本文来自微信公众号“半导体行业观察”。
在数据中心领域,如果InfiniBand刚刚成为无处不在的I/O交换结构标准,那么客户的情况可能会更好。
但是这并没有在所有人身上发生,有几个值得注意的例外,InfiniBand被用作一种系统主干(我们记得是IBM、Sun Microsystems和Unisys),但InfiniBand幸存下来要归功于一些初创公司(SilverStream/QLogic/Intel/Cornelis Networks和Mellanox/Nvidia),并且仅作为分布式计算系统中以太网的高性能、低延迟替代方案。

由于远程直接内存访问(RDMA:Remote Direct Memory Access),InfiniBand在高性能计算方面发挥了多种作用,它允许通过InfiniBand网络将数据从一台服务器的内存直接移动到另一台服务器,而无需通过网络驱动程序堆栈每个服务器的操作系统。RDMA是InfiniBand低延迟的原因,显然它在与消息传递接口(MPI:Message Passing Interface)协议结合使用时非常强大,可在分布式系统中跨CPU内核和GPU流式处理多处理器分配工作负载。
有两种尝试将InfiniBand的优势融合到以太网中。第一个是iWARP,它将本质上是InfiniBand RDMA协议块的克隆放在以太网网络适配器上,为以太网TCP/IP处理提供硬件加速,从而消除了使用以太网的大部分操作系统开销。卸载TCP/IP堆栈既困难又昂贵(在计算和经济上),因此iWARP从未得到太多关注。(现在,十年后,由于摩尔定律甚至放缓,我们可以拥有fat DPU。)
但是让以太网更像InfiniBand的想法并没有消失。十多年前,RDMA over Converged Ethernet或RoCE出现,将类似InfiniBand的传输层添加到UDP协议中,UDP协议也是以太网堆栈的一部分。RoCE于2015年首次起飞,当时许多新事物也都在发生。从那时起,人们一直在抱怨RoCE——尤其是超大规模和云构建者,还有一些HPC jet set——这推动了RoCE创新向前发展。
但是一组HPC和网络ASIC设计名人刚刚发布了一篇非常有趣的论文——Datacenter Ethernet And RDMA:Issues At Hyperscale。在文章中谈及了HPC模拟和建模、AI训练和推理以及大规模运行的存储工作负载在RoCE和他们需要修复。但更重要的是,作者认为现在是真正融合HPC和超大规模数据中心结构的时候了。
“数据中心在过去十年中经历了巨大的增长,连接机器的数量超过了当今最大的超级计算机的规模,”作者写道,这是我们一段时间以来看到的最大的轻描淡写之一,鉴于如果谷歌、AWS或微软中的任何一个愿意,它们都可以独自拥有整个超级计算500强排名。也许只有几个地区。“虽然仍存在一些差异,但此类超大规模数据中心和超级计算机的网络要求非常相似。然而,传统上超级计算机使用专用互连进行连接,而数据中心则建立在以太网上。由于相似的要求和规模经济,随着每一代新技术的出现,两者的联系越来越紧密。
如果我们都足够努力地梦想,并通过某种标准机构一起实现,也许我们可以获得我们都想要的InfiniBand。(好吧,不是思科。)CXL不是必需的,因为它已经内置了几十年。当您看着墙上所有漂亮的灯光并感觉与地球融为一体时,咀嚼一会儿。
THE UPPER ECHELON
对于大多数企业来说,大多数时候,服务器上的10 Gb/秒甚至25 Gb/秒端口都可以,而PC的10 Gb/秒端口就足够了。令人疯狂的是,10 Gb/秒和更慢的以太网交换设备在世界上的销量仍然如此之高,这就是原因。
但对于市场的一部分——推动创新的部分以及交换机ASIC制造商和交换机制造商收入流中越来越大的一部分——100 Gb/秒以太网是最低限度,如果他们可以拥有PCI-Express 6.0插槽和今天的800 Gb/秒以太网端口,他们会拿走它们并抱怨一下,但每个端口要支付成千上万美元才能获得它们。该论文的作者认为,他们的应用程序——HPC、人工智能和存储——正在推动100倍的带宽和10倍的消息速率,并且“几十年前对负载平衡、拥塞控制和错误处理的简单假设不适用于今天的网络。”
