本文来自微信公众号“半导体行业观察”。
在这篇文章中,全球战略咨询公司Altman Solon探讨了生成式人工智能如何影响网络基础设施。并探讨了新兴企业生成式人工智能解决方案对计算、存储和网络基础设施的影响。
生成式人工智能的最佳代言人可能是ChatGPT。这款由OpenAI开发的聊天、引人入胜的应用程序以栩栩如生的方式解答各种问题,令全球数百万人眼花缭乱。在幕后,OpenAI令人印象深刻的大型语言模型(LLM)运行在庞大的超级计算基础设施上。就ChatGPT而言,OpenAI依靠其合作伙伴Microsoft Azure的云计算平台来训练该模型。微软花费数年时间将数千个Nvidia图形处理单元(GPU)连接在一起,同时管理冷却和功率限制。
Altman Solon认为,企业级生成式人工智能工具的增长将导致对计算资源的需求增加,从而对进行训练的核心集中式数据中心和进行推理的本地数据中心产生积极的影响。网络提供商应该会看到对数据传输网络的需求适度增长以及对专用网络解决方案的推动。
我们使用四步方法来了解基础设施的影响,考虑每个生成式AI任务的平均计算时间要求、总体生成式AI任务的数量、所需的增量计算要求以及对基础设施价值链的可量化影响。为了满足这一需求,服务提供商需要开始规划足够的计算资源和网络容量。
量化企业生成式人工智能用例
Altman Solon利用我们对292名高级商业领袖的调查数据,计算了四个业务职能部门(软件开发、营销、客户服务和产品开发/设计)每小时的生成式AI任务量。考虑到每个用例的潜在采用率、每个用例的平均用户数以及每个用户每小时的平均生成式AI任务,我们估计明年仅在美国这些关键企业职能部门每小时就会执行80-1.3亿生成式AI任务。
跨企业职能部门每小时生成的AI任务
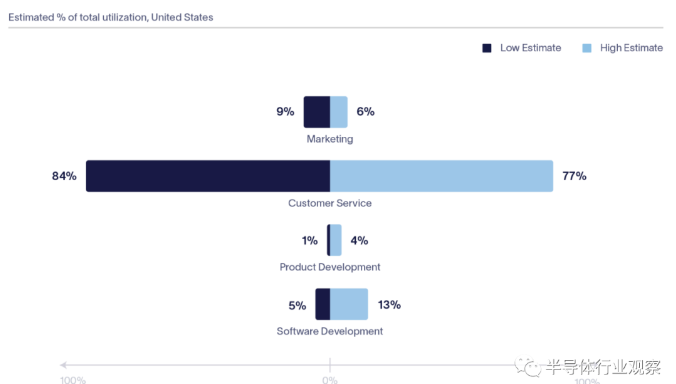
尽管我们的研究表明,客户服务采用生成式人工智能解决方案的速度慢于软件开发和营销,但客户服务任务将负责企业生成式人工智能的大部分使用。这主要是由于用户与生成式人工智能聊天机器人的交互量巨大。当然,计算不仅仅发生在LLM被查询时。构建和使用生成式人工智能需要大量的基础设施。
开发和使用生成式人工智能解决方案:训练和推理对基础设施的影响
构建和使用生成式人工智能工具时,在两个不同的阶段需要计算资源:训练模型,然后使用模型响应查询(也称为“推理”)。训练LL,需要向神经网络提供大量收集到的数据。就ChatGPT而言,大量文本数据被输入到法学硕士以识别单词和语言之间的模式和关系。随着模型处理新的文本数据,其性能得到改善,分配给神经连接的参数或值也发生了变化。GPT-3模型包含超过1750亿个参数;据推测GPT-4有1万亿个参数。
训练大型语言模型:从研究到人类反馈
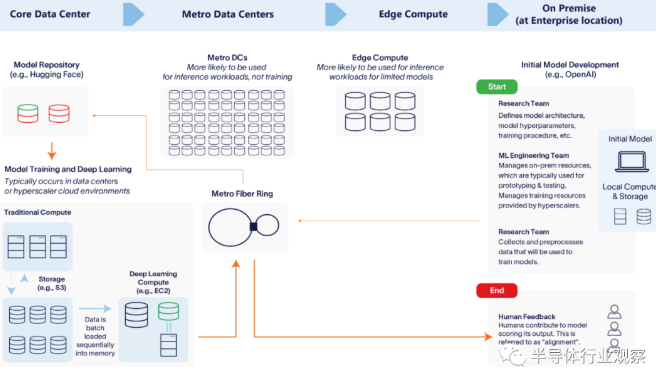
尽管迭代大量数据来训练模型需要大量计算,但训练仅在模型开发期间进行,并在模型最终确定后停止。在LLM的生命周期中,训练将占用10-20%的基础设施资源。相比之下,推理是大多数工作负载发生的地方。当用户输入查询时,信息将通过生成人工智能应用程序的云环境提供。80-90%的计算工作负载发生在推理期间,并且只会随着使用而增加。以ChatGPT为例,训练该模型据称需要花费数千万美元,但据报道运行该模型每周都会超过训练成本。
培训生成式人工智能解决方案:公共云和核心集中式数据中心感受到的最大计算影响
生成式人工智能模型往往在集中式核心数据中心进行训练和存储,因为它们拥有处理在LLM中循环的大量数据所需的GPU。模型也存放在公共云中并进行训练,以消除入口和出口成本,因为训练数据已经驻留在公共云中。随着采用率的增长,我们预计推理将更多地在本地进行,以缓解训练模型的核心集中式数据中心的拥堵。然而,这也有一些限制:生成模型太大,无法容纳在传统的边缘位置,而传统的边缘位置往往具有更高的空间和电力成本,并且无法轻松扩展以适应资源匮乏的人工智能工作负载。
“我们[为超级计算机]构建了一个可以大规模运行且可靠的系统架构。这就是ChatGPT成为可能的原因。这就是其中的一个模型。还会有很多很多其他的,”微软Azure AI基础设施总经理Nidhi Chappell说道。
