本文来自微信公众号“中国电子报”。
2023年,生成式人工智能在全球范围内掀起热潮,大模型的竞争越发激烈。在2024年,人工智能将进一步带动芯片算力、存力(存储性能)和能效的提升,推动半导体在架构和先进封装等环节的创新,并带来新的市场增量。
芯片架构迈向多元化
ChatGPT的出现拓宽了AI芯片的市场空间,AI大模型训练需求激增,因此高算力芯片成为半导体产业链本轮复苏的主要驱动力。在AI浪潮中,英伟达2023年的数据中心业务凭借着A100、H100等GPU(图形处理器)产品实现了217%的同比增长,截止2024年3月6日,其市值突破2.1亿美元。
作为当前进行AI运算的主流处理器,GPU自身具备强大的并行计算能力,但在近几年的市场验证中,也暴露出成本较高、交付周期较长以及功耗偏高等问题。一方面,英伟达正在努力缩短交付周期;另一方面,各类企业正在创新芯片架构,以期对AI处理器的功耗和成本进行优化。
因此,ASIC这类适用于特定场景的芯片开始被谷歌、微软等云服务厂商关注。
谷歌自2016年开始研发专用于机器学习的TPU(张量处理器),并将其作为AlphaGo的算力底座。TPU采用低精度计算,在保证深度学习效果的同时降低功耗,并提升运算效率。谷歌于今年1月发布的TPU v5p版本在大模型训练中的效率相较于v4提升了2.8倍。据悉,该系列芯片也将应用于谷歌Gemini AI大模型的训练。
2月19日,由前谷歌TPU核心研发团队的工程师组建的初创公司Groq也开放了自家产品LPU(语言处理器)的体验入口。在架构方面,Groq的LPU使用了TSP(张量流处理器)来加速人工智能、机器学习和高性能计算中的复杂工作负载。Groq相关发言人称,该处理器的推理能力是英伟达H100的10倍。
此外,在AI从云端向终端渗透的过程中,诸多厂商认为NPU(神经网络处理单元)是更加适合AI运算的技术路线。高通的AI PC芯片X Elite和英特尔酷睿Ultra处理器中均集成了NPU以提升电脑端的AI性能。

高通AI引擎集成了CPU、GPU、NPU等多种处理器(图片来源:高通)
架构的多点开花既体现出各大企业对于通用芯片和专用芯片的取舍,也意味着更多芯片品类的供应商及其上下游企业有机会分享AI时代的红利。
“在过去几年,GPU由于其完善的开发生态仍然是AI计算的主要选择。然而,随着模型参数不断增大,芯片对于计算能效的要求相应提升,专用处理器在某些特定AI应用场景中的优势将会十分明显。综合考虑应用场景、成本等多方面因素,未来AI计算的硬件芯片选择将是多技术路线并存的。”北京大学集成电路学院研究员贾天宇告诉《中国电子报》记者。
AI性能带动先进封装
在上游芯片设计企业迎来AI带来“泼天的富贵”的同时,下游的封装技术也获得了增量空间。
“生成式AI模型需要数百万或数亿级别参数才能进行推理,对芯片的处理速度、容量、带宽都提出了更高的要求,这将推动以Chiplet(芯粒)为代表的先进封装技术进一步发展,带来封装行业的生态变化。”中电科电子装备集团有限公司董事长景璀告诉《中国电子报》记者。
芯片的算力与晶体管数量呈正相关。由于摩尔定律的放缓,芯片的面积已经缩小到接近物理极限,即便台积电、英特尔IFS、三星电子等制造厂商纷纷公布3nm及更先进制程,也面临着提升成品良率的挑战。因此,先进封装技术以及SIP(系统级封装)等新的封装方式将会是延续摩尔定律的有效途径。
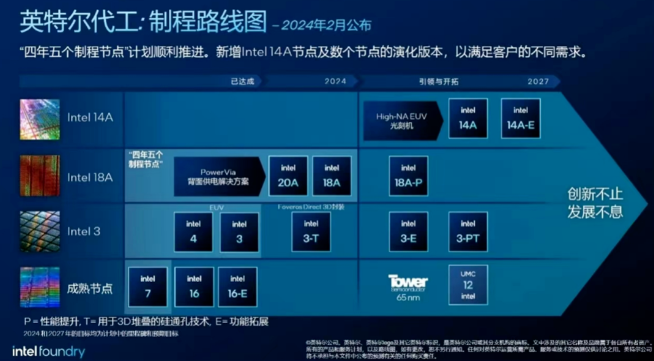
英特尔IFS“四年五个制程节点”路线图(图片来源:英特尔)
其中,Chiplet技术可谓“掌上明珠”。
一方面,Chiplet颇受芯片设计企业青睐。凭借高灵活性,Chiplet既实现了对不同架构、不同工艺材料的堆叠,也省去了前道的复杂制造工艺,对设计企业而言更具性价比。有机构统计,有将近30%的高性能CPU和GPU采用了Chiplet设计,包括英伟达、AMD等算力芯片供应商。
另一方面,Chiplet的火热也推动了制造和封测企业在技术上的不断创新。英特尔联合多个公司确立了UCIe(通用芯粒互连通道)标准,用于芯片内部的计算区块通信,并推出EMIB和Foveros等封装技术,以便将芯粒无缝集成至封装中。
