本文来自微信公众号“开源云中文社区”。
回到1994年(是的,差不多30年前了),Thomas Sterling和Donald Becker在美国国家航空航天局制造了一台名为Beowulf的计算机。
这台计算机(又名Beowulf集群)的架构由一个廉价的个人计算机网络组成,这些计算机串联在局域网中,以便在它们之间共享处理能力。这是一台专门为高性能计算(HPC)设计的计算机的开创性例子,它完全由商品部件和免费软件组成。
Beowulf集群可用于并行计算,其中许多计算或进程在许多计算机之间同时进行,并与消息传递软件协调。这是Linux和HPC开源的开端,使Beowulf真正具有革命性。在接下来的10多年里,越来越多的人遵循Beowulf模式。2005年,Linux在top500.org上占据了第一的位置,从那以后,它一直是HPC的主导操作系统。
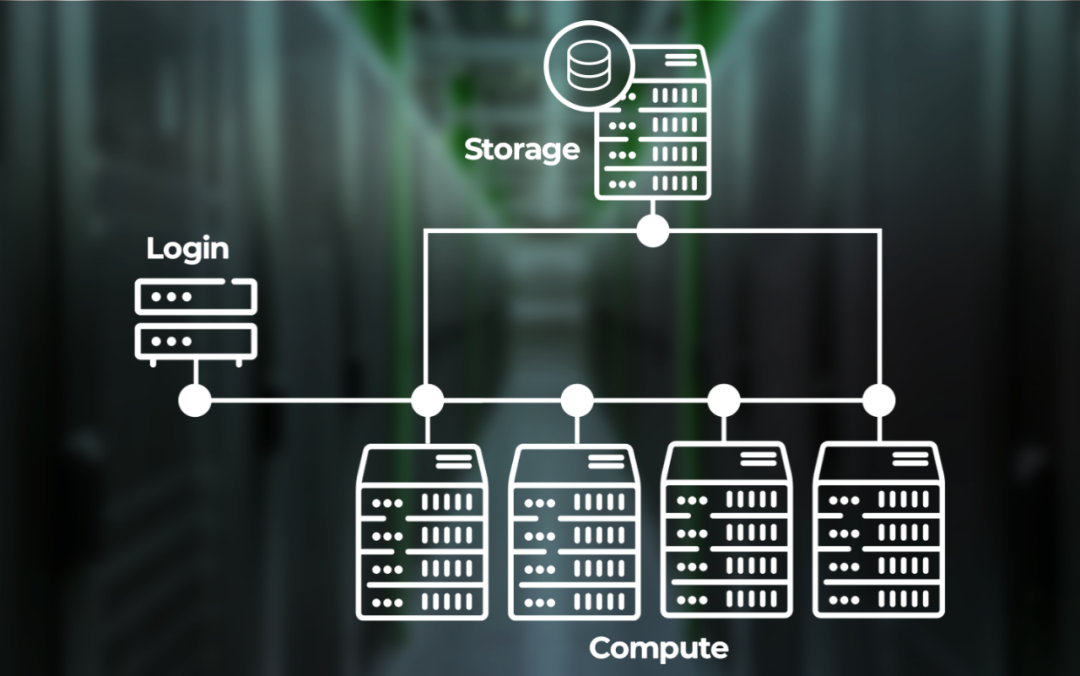
Beowulf集群的基本架构从一个交互式控制节点开始,用户可以在该节点登录系统并与系统交互。计算、存储和其他资源都连接到一个(或多个)专用网络。软件堆栈包括Linux、操作系统管理/供应(例如Warewulf)、消息传递(MPI)、其他科学软件和优化的库以及用于管理用户作业的批处理调度器。
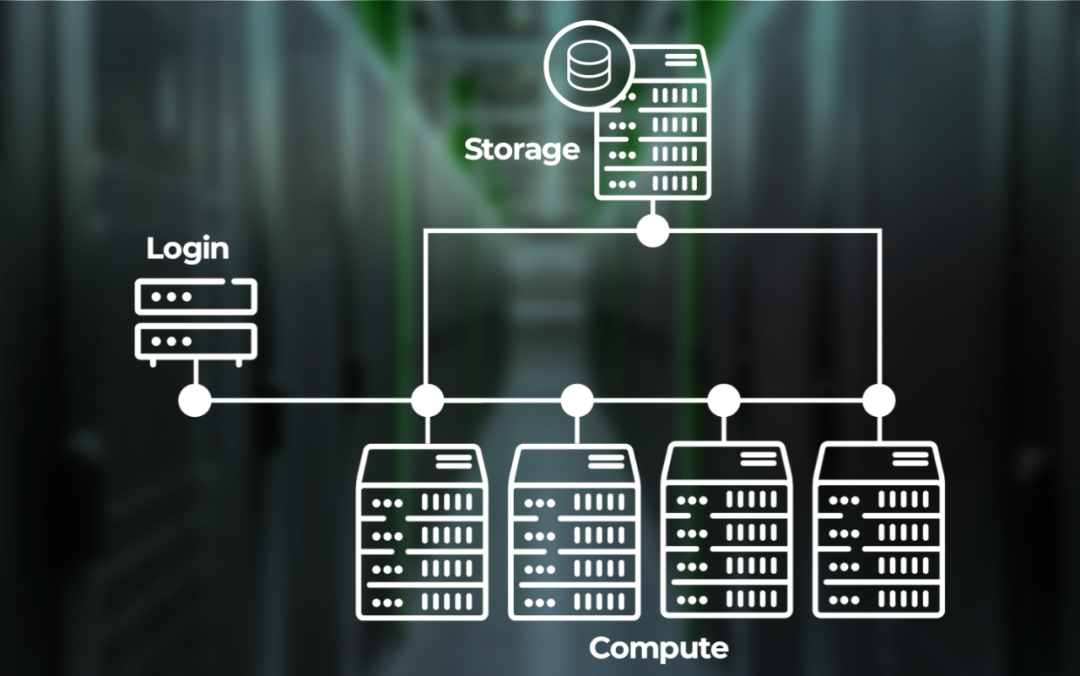
随着时间的推移,这些系统变得更加复杂,具有多层存储和计算资源组,但基本的Beowulf框架已经保持了30年。HPC工作流程也是如此。从用户的角度来看,三十多年来,HPC使用者的生活没有变得更轻松。通常,对于所有HPC系统,每个HPC用户都必须遵循相同的一般步骤:
