本文来自微信公众号“twt企业IT社区”,作者/虚幻世界。
一、企业数据中心管理运维当前面临的挑战
伴随政企数字化转型进程的推进,政企用户数据中心的规模愈发庞大,数据中心物理IT设备的种类和数量越来越多。此外,基于业务连续性方面的考虑,分布式数据中心成为越来越多客户的选择。在此背景下,数据中心的管理和运维面临着如下的挑战:
运维管理分裂
IT建设“各自为政”,缺乏统一的管理规划,服务器、存储、网络等IT资源与虚拟化平台等信息分散,系统无法集中统一管理,无法实现全栈软硬件集中管理和自动维护,运维管理成本高。
风险日益增长
管理对象和监控指标覆盖不全,告警信息无法统一管理,重要告警易遗漏,告警处理效率低下,系统风险与日俱增。
缺乏全局视图
各设备管理界面分散,缺乏全景视图,难以挖掘优化点,无法有效支撑数据中心运营分析。
故障定位困难
随着数据中心和业务规模扩大,网络复杂度不断增加,一旦出现业务故障,端到端拓扑梳理耗时长,故障定位困难,影响业务系统可用性。
二、企业数据中心全栈运维功能需求分析
某大厂曾以数据中心全栈运维为主题,对来自软件及ICT服务、运营商、制造、医疗、金融、教育、政府等行业超过250位用户展开调研,调研发现:
统一管理方面:
●89%的用户对数据中心的软硬件有软硬一体化管理的诉求,以实现故障快速定界定位。
●由于不同组织共用底层基础设施,65%的用户希望支持多租实现资源隔离,主要集中在运营商、制造、金融等行业。
资源发放方面:
●超过50%的用户资源发放频率在一周2-3次及以上,普遍反馈当前有资源发放复杂的痛点。
●61%的用户资源发放方式为管理员在云管平台上统一发放,仅14%的客户采用租户自服务的模式。
日常运维方面:
●78%的用户有大屏、报表的诉求,日常运维、上层汇报展示、参观展示均为主要使用场景。
●日常运维TOP需求包括:虚拟机间流量监控、报表大屏、流程平台对接、自动根因分析、故障快速恢复、资源动态调整。
由此可见,统一的、全栈的、智能的数据中心运维管理体系已成为当前用户数据中心运维的广泛需求,数据中心运维平台需要具备统一纳管、资源高效发放、运维可视、智能运维的功能。
统一纳管
现今企业数据中心的IT资源种类繁多,从服务器、集中式存储、分布式存储、IP交换机、FC交换机等硬件基础设施,到虚拟化、容器等资源服务,再到SDN等高阶特性,数据中心运维平台需具备软硬件全栈的统一纳管能力,实现全栈资源的统一纳管、统一门户、统一运维、统一运营。
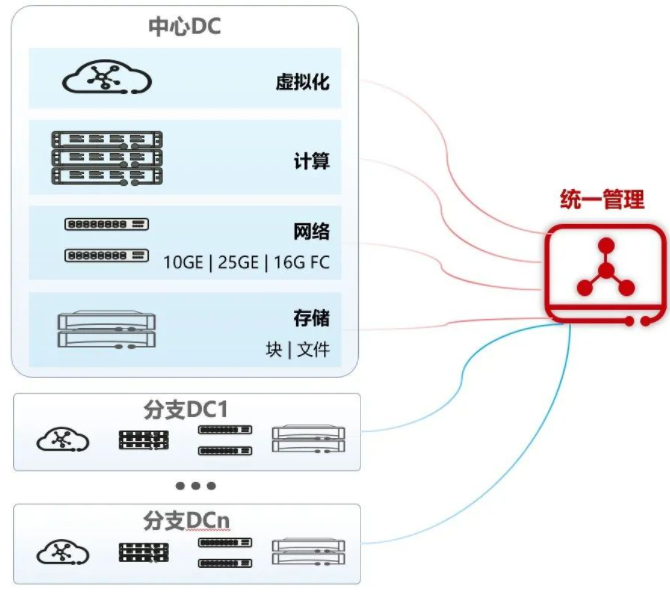
运维可视
数据中心的各种运维数据存储在不同的IT系统中,为满足日常运维的一屏统揽、客户或上级的参观展示以及数据中心的运营分析需求,需要将分散的运维数据集中展示,释放数据价值。数据中心运维平台需支持对设备性能指标、告警事件、资产配置等数据的融合关联,通过大屏或报表进行全方位的展示。大屏及报表需预制多种模板,方便运维人员的一键式导出;同时还需支持个性化定制,帮助运维人员随需掌握数据中心状态信息。
