本文来自微信公众号“人民中科研究院”,作者/任轲正。
ChatGPT在全球掀起热潮以来,国内已有多家公司发布或将发布自己的大模型,据统计,国内目前已有超30个大模型亮相。既有阿里巴巴、百度、京东、华为等互联网或科技大厂,也有以商汤为代表的AI公司,以及备受瞩目的初创企业,比如王慧文的光年之外,王小川的百川智能等。
所以有人说,“最近大模型的涌现,比大模型能力的「涌现」都要快。”
1
什么是大模型的涌现能力
复杂系统学科里已经对涌现现象做过很久的相关研究。当一个复杂系统由很多微小个体构成,这些微小个体凑到一起,相互作用,当数量足够多时,在宏观层面上展现出微观个体无法解释的特殊现象,就可以称之为“涌现现象”。
在日常生活中也有一些涌现现象,比如雪花的形成、堵车、动物迁徙、涡流形成等。这里以雪花为例来解释:雪花的构成是水分子,水分子很小,但是大量的水分子如果在外界温度条件变化的前提下相互作用,在宏观层面就会形成一个很规律、很对称、很美丽的雪花。

涌现放在大模型的语境里,指的是模型在突破某个规模时,出现了意想不到的能力。
复旦大学计算机科学技术学院教授、MOSS系统负责人邱锡鹏在接受媒体采访时表示,ChatGPT的革命性体现在大模型的“涌现能力”上。据悉,在训练计算量大概在10的22次方之后,模型能力会完成从量变到质变的飞跃,呈现出惊人的爆发式增长。
当模型规模较小时,模型的性能和参数大致符合比例定律,即模型的性能提升和参数增长基本呈线性关系。然而,当GPT-3/ChatGPT这种千亿级别的大规模模型被提出后,人们发现其可以打破比例定律,实现模型能力质的飞跃。这些能力也被称为大模型的“涌现能力”。
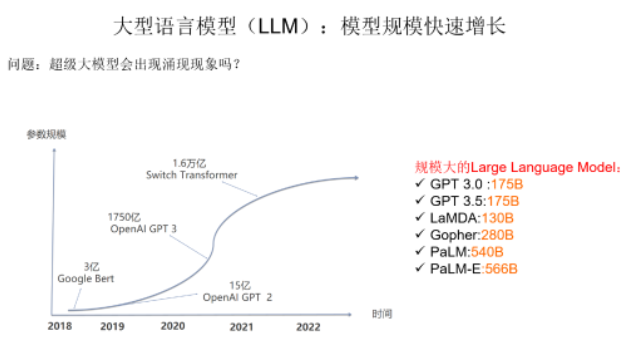
大语言模型参数增长示意图
涌现能力的背后,则进一步隐含着三个非常重要的技术:情景学习、思维链和指令学习,这也是ChatGPT得以在人工智能领域叱咤风云的关键原因。
情景学习深刻改变了传统机器学习的范式,只需要通过一系列精心设计的提示语句(Prompt),对任务进行详细描述,然后再辅以一些情景例子,就能够让模型参考着既定例子完成特定任务。
思维链则使得模型具有了推理的能力,让本来模型不会解的一个个复杂问题,分解成很多简单问题,然后通过逐一解决简单问题,最终使得复杂问题同样迎刃而解。
指令学习则使模型能够理解并执行各种自然语言指令,将任务指令化以便机器理解。人类只需要在少量的任务上进行指令化,在经历大概40多个任务指令化之后,对模型进行适度微调,就很容易泛化到上百、上千种任务,即使它从来没有见过。

2
大模型进化加速,高质量数据成差异化竞争关键
大模型竞相绽放还反映了一个信息:至少从表面上看,大模型不再稀缺。数据、算法、算力是AI能力三要素。AI大模型包含“预训练”和“大模型”两层含义,大数据是其“隐式知识库”。数据是AI大模型输入的源头和输出的结果,贯穿人工智能的整个生命周期,而算力则是训练模型的关键基础设施之一,为其快速发展提供坚实支撑。
“有大模型”不难,难的是“有一个能持续迭代,性能不断提升的优质大模型”。一些观点也提到,决定大模型发展的关键要素是高质量数据,尤其是在大模型“百花齐放”的背景下,数据是“胜负手”。

就国内数据市场而言,据国家发改委官方批露,我国政府数据资源占全国数据资源的比重超过3/4,但开放规模不足美国的10%,个人和企业可以利用的规模更是不及美国的7%。因此,加强公共数据的开放开发,是当前急需落实的核心问题,而国家数据局的组建有望从数据源头加快重要政务部门、重点关键行业的数据分类、确权进程。
此外AIGC算法日新月异,更加证明数据要素在当今的重要性。有分析指出,Meta发布基础模型SAM并开源。SAM已在1100万张图片和11亿个掩码的数据集上进行了训练,具有超强的自动识别、切割功能。SAM使用的1100万张图片训练集仅是一个开始,未来随着用户数量增加,SAM的图片训练量和分割掩码体量会呈指数级增长,因此数据要素的价值应得到持续关注。

3
我国数据要素市场体系已初步形成
近期,国内多地政府频出数据政策,加速数字化建设。同时,多地数据交易所动作频频。
4月4日,广州数据交易所通过建设算力发布共享平台,推动算力一体化协同,赋能数字经济发展,积极融入国家东数西算工程全国一体化算力布局。广州数据交易所即将推出的算力发布共享平台,是国内首个“1+1”场景式算力资源类平台。
4月3日,《2023年河南省大数据产业发展工作方案》印发,其中提到,今年争创5个以上国家级大数据产业发展试点示范项目,支持郑州数据交易中心创建国家级数据交易场所。
早前,贵州省大数据发展管理局发布《关于印发面向全国的算力保障基地建设规划的通知》。其中提到,大数据交易市场规模从目前的3亿元要提高至2025年的100亿元,增幅达到32倍。

目前,我国数据要素市场体系已经初步形成。国家工业信息安全发展研究中心发布的《2022年数据交易平台发展白皮书》显示,截至2022年8月,全国已成立44家数据交易机构,平台的注册资本多数介于5000万元至1亿元之间。
综合来看,在政策的大力推动和各方面参与者的不懈努力下,我国数据要素市场体系已经初步形成。另一方面,我国的数据要素市场正处于蓬勃发展过程中,同时也面临数据确权、数据分类分级、数据流通交易过程的安全保障、数据流通交易机制等挑战。随着我国数据要素产业法律法规、行业标准持续完善,数据交易所数量的持续扩容,数据要素产业发展有望加速。
责编:岳青植
监制:李红梅
文章参考:
1.《专访复旦大学MOSS系统负责人邱锡鹏:ChatGPT的革命性体现在大模型的“涌现能力”》21世纪经济报道
2.《大语言模型密集涌现,专家认为:人工智能永远不会跟人的智能画等号》科技日报
3.《国产大模型扎堆发布业内:数据将成为差异化竞争关键》第一财经
4.《ChatGPT浪潮下,看中国大语言模型产业发展》艾瑞咨询
5.《ChatGPT类大语言模型为什么会带来“神奇”的涌现能力?》CSDN
