局部性原理
一个编写良好的计算机程序,它们倾向于引用邻近于其他最近引用过的数据项的数据项,或者最近引用过的数据项本身,我们称这种程序具有良好的局部性。这种倾向性,我们称之为局部性原理,是一个持久的概念,对于硬件和软件系统的设计和性能都有着极大的影响。
在一个具有良好时间局部性的程序中,被引用过一次的存储器在不远的将来会被再次引用。在一个具有良好空间局部性的程序中,如果一个存储器位置被引用了一次,那么程序很可能在不远的将来引用附近的一个存储器的位置。
在硬件层,局部性原理允许计算机设计者通过引入称为高速缓存存储器的小而快速的存储器来保存最近被引用的指令和数据项,从而提高对主存的访问速度。在操作系统级,局部性原理允许系统使用主存作为虚拟地址空间最近被引用块的高速缓存。
Cache
cache,中译名高速缓冲存储器,其作用是为了更好的利用局部性原理,减少CPU访问主存的次数。简单地说,CPU正在访问的指令和数据,其可能会被以后多次访问到,或者是该指令和数据附近的内存区域,也可能会被多次访问。因此,第一次访问这一块区域时,将其复制到cache中,以后访问该区域的指令或者数据时,就不用再从主存中取出。
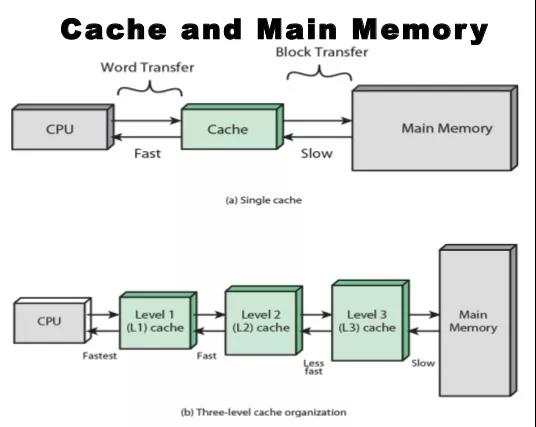
下图显示了典型的计算机或者服务器组成中存储的层次结构。
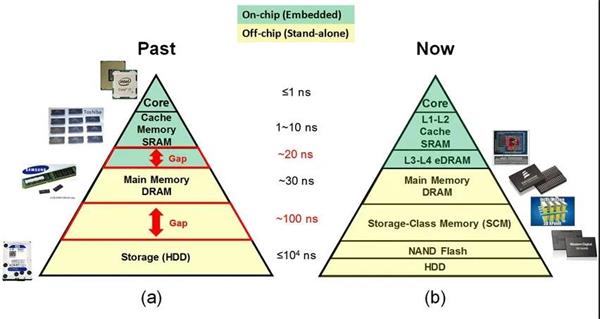
从上图中也可以看出Cache弥补了CPU与内存之间的巨大访问速度差异,而SCM弥补了内存和磁盘之间的巨大访问速度差异。
Cache组成
现代CPU大多数都采用多级缓存机制,常见是3级缓存机制,即L1 Cache,L2 Cache,L3 Cache。L1 Cache紧连着CPU,L2 Cache接着L1 Cache,L3 Cache连接着L2 Cache和内存。
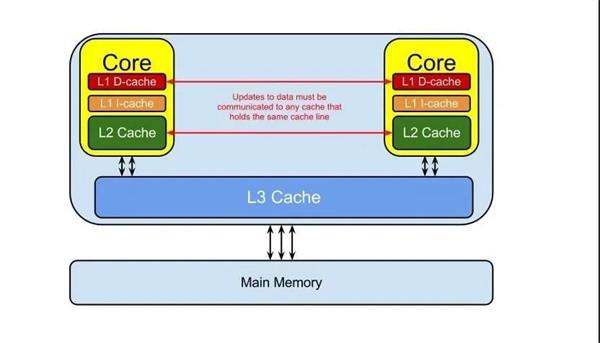
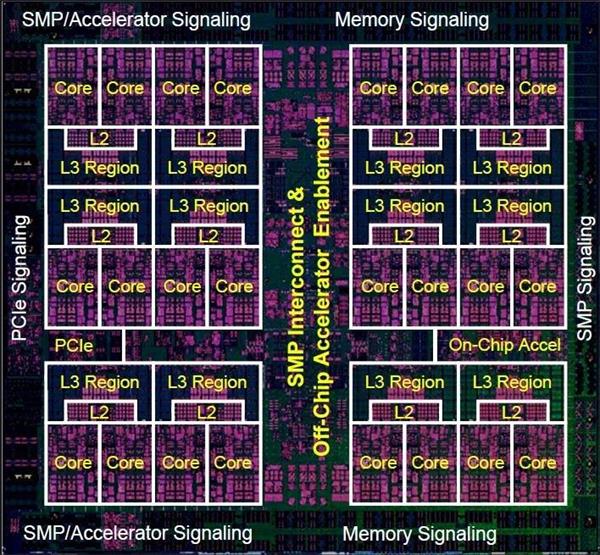
下图是Power9 CPU的一个示意图,可以看出L1 Cache/L2 Cache/L3 Cache的分布。
其中L1 Cache是在每个Core的内部。
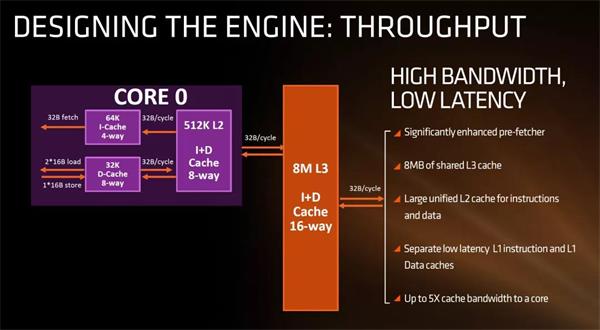
L1 Cache
L1 Cache是比较特殊的,因为它又由数据缓存L1 Data Cache俗称D-Cache和指令缓存L1 Instruction Cache俗称I-Cache组成。其中I-Cache还承担着分支预取的功能,尤其在类似循环操作的时候,提前把下一个指令放到I-Cache中,这时I-Cache看起来很像Input-Cache。
Inclusive Cache vs Non-Inclusive Cache
为了让问题简单化,只考虑L1 Cache和L2 Cache。
Inclusive Cache
简单说来,如果L2 Cache(low level cache)包含所有L1 Cache(high level cache)中的数据,那么把L2 Cache叫做L1 Cache的Inclusive Cache(全包含Cache)。
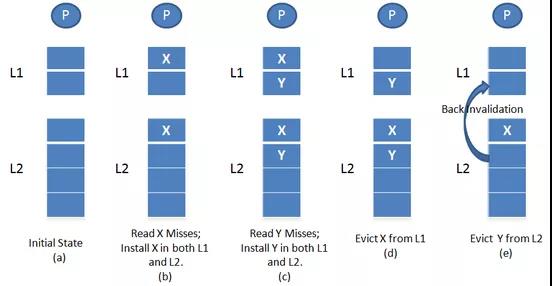
上图L2 Cache是Inclusive Cache,如果Y在L2 Cache中不再存在,L2 Cache会通知L1 Cache,把Y也删除。
Non-Inclusive Cache
简单说来,如果L2 Cache(low level cache),只包含L1 Cache(high level cache)中没有的数据,那么把L2 Cache叫做L1 Cache的Non-Inclusive Cache(非包含Cache)。
