本文来自微信公众号“电子发烧友网”,【作者】李弯弯。
电子发烧友网报道(文/李弯弯)全球算力基建叙事生变,正从GPU时代迈向连接为王的通信时代。算力Scaling-law边际效益放缓,芯片间连接通信成系统算力释放的核心瓶颈,光互联逐渐替代铜连接,成为构建高性能AI网络的关键。
近期阿里、腾讯均推出NPO(近封装光学)重大成果,其中阿里云全光Scale-up网络架构UPN512通过光互连直接连接xPU与交换机,采用单层CLOS拓扑实现512颗xPU的全互联,该方案彻底消除机柜内高速铜缆,显著降低布线复杂度、散热负担、供电需求及运维成本,功耗降低50%,成本下降30%。
近封装光学NPO技术优势
首先我们来看看什么是NPO及其优势。中国移动云能力中心此前发布过一份《云智算光互连发展报告》,该报告介绍,NPO的核心思想是,将光引擎非常靠近电芯片放置,但并不像CPO那样与电芯片共封装在同一基板或中介层上。它通常将光引擎安装在同一基板上,通过极短的高性能电气链路与电芯片相连,形成一个高度集成的系统,如下图所示。
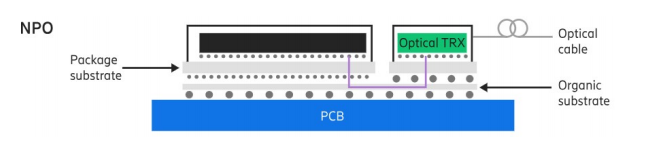
NPO将光引擎与电芯片物理分离,避免了电芯片的高温热量直接冲击光器件,散热设计更简单、高效。由于电芯片本身是巨大的热源,工作时温度很高,而激光器等光器件对温度极其敏感,所以,光引擎与电芯片共封装会导致波长漂移和性能下降。同时,由于光引擎未与电芯片共封装,NPO在可维护性层面具有优势,如果光引擎失效,只需更换光引擎子模块即可,避免了大量的维护成本。
相比激进的CPO技术,NPO技术是一种更务实、风险更低的路径。并且,NPO与传统光模块相比,其性能远超传统光模块,其主要优势包括以下几点:
- NPO的光引擎拥有更大的可布置面积和更灵活的走线方案,可以方便地使用LGA封装,且有利于光引擎散热;
- NPO不影响电芯片原有设计,只对PCB或基板做差异设计即可满足不同需求;
- NPO与电芯片解耦,能够避免形成电芯片垄断问题;
- NPO可单独测试TP1的电信号质量,可归一化设备的驱动与固件,可测试性更好。
产业界正在形成共识,未来光互联由Scale-up、Scale-out、Scale-across等多元网络连接场景共同驱动,各技术路线长期共存、并行发展。
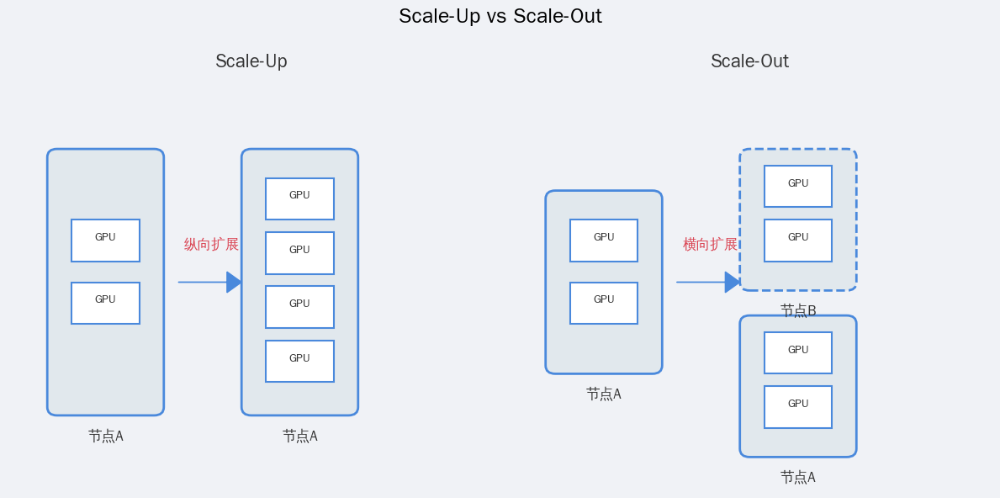
Scale-Up即垂直扩展,通过向单个节点添加更多硬件提升处理能力。在AI大模型训练里,它借助高速互联技术将单个节点多块GPU紧密相连,形成有超大共享显存池的“超级节点”,让单个模型能在统一显存空间高效训练,无需跨节点通信,是解决“内存墙”瓶颈的关键。
Scale-Out是水平扩展,通过增加节点组成集群提升整体处理能力。当单个“超级节点”算力不够时,将成百上千个节点用高速网络连接成庞大计算集群,让模型训练任务可并行分布在众多GPU上。
