GB到一两百GB不等,需要一种规模适中、运维方便、免值守的数据库系统。
简单分析一下,这个数据库只需要存储一般性的数据,做简单的批量写入、批量输出、和小批量计算。MySQL这样简单的数据库是能够在这种场景中发挥很大的作用的。一旦部署好之后,基本上可以自动化运行,如果系统出现问题,大不了杀掉重启就行了,实在不行整个服务器重启一下也就搞定了。只要把一两百M的重要元数据备份好,这个数据库完全坏掉也没关系,大不了重建一下,再灌入备份好的重要元数据,就可以自动恢复了。
边缘计算是下一个硝烟弥漫的战场,目前在边缘侧还只是做一些简单的固化的计算,随着企业数字化进程的发展,边缘侧的计算规模与计算模式都会有较大的变化,边缘侧大规模使用数据库系统也是一个必然的趋势。也许数据库竞争的下一个战场就摆在那里了。