——SSH到交互节点。
——研究并了解存储系统配置和装载点。
——将源代码下载到正确的存储路径。
——编译源代码时要考虑系统或优化的编译器、数学库(和位置)、MPI,以及可能的存储和网络架构。
——将要计算的数据上传到正确的存储路径(可能与上面的源代码路径不同)。
——研究资源管理器队列、账户和策略。
——根据测试数据测试和验证编译的软件。
——监控作业执行情况并验证功能是否正确。
——验证作业输出。
——如有必要,重复上述步骤。
——下载生成的数据进行后期处理或进一步研究。
使用有30年历史的HPC架构的不断增长的成本
我们继续使用遗留的HPC框架,因为失去机会、无人认领的规模经济和影子IT成本,给科学界带来了高昂的损失。
失去的机会包括研究人员和组织,他们无法使用遗留的HPC计算架构,而是只能使用不可支持、不可扩展和不专业维护的架构。例如,笔者见过许多研究人员使用笔记本电脑作为计算基础设施。
其他失去的机会包括无法适应现代工作负载,其中许多工作负载没有得到遗留HPC架构的充分支持。例如,几乎不可能将传统的HPC系统架构安全地集成到用于自动化训练和分析的CI/CD管道中;更简单的开发和资源前端,如Jupyter;日益多样化的工作;以及multi-prem、off-prem甚至云资源。
此外,许多企业已经表现出对Beowulf等遗留系统架构的抵制。“我们不希望系统管理员再使用安全外壳(SSH),Beowulf要求所有使用SSH的用户与系统接口!”
