走进一家科技展馆,AI导览机器人向你行“注目礼”;肚子饿了走进无人超市,AI售货员亲切地提醒你是否需要购物袋;不想开车了,叫一辆无人车,让“老司机”载你出行……AI正在为我们打开一个新“视”界,然而疑惑的是,AI的“眼睛”在哪儿?它是如何一步步“看懂”这个世界的呢?
一、人类的“看”与“AI的“看”,是一样的吗?
对于人类而言,“看”几乎是与生俱来的能力——出生几个月的婴儿看到父母的脸会露出笑容,暗淡的灯光下我们仍能认出几十米之外的朋友。眼睛赋予我们仅凭极少的细节就能认出彼此的能力,然而这项对于人类来说“轻而易举”的能力,对计算机来说确实举步维艰。
因为对于人类来说,“看见”的过程,往往只在零点几秒内发生,而且几乎是完全下意识的行为,也很少会出差错(比如当我们人类看到一只猫和一只狗时,尽管它们的体型很类似,但我们还是马上能够区分它们分别是猫和狗),而对计算机而言,图像仅仅是一串数据。
近几年AI技术的迅猛发展,使得“计算机视觉”成为最热的人工智能子领域之一。而计算机视觉的目标是:复制人类视觉的强大能力。
我们的大脑中有非常多的视网膜神经细胞,有超过40亿以上的神经元会处理我们的视觉信息,视觉占据着人对外界70%的感知能力,所以“看”是我们理解这个世界最重要的部分。
人类的大脑能完美地处理好这一系列的视觉信息,以此帮助我们理解世界、做出判断。当你看见一张狗的图片,你能轻松地知道这只狗的毛发、品种,甚至能大概知道它的身高体重。无论这张图片是否模糊、有噪点,或者条纹,但是AI就会“犯傻”了。
为什么会这样呢?
因为重塑人类的视觉并不只单单是一个困难的课题,而是一系列、环环相扣的过程。

二、AI的“偏爱”:纹理
研究认为,人看的是相对高层的语义信息,比如目标的形状等;计算机看的则是相对底层的细节信息,比如纹理。也就是说,一只“披着羊皮的狼”,人类与AI的意见并不相同。
AI的神经网络架构就是根据人的视觉系统开发的。德国图宾根大学科学家团队做了一组这样的实验:他们用特殊的方法对图片像素进行“干扰处理”,让像素降低,再用这个图像训练神经网络,在后续识别这些被“人为扭曲干扰”的图像时,系统的表现比人好,但是如果图像扭曲的方式稍有不同(在人眼看起来扭曲方式并无不同),算法就完全无能为力了。
到底是发生了什么变化?即便是加入极其少量的噪点,为何还是会发生如此大的变化?
答案就是纹理。当在图像中加入噪点,图中对象的形状不会受到影响,但是局部的架构会快速扭曲。
更有趣的是另一组实验。研究人员将一种动物的形状与另一种动物的纹理拼在一起,制作成图片,将一头大象的皮披在一只猪的轮廓上,或者将铁罐制作成一只小猫。他们制作几百张这种“拼接照片”,再给它们贴上“猪”、“猫咪”的标签,用不同的算法进行测试。最终,系统给出的答案是:大象、铁罐。由此更能表明,计算机确实关注的是纹理。
多伦多约克大学计算机视觉科学家JohnTsotsos指出,“线段组按相同的方式排列,这就是纹理”。
这也说明,人类与机器的“看”有明显区别。当然,随着技术的发展,算法会越来越精准,AI正在向人类视觉逐步靠近。
三、AI究竟是怎么去“看”的?
1.算法模型是AI的“大脑”
如果说人类通过“智慧的大脑”来认识世界,那么算法模型就是AI的“大脑”。
AI目标是创造设计出具有高级智能的机器,其中的算法和技术部分借鉴了当下对人脑的研究成果。很多当下流行的AI系统使用的人工神经网络,就是模拟人脑的神经网络,建立简单模型,按照不同的连接方式组成的网络。
机器正是通过复杂的算法和数据来构建模型,从而获得感知和判断的能力。
这些网络跟人脑一样可以进行学习,比如学习模式识别、翻译语言、学习简单的逻辑推理,甚至创建图像或者形成新设计。
其中,模式识别是一项特别重要的功能。因为人类的“识别”依赖于自身以往的经验和知识,一旦面对数以万计的陌生面孔,就很难进行识别了。而AI的“杀手锏”就是处理海量数据,这些神经网络具有数百万单位和数十亿的连接。
2.AI如何高度“复制”人的眼睛?