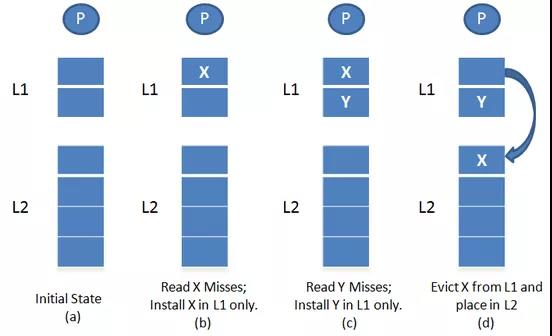
上图L2 cache是Non-Inclusive Cache。L2 Cache只有L1 Cache中没有的数据。
Inclusive Cache多了一个“Back Invalidation”,很多时候,Inclusive Cache会慢一点。
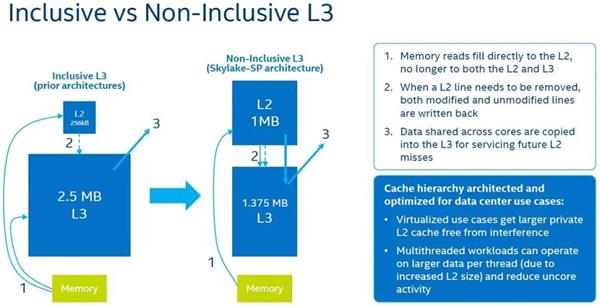
一个典型的代表是Intel Skylake对于L3 Cache的修改,将其从之前的Inclusive Cache修改为Non-Inclusive Cache。
Cache Line
cache line:每次内存和CPU缓存之间交换数据都是固定大小,cache line就表示这个固定的长度。
cache set:一个或多个cache line组成cache set,也叫cache row。
Cache Hit/Cache Miss
cache hit:缓存命中,查找的地址在cache中。
cache miss:缓存未命中,查找的地址不在cache中。
hit rate:命中率,cache hit/(cache hit+cache miss)
Cache分配策略
Cache Allocation Policy是指我们什么情况下应该为数据分配cache line。cache分配策略分为读和写两种情况。
读分配(read allocation)
当CPU读数据时,发生cache缺失,这种情况下都会分配一个cache line缓存从主存读取的数据。默认情况下,cache都支持读分配。
写分配(write allocation)
当CPU写数据发生cache缺失时,才会考虑写分配策略。当我们不支持写分配的情况下,写指令只会更新主存数据,然后就结束了。当支持写分配的时候,我们首先从主存中加载数据到cache line中(相当于先做个读分配动作),然后会更新cache line中的数据。
Cache更新策略
Cache Update Policy是指当发生cache命中时,写操作应该如何更新数据。cache更新策略分成两种:写直通和回写。
写直通(write through)
当CPU执行store指令并在cache命中时,我们更新cache中的数据并且更新主存中的数据。cache和主存的数据始终保持一致。
写回(write back)
当CPU执行store指令并在cache命中时,我们只更新cache中的数据。并且每个cache line中会有一个bit位记录数据是否被修改过,称之为dirty bit。我们会将dirty bit置位。主存中的数据只会在cache line被替换或者显示的clean操作时更新。因此,主存中的数据可能是未修改的数据,而修改的数据躺在cache中。cache和主存的数据可能不一致。
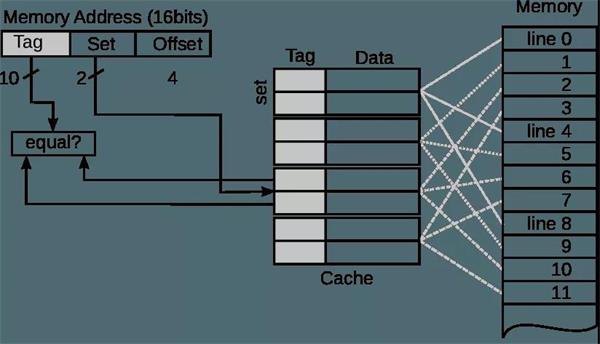
缓存映射Cache Mapping
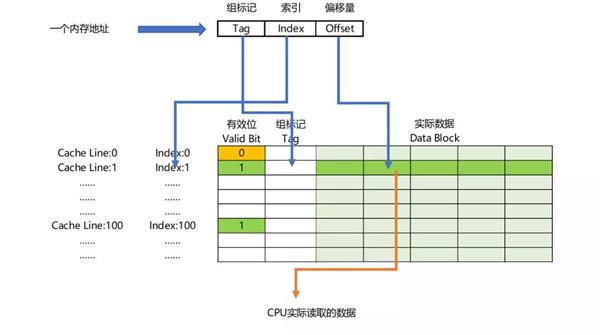
很明显,Cache的大小远小于内存的大小,那么Cache和内存之间如何进行映射即Cache地址怎样去对应内存中的地址呢?使用的机制就是缓存映射Cache Mapping。
在讲述常见的缓存映射机制前,需要复习一下Cache Line的概念。