智能运维
数据中心规模日益增长,运维人员对于数据中心运维平台的智能运维提出了新的要求。对于日常运维,传统的运维方式多为被动等待问题出现后定位解决,而结合智能容量预测、智能风险检测等功能,可以提前发现问题风险并将风险消减于萌芽之中。对于故障定位,传统的运维方式需要卷入多设备的运维人员,人工梳理排查网络拓扑,在当下越发庞大和复杂的数据中心中显得效率尤为低下,通过运维平台提供的智能关联分析和智能拓扑梳理,可以快速且自动化地定位到问题关键点,故障定位时间缩短到分钟级。
资源高效发放
数据中心基础设施的计算、存储、网络等资源被不同的部门或用户使用,面对不同用户发起的资源申请需求,运维人员需频繁按照需求为用户发放资源,此时如若运维平台的资源发放过程效率低下、依赖于大量手工步骤,那么对于运维人员的日常工作必然造成困扰。以一个典型的IOE架构下的虚拟机发放过程为例,虚拟机的发放需要分别接入存储、网络、虚拟化平台的管理界面执行十数个步骤的手工操作,步骤繁杂且容易出错。因此,数据中心运维平台需要支持资源的高效发放,从人工执行转变为自动化执行,从十数个步骤转变为一键式自动编排,从而满足日常的业务发放需要。
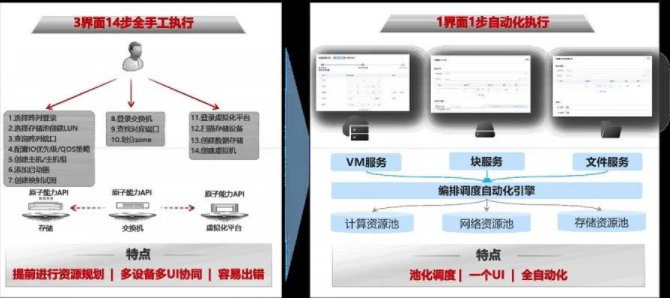
结合上述关键功能需求,面向全场景的数据中心全栈管理平台需具备融合、智能、开放三大能力:
融合
数据中心全栈软硬件管理:统一监控管理分支-中心多DC内的服务器、交换机、存储设备、虚拟化等资源,IT人员通过一个“界面”完成日常运维管理工作,统一体验,提升效率。
统一告警:软硬件告警统一实时监控与通知,帮助运维人员及时发现问题。
智能
智能风险预警:通过AI实现智能风险预测,故障提前预知,问题一键闭环。
智能性能关联分析:对虚拟机、虚拟网卡、虚拟磁盘、数据存储等的性能问题智能关联分析,快速定界性能瓶颈。
智能拓扑分析:智能拓扑梳理,图形化辅助根因分析,问题定界定位小时级缩短到分钟级。
开放
开放生态:南北向广泛兼容,北向支持对接三方云管,南向支持多厂商设备管理、异构资源池纳管。
自定义报表:掌控全网资产、资源、业务运行状况,帮助运维决策、定期汇报。
自定义大屏:预置大屏和自定义能力满足日常参观、重点业务监控保障等诉求。
结语
随着ICT技术的不断更新和发展,ICT技术已逐渐深入到社会生活的各个方面。伴随着新一轮的技术革命和产业变革,数字化转型成为政企的重中之重,数字经济蓬勃发展,以云计算、大数据等为代表的新兴技术为数据中心融合,政企数据中心的规模日益扩大。现今数据中心规模、复杂度、设备多样性等为数据中心运维带来了严峻的挑战,这对于运维平台而言是最好的时代,运维平台的重要性达到了空前的高度。
统一的、全栈的、智能的数据中心运维管理体系已成为当今用户数据中心运维的普遍需求。在全栈统一管理的基础上,结合业务高效发放以及AI技术赋予的智能故障定位、提前风险预知等能力,相信数据中心运维平台将快速从人工走向自动,最终走向全场景“自治”。
原题:数据中心全栈运维:从人工到自治