神经网络是图像处理的“得力助手”。作为计算机视觉核心问题之一的图像分类,即给输入图像分配标签的任务,这个过程往往与机器学习和深度学习不可分割。简单来说,神经网络是最早出现,也是最简单的一种深度学习模型。
深度学习的许多研究成果,都离不开对大脑认知原理的研究,尤其是视觉原理的研究。诺贝尔医学奖获得者DavidHubel和TorstenWiesel发现人类视觉皮层结构是分级的。
比如,人在看一只气球时,大脑的运作过程是:“气球”进入视线(信号摄入)——大脑皮层某些细胞发现“气球”的边缘和方向(初步处理)——判定“气球”是圆形(抽象)——确定该物体是“气球”(进一步抽象)。
那么,可不可以利用人类大脑的这个特点,构建一个类似的多层神经网络,低层的识别图像的初级特征,若干底层特征组成更上一层特征,最终通过多个层级的组合,最终在顶层做出分类呢?
答案当然是肯定的。这也就是深度学习系统中最重要的一个算法——卷积神经网络(CNN)的灵感来源。
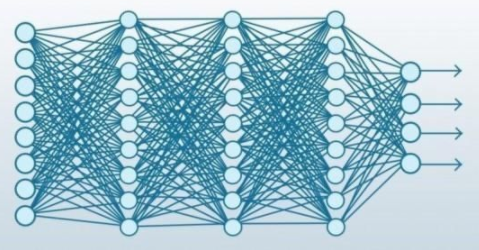
CNN具有输入层、输出层和各种隐藏层。其中一些层是卷积的,它将结果经过分析,再传递给连续的层。这过程模拟了人类视觉皮层中的一些动作。
由于这种特点,CNN十分擅长处理图像。同样,视频是图像的叠加,因此同样擅长处理视频内容。生活中比较常见的自动驾驶、人脸识别、美图秀秀以及视频加工等都用到了CNN。
经典的图像分类算法就是基于强大的CNN设计的。例如,一只猫的图像,对计算机来说,只是一串数据,这时候,神经网络第一层会通过特征来检测出动物的轮廓,第二层将这些轮廓组合再次检测形成一些简单形状,例如动物的耳朵、眼睛等,第三层检测这些简单形状所构成的动物身体部位,如腿、头等,最后一层检测这些部位的组合,从而形成一只完整的猫。
由此可见,每一层神经网络都会对图像进行特征检测、分析、判断,再将结果传递给下一层神经网络。实际上,比这个案例中使用神经网络的层次深度更复杂的情况,在生活中更多。
为了更好地训练AI,就需要大量的被标记的图像数据。神经网络会学习将每个图像与标签对应、联系起来,还可以将之前未见过的图像与标签进行配对。
这样,AI系统就能够梳理各种图像、识别图像中的元素,不再需要人工标记输入,让神经网络自我学习。
三、计算机视觉:一门研究“看”的学问
对于AI系统而言,处理好视觉感知如同眼睛对于人类而言是一样重要的。也正是因为视觉感知对AI的重要性,计算机视觉(CV)成为了一门研究如何使机器“看”的科学。
但是很多人容易将计算机视觉与机器视觉(MV)混淆,尽管他们有共同点,但仍有差异。
相较于机器视觉侧重于量的分析,计算机视觉主要是对质的分析,比如分类识别,这是一个苹果那是一条狗;或者做身份确认,比如人脸识别,车牌识别;或者做行为分析,比如人员入侵,徘徊,人群聚集等。
计算机视觉并不仅仅停留在浅层的感知层面,大量高级智能与视觉密不可分。如果计算机能真正理解图像中的场景,真正的智能也将不再遥远。可以说,计算机视觉本身蕴含更深远的通用智能的问题。
随着技术的不断成熟,计算机视觉的应用场景愈加广泛,从消费者到企业,计算机视觉技术在各大领域都有着一席之地。如面向消费者市场的AR/VR、机器人、无人驾驶、自动驾驶汽车等,面向企业市场的医疗图像分析、视频监控、房地产开发优化、广告插入等。
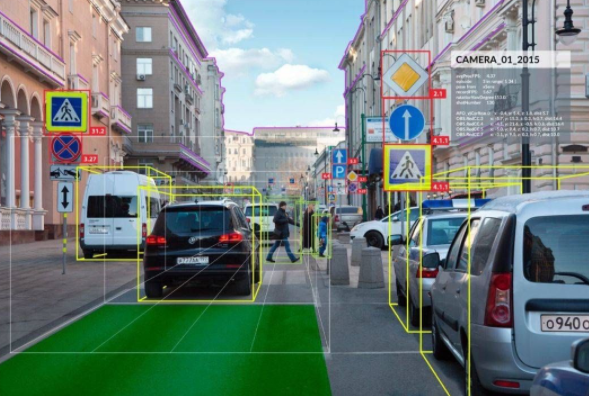