如果有的话,这篇论文说明了这样的想法,即网络确实是计算机,并且试图使像以太网这样的有损、丢包技术表现得像有序、无损的InfiniBand结构一样,涉及做出会产生意想不到的后果的不自然行为。本文多次使用感叹号,考虑到网络设计者通常将愤怒作为应对这些意外后果的唯一手段,它们是完全有道理的。
优先流控制或PFC(Priority Flow Control)是使以太网无损的解决方案,并且似乎是问题的重要组成部分。HPC、AI和存储应用程序不喜欢丢弃的数据包,而以太网被明确设计为不关心,它始终可以重新传输丢弃的数据包。这在您共享文件或在办公室打印某些东西的局域网上很好,但这种态度会使这些跨数据中心的工作负载下降并变得繁荣。使用PFC的想法是通过在交换机上放置大而昂贵的缓冲区并祈祷它们不会填满来帮助以太网不丢弃数据包。
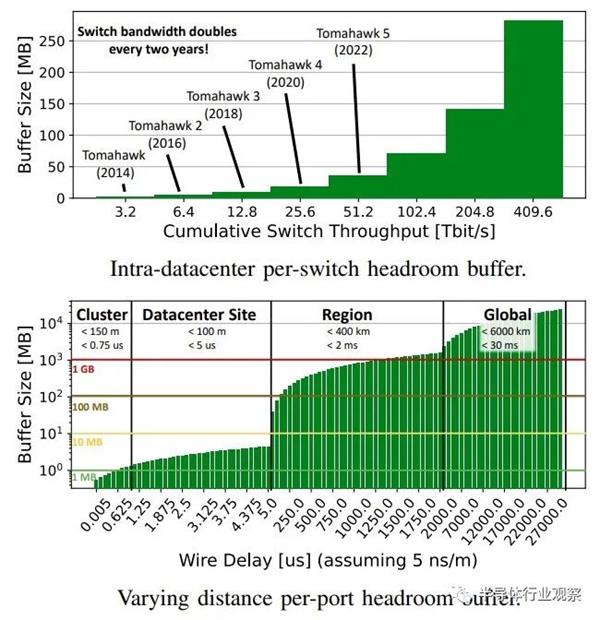
这是一个很好的,直接从论文上摘录下来的内容。
“传统上,数据中心交换机具有大(深)缓冲区以适应流量突发,而不会掉线以适应缓慢的端到端速率调整。另一方面,由于其可靠的链路级流量控制机制,HPC中使用的交换机通常在非常浅的缓冲区和严格的背压下无损运行。此外,HPC网络拓扑的直径通常低于数据[中心部署。因此,HPC部署支持低延迟操作,因为小数据包不太可能在较长流后面的缓冲区中等待。具有RoCE的数据中心网络通常将两者低效地结合在一起:它们使用无损传输,但存在相对较大的缓冲交换机的所有问题。因此,许多现代拥塞控制机制旨在保持缓冲区占用率普遍较低,让这种非常昂贵的资源闲置!”
这是一种会让分布式系统架构师发疯的事情。
另一件需要looksee的事情是前向纠错,或FEC,以及未来的Etherband,这是对此的另一个可能名称。(Infininet也适用。)
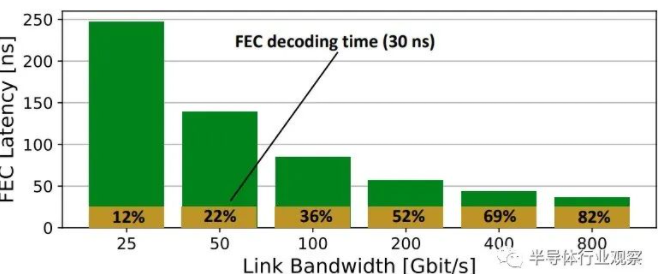
如您所见,为了支持更高的带宽,我们将在端口上提高信号速率,并且FEC的延迟必须降低。但正如您所见,FEC解码占用了越来越多的总FEC延迟,并且可能需要更复杂的FEC机制来增加更多延迟。(我们注意到,正如该论文所说,PCI-Express 6.0和7.0提出了一种新颖的编码和纠错方式,我们认为它可能会被以太网和InfiniBand所采用。)
论文中的下图很有趣,因为它显示了带宽延迟乘积——字面意思是数据链路容量(以比特每秒为单位)乘以往返延迟时间(以秒为单位)。保持高往返时间的网络业务是有问题的,这表明Microsoft Azure HPC对InfiniBand的喜爱程度,但可能不是最高带宽。
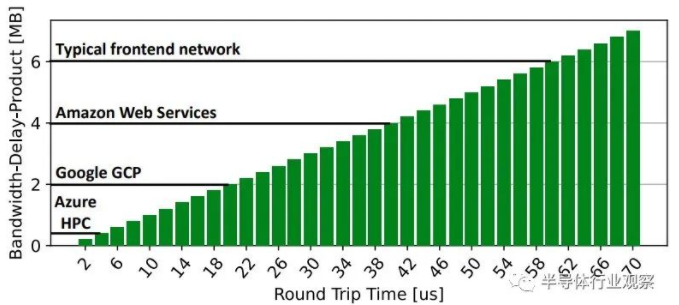
事实证明,这张图表来自另一篇论文,Hoefler是该论文的撰稿人,该论文于去年发表,名为“Noise In The Clouds:Influence Of Network Performance Variability On Application Scalability.”
鉴于论文中详细概述的众多问题,本文背后的研究人员得出以下结论:
“这种下一代以太网可能会支持RDMA连接的有损和无损传输模式,以实现智能交换机缓冲区管理。这将使净空缓冲区的配置成为可选的,并避免其他问题,例如无损网络的受害者流和拥塞树。下一代以太网也不太可能采用go back-n重传语义,而是选择更细粒度的机制,例如选择性确认。此外,它可能会使拥塞管理成为规范的一部分。将特别注意与其他流的共置,尤其是在有损流量类别中。这些协议将以灵活的方式设计,以支持智能网络堆栈,安全性最终将成为一等公民。”
我们正试图召集其中的一些研究人员,看看这实际上是如何发生的,以及何时发生。
同时,尽可能使用InfiniBand或Slingshot,必要时使用以太网。
