AR从其技术手段和表现形式上,可以明确分为大约两类,一是Vision based AR,即基于计算机视觉的AR,二是LBS basedAR,即基于地理位置信息的AR。
Vision based AR
基于计算机视觉的AR是利用计算机视觉方法建立现实世界与屏幕之间的映射关系,使我们想要绘制的图形或是3D模型可以如同依附在现实物体上一般展现在屏幕上,如何做到这一点呢?本质上来讲就是要找到现实场景中的一个依附平面,然后再将这个3维场景下的平面映射到我们2维屏幕上,然后再在这个平面上绘制你想要展现的图形,从技术实现手段上可以分为2类:
1、 Marker-Based AR
这种实现方法需要一个事先制作好的Marker(例如:绘制着一定规格形状的模板卡片或者二维码),然后把Marker放到现实中的一个位置上,相当于确定了一个现实场景中的平面,然后通过摄像头对Marker进行识别和姿态评估(Pose Estimation),并确定其位置,然后将该Marker中心为原点的坐标系称为Marker Coordinates即模板坐标系,我们要做的事情实际上是要得到一个变换从而使模板坐标系和屏幕坐标系建立映射关系,这样我们根据这个变换在屏幕上画出的图形就可以达到该图形依附在Marker上的效果,理解其原理需要一点3D射影几何的知识,从模板坐标系变换到真实的屏幕坐标系需要先旋转平移到摄像机坐标系(Camera Coordinates)然后再从摄像机坐标系映射到屏幕坐标系。
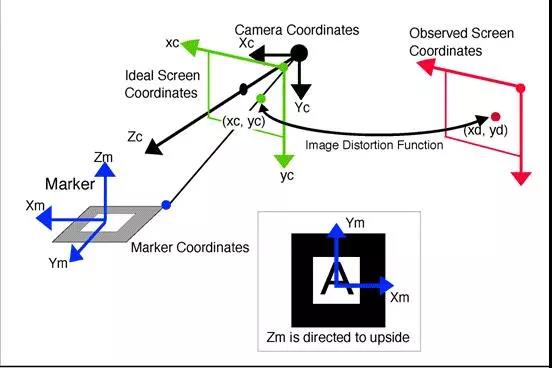
在实际的编码中,所有这些变换都是一个矩阵,在线性代数中矩阵代表一个变换,对坐标进行矩阵左乘便是一个线性变换(对于平移这种非线性变换,可以采用齐次坐标来进行矩阵运算)。公式如下:
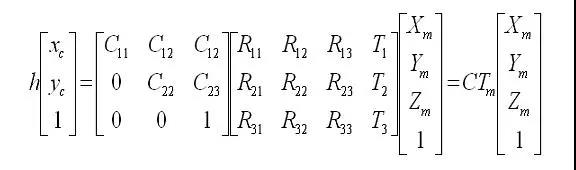
矩阵C的学名叫摄像机内参矩阵,矩阵Tm叫摄像机外参矩阵,其中内参矩阵是需要事先进行摄像机标定得到的,而外参矩阵是未知的,需要我们根据屏幕坐标(xc ,yc)和事先定义好的Marker 坐标系以及内参矩阵来估计Tm,然后绘制图形的时候根据Tm来绘制(初始估计的Tm不够精确,还需要使用非线性最小二乘进行迭代寻优),比如使用OpenGL绘制的时候就要在GL_MODELVIEW的模式下加载Tm矩阵来进行图形显示。
2、 Marker-Less AR
基本原理与Marker based AR相同,不过它可以用任何具有足够特征点的物体(例如:书的封面)作为平面基准,而不需要事先制作特殊的模板,摆脱了模板对AR应用的束缚。它的原理是通过一系列算法(如:SURF,ORB,FERN等)对模板物体提取特征点,并记录或者学习这些特征点。当摄像头扫描周围场景,会提取周围场景的特征点并与记录的模板物体的特征点进行比对,如果扫描到的特征点和模板特征点匹配数量超过阈值,则认为扫描到该模板,然后根据对应的特征点坐标估计Tm矩阵,之后再根据Tm进行图形绘制(方法与Marker-Based AR类似)。
LBS-Based AR
其基本原理是通过GPS获取用户的地理位置,然后从某些数据源(比如wiki,google)等处获取该位置附近物体(如周围的餐馆,银行,学校等)的POI信息,再通过移动设备的电子指南针和加速度传感器获取用户手持设备的方向和倾斜角度,通过这些信息建立目标物体在现实场景中的平面基准(相当于marker),之后坐标变换显示等的原理与Marker-Based AR类似。
这种AR技术利用设备的GPS功能及传感器来实现,摆脱了应用对Marker的依赖,用户体验方面要比Marker-Based AR更好,而且由于不用实时识别Marker姿态和计算特征点,性能方面也好于Marker-Based AR和Marker-Less AR,因此对比Marker-Based AR和Marker-Less AR,LBS-Based AR可以更好的应用到移动设备上。