将cache平均分成相等的很多块,每一个块大小称之为cache line,其大小是cache line size。例如一个64 Bytes大小的cache。如果我们将64 Bytes平均分成64块,那么cache line就是1字节,总共64行cache line。如果我们将64 Bytes平均分成8块,那么cache line就是8字节,总共8行cache line。现在的硬件设计中,一般cache line的大小是4-128字节。常见的如x86的Cache Line为64字节,而ARM和Power9的Cache Line为128字节。
有一点需要注意,cache line是cache和主存之间数据传输的最小单位。什么意思呢?当CPU试图load一个字节数据的时候,如果cache缺失,那么cache控制器会从主存中一次性的load cache line大小的数据到cache中。例如,cache line大小是64字节。CPU即使读取一个byte,在cache缺失后,cache会从主存中load 64字节填充整个cache line。
直接映射缓存Direct Mapped Cache
假设Cache的大小为64字节,Cache Line的大小为8字节,那么整个Cache就分成了64/8=8 Line。假设内存大小为512字节,同样按照Cache的大小将其分成512/64=8 block,每一份叫做一个块(block),每个block里面也是按照Cache Line的大小分为64/8=8 Line。将每个block的第一个Line和Cache中的第一个Line对应起来,以此类推,这种方法就叫做Direct Mapped Cache。下图是Direct Mapped Cache的示例。
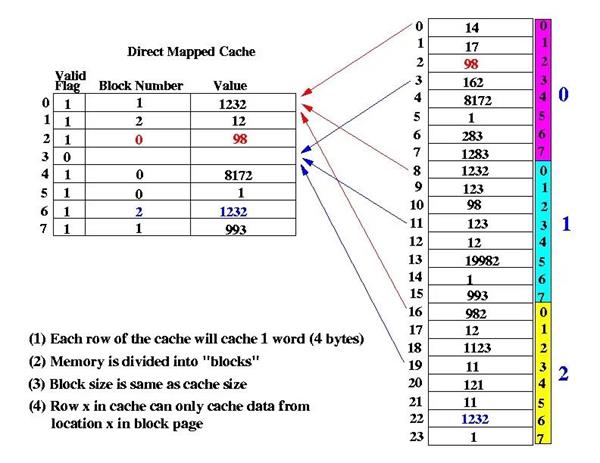
直接映射缓存在硬件设计上会更加简单,因此成本上也会较低。但是直接映射缓存存在一个称为“Cache颠簸(Cache Thrashing)”的问题,举个例子,如果我们恰好要访问内存中每个block的第一个Line,由于它们都被映射到了Cache的第一个Line,所以每次都不会命中,而是不停从内存中加载到Cache中,此时,Cache对于性能提升就毫无帮助。
组相联缓存Set Associative Cache
依然假设Cache大小是64字节,Cache Line大小是8字节,内存大小是512字节。
在解释组相联缓存之前,还需要了解Way(路)的概念。
将Cache平均分为几份,每一份就叫做一组(Set)。而每一个Set里面包含几个Cache Line,可以称为几路(Way)。
假设将Cache平均分为4份,也就是4组,那么每一组就是64/4=16字节。每一组包含16/8=2 Line即2个Cache Line,就是2路,命名为way-0,way-1。而此时内存划分block时,需要保证每个block里面包含的Line数等于Cache的组数4。相当于划分为512/(4*8)=16 block,每个block包含4个Cache Line。
主存中的各块与Cache的组号之间有固定的映射关系,但可自由映射到对应Cache组中的任何一路。例如,主存中的第0块、第4块……均映射于Cache的第0组,但可映射到Cache第0组中的way-0或way-1;主存的第1块、第5块……均映射于Cache的第1组,但可映射到Cache第1组中的way-0或way-1。
常采用的组相联结构Cache,每组内有2、4、8、16路,称为2路、4路、8路、16路组相联Cache。
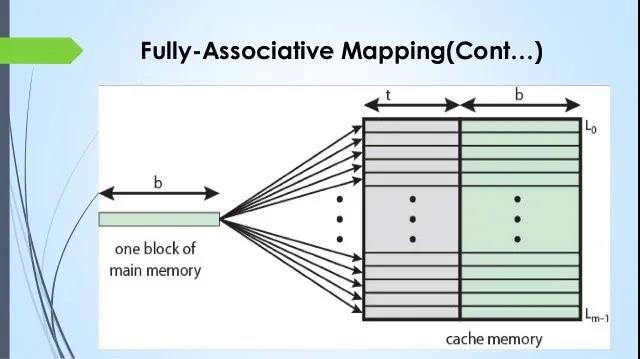
全相联缓存Full Associative Cache
全相联缓存,将整个Cache看做一个组(set),也就是不再分组,其实是组相联缓存的特殊情况。在全相联缓存中,任意地址的数据可以缓存在任意的cache line中。所以,这可以最大程度的降低cache颠簸的频率。但是硬件成本上也是更高。