在这些已经落地的应用案例中,无法忽视的问题是很多项目都处于小范围的试用阶段。相关理论的不完善使得这些先行者与创新者遇到不少挑战。如缺少可用于AI模型训练的大规模数据集,以及动态图像识别、实时视频分析等技术瓶颈有待突破。
四、GAN算法赋予AI“想象力”
目前AI对图像的处理不仅限于进行图像分类,常见的还有AI对老旧、破损图像的修复。我们在观看一些经典的、年代久远的老电影时,往往对其“高糊画质”难以接受。
用传统的方式对这些低画质的电影进行修复,速度慢就不提,而如果遇到图像缺失部分很大的情况,传统方法也无力回天。
但是AI的效率就高了,能够通过机器学习和模型训练来填充细节,提高画质,再利用神经网络上色,最后进行转录和人脸识别,半天就完成了。对于原图像缺失的部分,AI还能“开动大脑”,发挥自己的“想象力”,对缺失部分进行补充。
AI为何能拥有这么高的“想象力”?其根本原因在于其学习能力。基于生成对抗网络(GAN)的深度学习算法,证明了计算机视觉任务在图像恢复方面具有巨大的潜力。
GAN是基于CNN的一种模型,其特点在于它的训练处于一种对抗博弈的状态中。
我们常用“球员与裁判”的比喻来解释GAN的基本原理。
在足球运动中,某些球员经常“假摔”来迷惑裁判,使得自己的进攻或者防守动作是合规的,而裁判,负责找出这些“假摔”的球员的犯规动作,做出相应惩罚。
在球员与裁判的不断对抗中,球员“假摔”的水平越来越高,裁判识别“假摔”的水平也越来越高。
终于有一天,球员“假摔”的水平已经“炉火纯青”,成功的骗过了裁判,裁判已经无法识别出该球员是“假摔”还是“真摔”,这说明该球员的水平已经实现了以假乱真。就是通过这样不断地尝试和识别,球员欺骗过了裁判,目的达到。这就是GAN的基本原理。
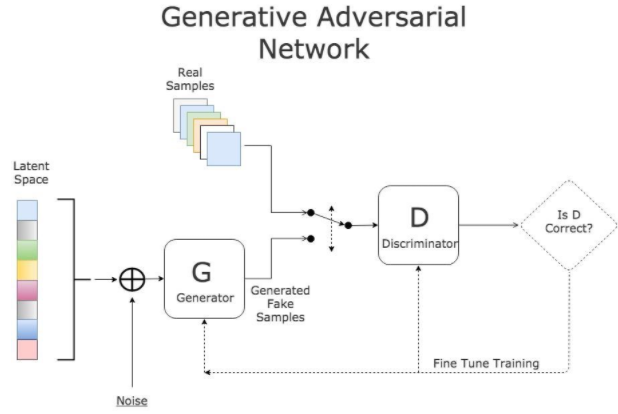
GAN的主要结构包括一个生成器(G)和一个判别器(D),上面的例子中,球员=生成器,裁判=判别器。生成器可以是任意可以输出图片的模型。同理,判别器与生成器一样,可以是任意的判别器模型。
以图片生成为例,G随机生成一张图片x,需要D来判别是不是真实的图片,D(x)代表真实图片的概率,如果D(x)为1,表示100%为真实,如果D(x)为0,则表示为假图。在理想状态下,D无法判别G生成的图片是否为真实的,
D(x)则为0.5,那么,我们的目的就达到了:得到了生成式模型G,就可以用它来生成图片。
因此,在训练过程中,G的目标就是尽量生成真实的图片去欺骗判别网络D。
而D的目标就是尽量把G生成的图片和真实的图片分别开来。这就是一个“博弈”的过程。这样,不仅可以上色,还可以将普通电影提升为高清电影。
AI在学会这个技巧之后,不需要原始照片对照也能准确地修复、重建低分辨率图像。给图像“上色”之前,AI会对图像进行分析,区分出标志性的物体,如人脸、汽车和天空等,结合色彩信息进行彩色化。

其实,这个过程就相当于训练一段程序,让它对低质量的图像进行“想象”,并非完全能实现100%的图像恢复。相较于CNN,GAN采用的是一种无监督的学习方式训练。
值得一提的是,GAN的作用不仅限于老照片上色,他在各种涉及图像风格转换的任务中都有用武之地。如自动生成动漫角色并上色、让马变成斑马、生成人脸、作曲等。总之,GAN在图像生成、处理修复领域的应用十分广泛。
五、解释性、鲁棒性,安全性的提升,让AI更了解世界
AI席卷百业,作为AI时代的主要入口之一,计算机视觉正成为AI落地规模最大、应用最广的领域。官方数据显示,2016年,我国计算机视觉市场规模仅11.4亿元,到2019年,中国计算机视觉行业市场规模增长至219.6亿元。
