本文来自微信公众号“twt企业IT社区”,作者/白鳝(徐戟),南京基石数据技术有限责任公司技术总监,在软件开发、系统运维、信息系统优化、信息系统国产化替代等领域从事技术研究近30年,曾主持开发了国内首套电信级联机实时计费系统、国内首套三检合一的检验检疫管理系统、银行综合大前置平台(IPP)等大型系统。著有《Oracle RAC日记》、《Oracle DBA优化日记》和《DBA的思想天空》等技术专著。信息无障碍研究会专职顾问,深圳市鲲鹏产业联盟高级顾问,Oracle ACE,POSTGRESQL ACE DIRECTOR。
目前国产关系型数据库已经有上百种,比较知名的也有好几十种,其中大多数都和某些开源数据库或者开源组件有关。实际上我并不反对国产数据库基于开源代码构建,因为利用开源代码可以缩短国产数据库研发与上市的时间,缩短国产数据库与国外商用数据库的技术差距。数据库是在应用中不断磨合出来,而不是简单的研发出来的。很多朋友喜欢讲某某数据库技术很先进,用了很多新技术。如果为了满足某个用户的特殊应用场景需求而使用某些先进技术,这是没有任何问题的,而对于数据库产品来说并非如此。如果你看看Oracle数据库就是可以看出其核心的很多核心技术甚至都是三十多年前就已经成型了,其技术优势的来源是这些年不断满足用户需求的功能迭代。
我们分析国产数据库的源头并不是为了证明哪个数据库是开源套壳的,因为我并不反对国产数据库拥抱开源生态,只要数据库厂商在开源代码上叠加了自己的技术和价值,哪怕只有简单的服务,都是应该得到尊重的,数据库产品的价值取决于数据库厂商能够给与用户的价值。

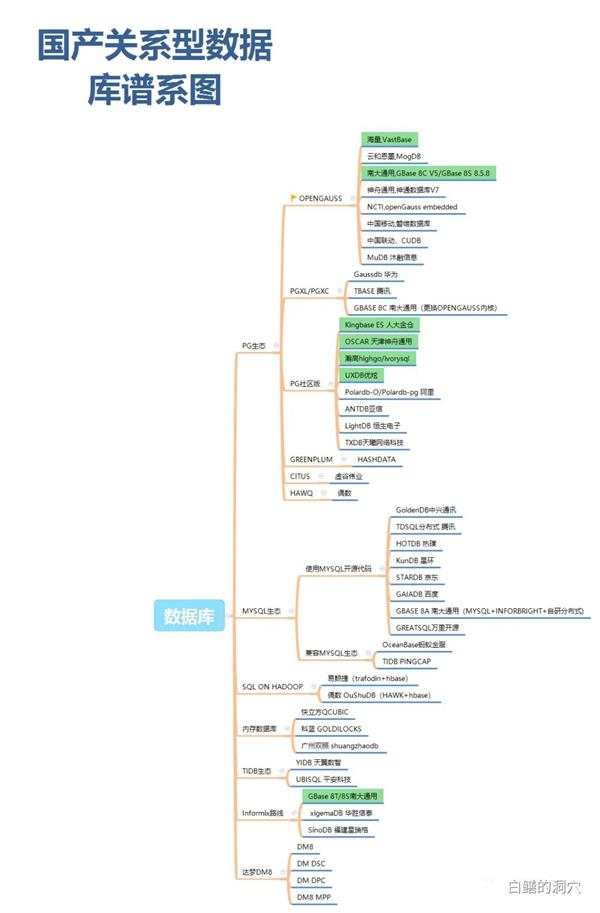
上图是2022年我们对部分国产数据库的技术来源进行分析统计的结果,数据来源是截至与2021年7月的工信部白皮书。其中基于PG和Mysql两大开源项目的国产数据库产品接近60%。在我对国产数据库的谱系分析的时候也看到,几乎所有的国产数据库厂家都在开源数据库上进行了一定的研发改造,或者加入了自己的核心代码。
一部分数据库厂家的产品来源于开源代码,不过目前已经于开源社区的代码脱离独立发展,今后很难把开源社区的一些新技术直接引入自己的数据库产品了,比如Gaussdb和openGauss已经完全脱离了开源的PG和PGXC,已经只能独立往前发展了。而另一部分厂家在对自己的数据库产品做封装的时候十分谨慎,保持着与开源社区代码的兼容性,这样他们可以继续跟上开源社区的脚步。
数据库产品的成功绝对不是技术堆叠的成功,而是需要有大量的应用场景磨合才能逐步成功的。如果仅仅依靠自己那几百个用户,想要发展出成熟的高水平的商用数据库产品来,那几乎是不太能的。依靠开源社区的广大用户来研发自己的数据库产品不失为一种比较好的策略。
打造国产数据库开源生态也是一种十分不错的策略,从今年的鲲鹏开发者大会上可以看到,拥抱openGauss开源社区的企业越来越多。利用华为巨大的研发投入抱团取暖,把国产的openGauss开源社区做好做大,也是国产数据库发展的一条不错的道路。
国产数据库种类繁多,来源各异,因此把国产数据库的家谱搞清楚也不是一件容易的事情,昨天一个朋友画了一张信创数据库的图,让我帮忙看看是否正确。从中受到启发,我画了一张更全的国产数据库谱系图,我会把它附在本文的结尾处。本图仅仅是我个人的认知,并不权威。因此图中可能存在一些疏漏,如果大家发现问题,可以留言告诉我。
画这张谱系图也并不是为了证明大多数国产数据库是开源套壳,刚才我就说过我十分赞成国产数据库拥抱开源社区。实际上国产数据库厂商对是否使用了开源代码往往遮遮掩掩是很没必要的。在自己产品中大胆的声明基于开源代码也没啥丢脸的,反而是正确的声明开源代码是尊重知识产权的表现。你如果去看看Oracle的版权声明,会发现,Oracle数据库的代码中也使用了大量的开源代码。
正确的声明开源代码,不仅仅是国产数据库在尊重知识产权方面的表现,也为用户能够能更好的选型数据库和使用数据库提供了便利。如果某个用户以前大量使用过PG数据库,那么他们在XC数据库选择的时候,选择一个和PG数据库有渊源的商用数据库产品是不是更合适一些呢?如果我是企业的IT主管,我肯定会这么考虑。
图片
