本文来自微信公众号“学术头条”,作者:王跃然。
光子计算因速度快、能效高,被视为人工智能(AI)算力破局的关键,但其训练过程长期依赖传统数字计算机,难以应对芯片制造带来的个体差异。
近日,来自贝尔实验室(Nokia Bell Labs)的研究团队在权威学术期刊Nature上介绍了一种集成光子深度神经网络,首次实现了无需数字计算机参与的片上反向传播训练。

论文链接:https://www.nature.com/articles/s41586-026-10262-8
这一突破不仅让光子芯片拥有了端到端的自主学习能力,更在复杂的非线性分类任务中达到了与数字模型相当的90%以上的准确率,彻底解决了长期以来困扰光子AI的鲁棒性与可扩展性难题。
研究方法
光子神经网络(PNN)在训练过程受限于两个主要因素:
其一,多数PNN依赖数字计算机进行离线反向传播训练,但数字模型难以精确包含真实光子器件的物理行为,也无法预测制造过程产生的器件间变异,导致训练效果与实际运行存在偏差。
其二,部分研究采用无梯度算法在芯片上进行参数优化,这类方法随网络规模扩大计算成本线性上升,难以发挥反向传播算法的通用性和扩展性优势。
问题的核心在于,反向传播(BP)算法所需的光子域非线性激活函数及其梯度一直缺乏有效的片上实现方案。
针对以上难题,研究团队将训练所需的所有计算模块集成于同一芯片。芯片同时包含前向推理路径和后向误差计算路径:前向推理结果直接输入后向路径,后者完成代价函数计算并更新前向路径权重,整个过程无需数字计算机介入。
为了在硬件上实现复杂的数学运算,研究团队开发了几种基于标准硅光器件的解决方案。他们采用了PIN强度调制器近似实现ReLU激活函数及其梯度,同一调制器在低增益模式实现前向激活,高增益模式实现梯度函数,用于后向误差传播。此外,他们在芯片中采用了每神经元独立供光设计,各非线性模块均有独立的供应光输入,避免了多层网络中光信号损耗的逐层累积,为网络规模扩展提供了基础。
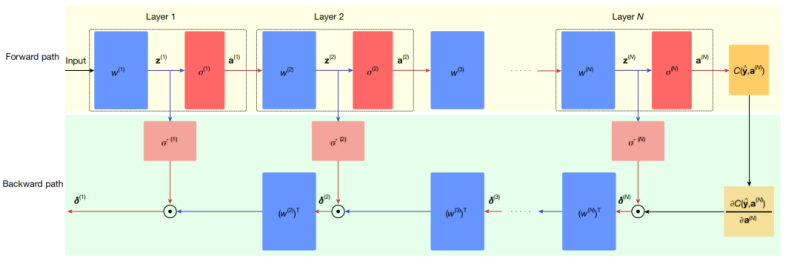
图|神经网络的BP训练过程。该神经网络包含N个层,其中w(l)、z(l)和σ(l)分别表示第l层的权重矩阵、加权求和输出和非线性激活函数。前向传播路径通过将输入信号依次传递至各神经层来生成输出a(N),并利用代价函数C计算输出误差。反向传播路径从输出层开始,通过误差向量δ(l)逐层反向传播误差信息至输入层。
实验验证
为验证片上反向传播训练的实际效果,研究团队设计了两项非线性数据分类实验。
实验首先从经典的XOR非线性分类任务开始。芯片权重随机初始化后,进行片上反向传播训练。训练完成后,芯片成功将两类输出分离。整个过程重复五次,输出结果稳定,类间分离清晰,验证了训练的可重复性。
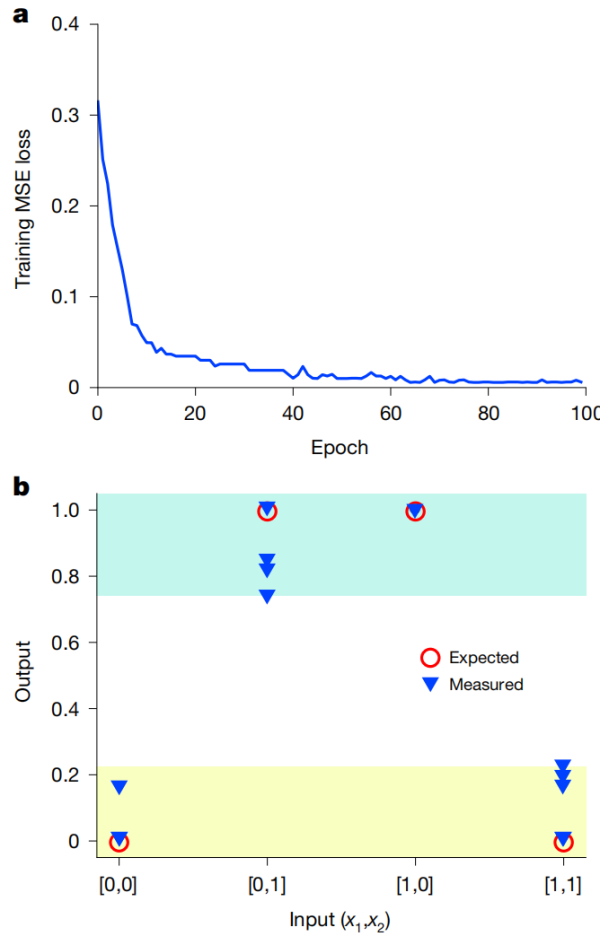
图|非线性数据分类演示。a)XOR训练过程中的MSE损失。b)芯片上BP训练后实测(蓝色三角形)与预期(红色圆圈)XOR运算结果。该过程重复五次。青色与黄色阴影区域显示输出电平的变化情况。