Altman Solon认为,生成式人工智能工具的增长将对公共云产生最重大的影响。公共云提供商应重点关注区域和弹性容量规划以支持需求。在不久的将来,随着模型的成熟和关键计算资源变得更便宜,私有云环境可能会开始容纳和培训法学硕士。这对于制药、金融服务和医疗保健等受监管领域的行业特别有用,这些行业往往更喜欢在私人基础设施上开发和部署人工智能工具。
查询生成式人工智能工具:主干光纤和城域边缘网络感受到的网络影响最大
生成式人工智能工具的网络使用受查询量和复杂性的影响最大。例如,要求ChatGPT回答一个基本问题与要求其起草一篇900字的文章对网络使用的影响不同,就像要求Dall-E上的单个图像与一系列高清照片或视频一样。更长、更复杂的输出需要更多的数据,影响对骨干网和城域边缘网络日益增长的需求。对于连接到主要云平台或云环境之间的光纤尤其如此。我们预测,随着生成式人工智能的成熟并成为消费者和企业的主流,城域边缘网络的使用量将会增加。查询的数量可能会在特定的云阻塞点产生流量和计算或存储饱和,
对整个基础设施价值链的影响
尽管我们仍处于生成式人工智能采用的早期阶段,但我们相信,为了满足不断增长的计算、网络和存储需求,基础设施提供商应通过以下方式进行调整:
核心、集中式数据中心:模型开发人员依赖云提供商来满足训练的计算需求。在不久的将来,数据中心应重点关注容量规划,以确保为训练和推理工作负载提供足够的计算、电力和冷却资源。从长远来看,如果生成式人工智能模型激增,并且图像和视频生成法学硕士数量增加,那么核心集中式数据中心将面临网络和计算拥塞的真正风险。云提供商可以通过在都市数据中心/区域可用区提供可处理繁重的生成式人工智能工作负载的计算能力来降低这种风险。
此外,生成式人工智能对核心、集中式数据中心和云服务的需求是通过Cohere和OpenAI等模型提供商来满足的。因此,核心集中式数据中心应探索排他性合作伙伴关系,例如Azure和OpenAI之间的合作伙伴关系,以确保锁定。与此同时,为了避免围绕单一提供商进行整合,核心、集中式数据中心还应该寻求开源合作伙伴关系。将LLM技术集成到PaaS和SaaS业务中可能是促进采用和增加收入的明智方法。
主干网和城域光纤:需求的增长主要是由训练数据、推理提示和模型输出驱动的。流量拓扑也发生了变化:模型生成的内容源自核心、集中式数据中心,并且是实时生成的。因此,它不能预先存储在靠近最终用户的位置。主干网和城域光纤提供商应增加网络容量和出口带宽,以满足不断增长的需求。
此外,企业用户还担心数据隐私和驻留,尤其是当该数据用于训练时。这些担忧可能会导致对私有广域网解决方案的需求增加,尤其是包含云连接的广域网。最后,人工智能模型越来越多地托管在不同的云提供商或与其他企业应用程序和工作负载不同的计算环境中。这会导致延迟问题,骨干光纤提供商可以通过互连和对等来解决这一问题,特别是与核心、集中式数据中心和模型提供商。
城域数据中心和边缘计算:虽然我们预计推理将被推送到城域数据中心位置,但我们不期望相同的模型被推送到较小的“边缘”计算位置。目前,将推理工作负载推向边缘并没有太大的价值(或可行性),因为计算延迟仍然远远高于网络延迟,并且在核心、集中式数据中心很难获得生成式人工智能硬件,更不用说在边缘了。然而,在未来,较小的生成式人工智能模型可以针对边缘数据中心中现成的CPU进行优化。与此同时,边缘计算环境还可以针对补充工作负载,例如即时预处理、图像或视频预处理以及模型输出增强。
接入:接入网络的需求增长相对较小,因为早期的生成人工智能流量更类似于接入网络上的搜索流量。随着时间的推移,接入网络上生成式人工智能流量的复杂性和数量将会增加(例如生成视频),但只会适度影响接入带宽需求。
本地:本地硬件不满足生成式人工智能模型的要求,特别是在片上内存方面。虽然模型在可预见的未来不太可能在本地运行,但由于数据隐私问题以及在移动设备上本地运行法学硕士的吸引力,它是一个活跃的研究领域。
使用LL,来自动化基本业务功能不仅会影响员工和管理层。尽管如此,它也会影响生成人工智能本身的构建模块,从核心、集中式数据中心到原始设备制造商、芯片制造商和设计师。虽然未来尚未书写,但基础设施提供商应该考虑如何为需要大量计算、存储和网络资源的技术提供服务。