台积电此前与赛灵思合作开发CoWoS封装技术。基于Chiplet,CoWoS通过互联硅中介层互联实现多芯片封装、高密度互连并降低功耗。随着GPU站上AI风口,台积电CoWoS产能也迅速告急。在台积电1月18日举办的财报会议上,总裁魏哲家表示AI芯片对先进封装的需求十分强劲,目前产能仍无法应对客户强劲需求,供不应求的状况可能延续到2025年。
存储原厂比拼产能与封装技术
算力是训练大模型的重要支撑,而存储性能则与大模型的推理效率紧密相关。在大模型云集、AI应用逐渐落地的背景下,推理能力被越来越多的芯片和云服务厂商强调。因此,在GPU产品中会配置多块HBM(高带宽存储)以削弱芯片在AI计算中的内存墙效应,进一步降低延迟。
HBM在2024年的竞争将会更加激烈。
美光CEO Sanjay Mehrotra在2023年年底的财报会议上透露,AI芯片对HBM的需求旺盛,美光2024年的HBM产能预计已全部售罄——于2024年年初量产的HBM3E有望为美光创造数亿美元的营收。
无独有偶,2月,SK海力士副总裁金基泰发文表示,虽然2024年才刚开始,但今年SK海力士旗下的HBM已经全部售罄。同时,公司为了保持HBM的市场领先地位,已开始为2025年做准备。三星电子紧随其后,在2月27日正式推出12层堆叠HBM3E,比前代产品的带宽提升50%,预计将于下半年投入量产。

三星电子的HBM3E 12H(图片来源:三星电子)
普遍来讲,存储芯片的堆叠层数越高,其性能越强,但发热和良率等问题也越明显。因此,与算力芯片类似,先进封装及其相关技术也成为了存储芯片提升性能的重要手段。
除了HBM中常见的封装技术TSV(硅通孔)之外,三星电子努力消除堆叠层之间NCF(非导电薄膜)材料的厚度。据悉,三星电子12层堆叠的HBM3E采用了热压非导电薄膜技术,将芯片间隙压缩至最小7微米,使得12层与此前8层堆叠产品的高度保持一致。
SK海力士自研了MR-MUF(批量回流模制底部填充)技术,区别于在每层芯片上铺薄膜材料,该技术通过在堆叠的芯片之间注入保护材料,以提升工艺效率和散热性。SK海力士副社长孙皓荣表示:“为了实现不同的人工智能应用,人工智能存储器的特性也应该多元化。我们的目标是以各种先进封装技术来应对这些变化。”
材料和架构创新助力低功耗
AI芯片除了通过调整架构和先进封装技术提升算力和存力,还需考虑功耗因素。
一方面,在数据中心里,AI服务器的功耗逐渐增加将催生新的解决方案。据了解,英伟达H100的功耗达到了700W,而之后将推出的B100功耗还会再增加40%,这就驱使现有的制冷技术进一步优化。英伟达CEO黄仁勋此前透露公司的下一代产品将会采用液冷方案,戴尔公司首席运营官JeffClarke也表示“工程团队为(英伟达)这款新产品做好了准备,为GPU带来高功耗所需的散热解决方案”。
由于发展AI需要大量算力支撑,这也使得对电力的需求飙升,此时宽禁带半导体和储能也将发挥作用。“大型计算基础设施的运行需要更高功率、更高能效的电力电子设备去支撑,这对碳化硅、氮化镓等宽禁带半导体市场将是一个新的增长点。”深圳基本半导体有限公司总经理和巍巍告诉《中国电子报》记者,“另外,未来AI技术的发展将高度依赖于能源,特别是光伏和储能技术的进步,这也与半导体行业息息相关。”
另一方面,AI正在经历从云到端的渗透,端侧更加重视低功耗的需求。存内计算将有可能成为在边缘侧进行AI计算的全新范式。
“相较于云端的大算力GPU,终端智能计算芯片在保障性能的同时更追求低功耗、低成本。存算一体类的新技术具有低功耗的优势,未来有望在广泛的边缘智能计算中发挥作用。”贾天宇表示。
当前存内计算已经应用于视觉、健康等智能终端设备中,未来也有望在边缘侧、自动驾驶乃至数据中心得到应用。有机构报告显示,2023年存内计算的市场规模有近177亿美元,2030年将达到526亿美元,年复合增长率16.8%。
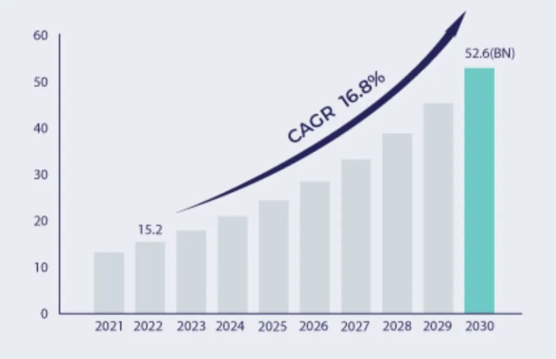
存内计算市场规模预测(图片来源:SNS Insider)
对于存内计算而言,市场前景与技术挑战并存。知存科技创始人兼CEO王绍迪向《中国电子报》记者表示:“以手机端跑AI大模型为例,现在手机中16GB的LPDDR5已经超过70美金,70GB/s的带宽(对比云端服务器带宽近1TB/s)在短时间内也不易提升,同时带宽的扩大必然会引发功耗升高。存内计算相比传统架构AI芯片在成本、容量、带宽和功耗各项能效上都具有很大优势,虽然短时间内满足边缘侧的模型算力需求并且达到很好的应用效果仍有很大挑战,但这是一件非常值得去做的事。”