应用数据科学研究法
机器学习和深度学习算法的优化计算能力:
AR增强现实的技术支撑
识别与跟踪技术
在实现增强现实的过程中,需要对真实的场景和信息进行分析,生成虚拟事物信息。这两步看似简单,其实在实际进行过程中,需要将摄像机获得的真实场景的视频流,转化成数字图像,然后通过图像处理技术,辨识出预先设置的标志物。

识别出标志物之后,一标志物作为参考,结合定位技术,由增强现实程序确定需要添加的三维虚拟物体在增强现实环境中的位置和方向,并确定数字模板的方向。将标志物中的标识符号与预先设定的数字模板镜像匹配,确定需要添加的三维虚拟物体的基本信息。生成虚拟物体,并用程序根据标识物体位置,将虚拟物体放置在正确的位置上。这其中涉及到的识别跟踪和定位问题,是增强现实的最大的难题之一。
要实现虚拟和现实事物的完美结合,必须确定虚拟物体在现实环境中准确的位置,准确的方向,否则增强现实的效果就会大打折扣。而在现实环境中,由于现实环境的不完美性,或者称为复杂性,增强现实系统在这种环境下的效果远不如在实验室的理想环境中。由于现实环境中的遮挡,未聚焦,光照不均匀,物体运动速度过快等问题,对增强现实的跟踪定位系统提出了挑战。
如果不考虑与增强现实进行交互的设备,其主要实现跟踪定位的方法有如下两种:
图像检测法
使用模式识别技术(包括模板匹配,边缘检测等方法),识别获得的数字图像中预先设置的标志物,或是基准点,轮廓,然后根据其偏移距离和偏转角度计算转化矩阵确定虚拟物体的位置和方向。

这种方法进行跟踪定位不需要其他的设备,而且精确度较高,因此是增强现实技术中最常见的定位方法。在模板匹配时,系统会预先存储好多种模板,来和图像中检测到的标志物匹配来计算定位。简单的模板匹配可以提高图像检测的效率,因也为增强现实的实时性提供了保障。通过计算图像中标志物的偏移和偏转,也能够做到三维虚拟物体的全方位观察。模板匹配一般用于对应特定图片三维成像,设备通过扫描特定的图片,将这些图片中的特殊标志位与预先存储的模板匹配,即可呈现三维虚拟模型。比如汽车店的车模卡片,玩具公司的人物卡片,都可以用模板匹配来进行增强现实。边缘检测可以检测出人体的一些部位,同时也可以跟踪这些部位的运动,将其与虚拟物体物体无缝融合。比如,真实的手提起虚拟的物体,摄像机可以通过跟踪用户手的轮廓,运动方式来调整虚拟物体的方位。因此,许多商场的虚拟商品实用,多会使用边缘检测。
虽然图形检测法简单高效,但也有其不足的地方。图像检测多用于相对理想的环境以及近距离的环境,这样获得的视频流和图像信息会清晰,易于进行定位计算。而如果在室外环境中,光线的明暗,物体的遮挡,以及聚焦问题,使得增强现实系统不能很好的识别出图像中的标志物,或是出现和标志物相似的图像,这样都会影响增强现实的效果。而此时,就需要其他跟踪定位方法的辅助。
全球卫星定位系统法
这种方法是基于详细的GPS信息进行跟踪和确定用户的地理位置信息。当用户在真实环境中行走时,可以利用这些定位信息和用户摄像机的方向失误,增强现实系统能将虚拟信息和虚拟物体精确的环境景物以及周围的人物之上。目前由于智能设备的普及,智能手机的广泛应用,而又由于智能手机具有支持基于GPS定位法的增强现实系统的基本组件:摄像机,显示屏,GPS功能,信息处理器,数字罗盘等,并把它们集成为一体,因此这种跟踪定位法多用于这种智能移动设备上。一种称为增强现实浏览器的应用程序,主要就是应用这种方法。增强现实浏览器能够在智能手机上运行,它可以连接互联网,搜索相关的信息,然后让用户在真实的环境看到相关的信息。增强现实浏览器能够可以让用户了解到摄像机方向的几乎所有事物的信息,比如找到一家距离很近但是被遮挡住的餐厅,或是获取用户对一家咖啡馆的评价。

这种定位方式适合于室外的跟踪定位,可以克服在室外环境中,光照,聚焦等不确定因素对图像检测法造成的影响。
其实在增强现实系统实际运用的环境中,往往不会用单一的定位方法来定向定位。比如增强现实浏览器也会运用图像检测法来检测一些特定的符号,例如QR码。识别出QR码在进行模板匹配,即可为用户提供信息。