组相联结构Cache是直接映射和全相联映射的折中方案,适度兼顾二者的优点,尽量避免二者的缺点,因而得到普遍采用。
最后,是个小测试:
Que-1:A computer has a 256 KByte,4-way set associative,write back data cache with the block size of 32 Bytes.The processor sends 32-bit addresses to the cache controller.Each cache tag directory entry contains,in addition,to address tag,2 valid bits,1 modified bit and 1 replacement bit.The number of bits in the tag field of an address is
(A)11
(B)14
(C)16
(D)27
Answer:(C)
Explanation:https://www.geeksforgeeks.org/gate-gate-cs-2012-question-54/
Que-2:Consider the data given in previous question.The size of the cache tag directory is
(A)160 Kbits
(B)136 bits
(C)40 Kbits
(D)32 bits
Answer:(A)
Explanation:https://www.geeksforgeeks.org/gate-gate-cs-2012-question-55/
Que-3:An 8KB direct-mapped write-back cache is organized as multiple blocks,each of size 32-bytes.The processor generates 32-bit addresses.The cache controller maintains the tag information for each cache block comprising of the following.
1 Valid bit
1 Modified bit
As many bits as the minimum needed to identify the memory block mapped in the cache.What is the total size of memory needed at the cache controller to store meta-data(tags)for the cache?
(A)4864 bits
(B)6144 bits
(C)6656 bits
(D)5376 bits
Answer:(D)
Explanation:https://www.geeksforgeeks.org/gate-gate-cs-2011-question-43/
参考链接:
https://www.hardwaretimes.com/difference-between-l1-l2-and-l3-cache-what-is-cpu-cache/
https://www.geeksforgeeks.org/cache-memory-in-computer-organization/
https://zhuanlan.zhihu.com/p/102293437