当IT团队必须为特定的需求和用途构建定制系统时(这是目前许多科学中心正在发生的事情),他们无法有效地利用硬件投资,因为每个“系统”都是一个孤立的资源池。我们现在看到了这一点,中心为基于计算的服务构建了完全独立的系统,Jupyter与Kubernetes构建了系统。如果HPC资源正确地支持所有这些用例,那么可以实现规模经济。
此外,在太多的情况下,研究团队试图在IT权限之外构建自己的系统或使用云实例,因为他们觉得IT没有提供研究所需的工具。虽然云使某些形式的计算变得容易,但在本地预处理资源上,或者如果你被锁定在一个云供应商中,它并不总是有意义的。
这些不幸的事实正在扼杀研究和科学进步。
进步的暗示?
当然,已经出现了一些让HPC用户的体验变得更容易的事情。例如,Open OnDemand是封装整个Beowulf架构并将其作为基于http(即基于web)的图形界面返回给用户的一种极好的方式。OnDemand在提供比SSH更现代的用户界面(UI)方面提供了巨大的价值,但许多网站发现,它并没有显著降低进入门槛,因为用户仍然需要理解上面概述的所有相同步骤。
另一个改进是Jupyter Notebooks,它在让研究人员和开发人员的生活变得更好方面是一个巨大的飞跃。Jupyter经常在学术界用于教学目的,它帮助研究人员进行实时开发,并使用更现代的交互式网络界面运行“笔记本”。通过Jupyter,我们终于看到了用户体验的演变——步骤列表被简化了。
然而,Jupyter通常与传统的HPC架构不兼容,因此,它不可能与现有的HPC架构集成。事实上,许多传统的HPC中心在一侧运行其传统的HPC系统,而在另一侧使用其Jupyter系统在Kubernetes和以企业为中心的基础设施之上运行。的确,你可以使用Open OnDemand加上Jupyter来合并这些方法,但这会为用户重新构建流程——添加更多不同的步骤,使流程变得困难。
容器引领迈向更现代的HPC世界
容器已经成为HPC世界的“潘多拉盒子”(以一种很好的方式!),展现了在非HPC领域中发生了许多创新对HPC社区非常有益。
企业中容器的出现是通过Docker等实现的,但这些容器实现需要特权根访问才能操作,因此允许非特权用户访问运行容器会给HPC系统带来安全风险。这就是为什么笔者为HPC创建了第一个通用容器系统——Singularity——由于之前大量未满足的需求,该系统立即被全球HPC中心采用。从那以后,笔者将Singularity加入了Linux基金会,以保证该项目将始终为社区服务,由社区管理,不受所有公司控制。作为这一举措的一部分,该项目被重命名为Apptainer。
Apptainer改变了人们对可复制计算的看法。现在,应用程序在系统、研究人员和基础设施之间变得更加可移植和可重用。容器简化了为HPC系统构建自定义应用程序的过程,因为它们现在可以很容易地封装到包含所有依赖项的容器中。容器在启动HPC现代化过程中发挥了重要作用,但这只是改善HPC用户生活的第一步。想象一下,随着驱动下一代HPC环境的HPC转型,接下来会发生什么。
接下来会发生什么?
现在是计算转型的时候了:通用HPC架构需要现代化,以便能够更好地提供更广泛的应用程序、工作流和用例。利用现代基础设施创新(云架构、GPU等硬件),我们必须构建不仅支持历史/遗留用例,而且支持下一代HPC工作负载的HPC系统。
在CIQ,我们目前正在进行这方面的工作,并一直在开发一种解决方案,使HPC能够为所有体验级别的用户所接受。我们的愿景是提供一个现代的云原生、混合、联邦基础设施,该基础设施将在云和多云中,甚至在多云的多个可用性区域中,在内部和多混合中运行集群。
一个巨大的分布式计算架构将与一个单一的API结合在一起,为研究人员提供在位置、移动性、重力和数据安全方面的完全灵活性。此外,我们的目标是抽象掉操作的所有复杂性,并最大限度地减少运行HPC工作流所涉及的步骤。
我们的目标是通过使HPC架构现代化来实现科学——既支持更广泛的工作多样性,又降低更多研究人员进入HPC的门槛,优化所有人的体验。