到2025年,全球计算机视觉市场规模,将从2016年的11亿美元增长到262亿美元。
对计算机视觉技术的研究在学术界与工业界已经掀起了热潮,在未来,随着算法的改进、硬件的升级、以及5G与物联网技术带来的高速网络与海量数据,计算机视觉技术必然会有更大的想象空间。曾经,人类用眼睛“记录”了波澜壮阔的历史,未来,AI能够真正的像人类一样去“观察”世界吗?
遗憾的是,从目前来看,即便我们已经创造了许多在单个项目上已经超越人类的高级AI,但是这些机器仍然能力有限,它还无法成为人类的替代品,无法像人类一样去观察与思考,有自我意识的AI还不会很快出现,AI很难真正像人类一样去“看”世界万物。
即便如此,我们也不能否认AI的解释性、鲁棒性,安全性等正在不断提升,AI将在越来越“了解”这个丰富多彩的世界的同时,帮助我们的更高效、智能的完成更多工作,人类与AI将一起创造更多彩、更智慧的世界。
【参考资料】
[1]维科网一文读懂AI计算机视觉技术,“视觉五虎将”值得关注,
https://www.ofweek.com/ai/2018-09/ART-201716-8140-30265610.html
[2]MomozhongAI赋能视觉技术,五大应用市场机遇多,
https://www.esmchina.com/news/6851.html
[3]杨铮图像标签的算法原理和应用,
https://zhuanlan.zhihu.com/p/103674228
[4]机器之心计算机视觉,
https://www.jiqizhixin.com/graph/technologies/6e614199-9e49-450e-9078-61fb2b122da9
[5]人工智能知识库一文看懂计算机视觉-CV(基本原理+2大挑战+8大任务+4个应用)https://medium.com/ pkqiang49
[6]许春景计算机视觉:机器如何看懂世界?
https://www.huawei.com/cn/publications/winwin-magazine/ai/computer-vision-see-world
[7]微软亚洲研究院计算机视觉:让冰冷的机器看懂这个多彩的世界,
https://www.msra.cn/zh-cn/news/features/computer-vision-20150210
[8]周小松2020年中国计算机视觉行业市场现状及发展前景分析人工智能引爆计算机视觉
https://www.qianzhan.com/analyst/detail/220/201218-c62b8f33.html
[9]元峰深度学习在计算机视觉领域的前沿进展
https://zhuanlan.zhihu.com/p/24699780
[10]人工智能进化论十分钟了解人工智能AI的基础运作原理
https://cloud.tencent.com/developer/news/296050
[11]萝卜兔神奇的图像修复大法,AI想象力的开启
https://cloud.tencent.com/developer/news/278597
[12]Double_V_GAN原理,优缺点、应用总结
https://blog.csdn.net/qq_25737169/article/details/78857724
[13]博客园卷积神经网络预备知识
https://www.cnblogs.com/charlotte77/p/7759802.html