Scale-Across(跨区域扩展)是应对超大规模AI计算需求提出的“第三大支柱”范式。随着AI模型对算力需求爆炸式增长,单个数据中心在电力、散热、空间上接近极限,Scale-Across便是将不同城市、国家甚至大洲的多个数据中心用高速网络连接,形成协同工作的“超级巨型工厂”。
随着AI大模型向千亿、万亿参数规模突破,训练与推理场景的高并发数据传输需求呈指数级增长,Scale up网络作为支撑算力高效释放的核心基础设施,规模也在迅速扩大。目前,Scale out层面可插拔光模块仍是首选,Scale up层面作为新兴光模块市场,技术高速迭代,NPO、CPO等方案同步演进。
全球首款3.2T NPO模块成功点亮
2025年10月,阿里云正式发布UPN512全光Scale-up架构白皮书,提出基于单层以太网光互连的全新设计,旨在打造“大规模、高性能、高可靠、低成本、易扩展”的xPU互联系统。
UPN512通过光互连直接连接xPU与交换机,采用单层CLOS拓扑实现512颗xPU全互联,还为扩展至1K+节点预留架构空间。此方案消除机柜内高速铜缆,大幅降低布线复杂度、散热负担、供电需求及运维成本。
NPO是UPN512架构的核心使能技术。它将光电引擎靠近主芯片部署,采用线性直驱技术,省去传统DSP芯片,实现功耗降低50%以上、成本下降30%、端到端时延与铜互连相当,且供应链更安全可控。与LPO相比,NPO带宽密度更高,对主芯片SerDes性能要求更低;和CPO相比,NPO采用标准LGA连接器,保持光模块开放解耦特性,更易被用户采纳。
阿里云从3.2T NPO切入研发,基于OIF标准封装,在22.5mm×35.1mm尺寸内实现3.2Tb/s传输带宽。通过标准LGA连接器,光引擎与主芯片物理和电气解耦,延续开放生态。该模块支持硅光与VCSEL两种技术路线,适配不同场景。
近日,阿里云宣布全球首款基于OIF标准封装的3.2T NPO模块成功点亮,标志着全光Scale-up进入工程落地新阶段。该模块基于两颗16通道收发一体硅光芯片,搭配线性直驱Driver/TIA芯片,采用2D封装工艺,具备快速量产潜力。其关键性能指标优异:发送端光眼图性能好,符合IEEE 802.3bs DR4标准,可与传统带DSP的DR4光模块无缝互通;接收端在1E-6误码率下,所有通道灵敏度优于-5dBm;典型功耗约20W,低于同带宽DSP方案。
阿里云将3.2T NPO技术率先应用于新一代国产四芯片交换机。该设备单机集成4颗25.6T国产交换芯片,总交换容量达102.4T,可平滑演进至409.6T平台。目前,该交换机已完成整机上电与核心功能验证,进入长期可靠性测试阶段。
写在最后
在算力需求持续增长的当下,全球算力基建正经历深刻变革。算力中心多元网络连接场景驱动光互连技术发展。从目前的情况来看,可插拔光模块在未来几年仍是需求主力;NPO/CPO在柜内全光连接领域加速渗透,CPO进展超预期。此前市场对NPO较少关注,随着近期阿里云、腾讯在NPO方面的动作和进展,其技术优势想必会更多的被业界关注。整体来看,光互连行业市场空间将持续扩大。