为进一步验证芯片处理更复杂分类任务的能力,团队设计了一个二维点分离问题。数据集包含200个随机生成的点,任务目标是将点划分到蓝色和红色两个区域。从200个点中随机选取50个作为训练集,在芯片上训练40个周期后,全部200个点的推理准确率达到92.5%。作为参照,相同网络架构的数字模型在同样任务上表现相当。
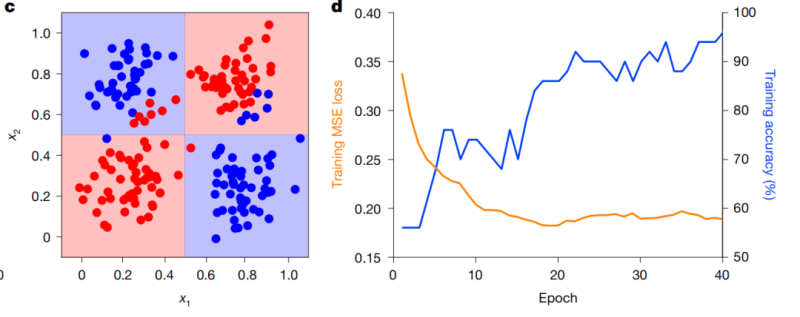
图|c,二维点分离数据集。蓝色阴影区域(0<x1<0.5,0.5<x2<1;0.5<x1<1,0<x2<0.5)和红色阴影区域(0<x1,x2<0.5;0.5<x1,x2<1)分别表示真实(预期)类别,点状数据表示测量结果。d,芯片上BP网络训练MSE损失(橙色曲线)与准确率(蓝色曲线)。
研究团队设计了一项对比实验,以验证片上训练在面对器件制造变异时的鲁棒性。实验比较了三种不同训练-推理组合方式:
- 数字训练与数字推理(红色曲线):作为参考基准,完全在数字域完成。
- 数字训练与片上推理(灰色曲线):代表传统PNN的使用方式。在数字模型中训练后,将权重加载到光子芯片进行推理。
- 片上训练与片上推理(蓝色曲线):本研究提出的端到端片上训练方式。
实验重复五次,每次使用不同权重初始化。结果显示,数字训练接片上推理的方式准确率波动显著,部分试验接近随机水平(50%)。原因在于数字模型无法精确包含器件制造变异。相比之下,片上训练接片上推理的方式五次试验准确率均稳定在较高水平,无需任何器件表征,表明芯片在训练过程中自动适应了自身器件特性。
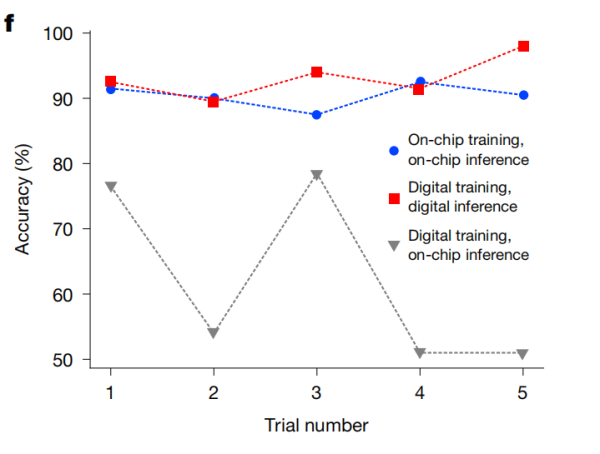
图|展示了五次不同权重初始化试验的推理鲁棒性。该图表对比了端到端片上训练与推理(蓝色)、数字训练与推理作为参考案例(红色)以及数字训练后接片上推理(灰色)三种方案。
意义与展望
这项研究证明了光子神经网络可以像数字网络一样,实现端到端的反向传播训练,填补了该领域的技术空白。
更重要的是,片上训练天然解决了数字训练模型不准的根本痛点。传统PNN依赖数字模型训练,但模型无法精确包含器件制造变异。研究显示,芯片在训练过程中自动适应自身物理特性,将变异影响内化到权重调整中,无需器件表征即可获得鲁棒且可重复的性能。
在可扩展性方面,当前版本采用2输入、8隐藏神经元架构。通过每神经元独立供光设计,层间损耗不会累积,为规模扩展奠定了基础。
同时,研究也指出了当前面临的挑战与未来的改进方向。
当前芯片在面积和功耗方面仍有优化空间。独立的前后向路径增加了光学输入和芯片面积;PIN衰减器功耗较高,导致总功耗约3.7-4.3W。
为此,研究团队提出了一种硬件复用架构,让同一套光子电路在推理模式和训练模式之间切换,这可以将所需的光学输入和非线性模块数量减少一半,显著降低芯片面积和功耗。未来,他们还计划采用电吸收调制器(EAM)替代PIN衰减器,大幅提升训练和推理的速度。通过将电子控制电路与光子芯片进行单片集成或先进封装,可以减少寄生参数,进一步提升系统的集成度和能效。
