本文来自CSDN。
从云而上,以边缘为终。
计算支持的层面上云计算、雾计算、边缘计算等相继而起,从场景层面上,智能家居、工业制造、交通政务、环境勘测等各自芬芳。我们能看到的算力形态已开始百花争艳,而在我们看不到的地方,依然有着旺盛的算力需求。
随着“十四五”计划的不断落地,加快数字化发展,大力发展数字经济,打造具有国际竞争力的数字产业集群,全面实施智能制造行动计划,业已成为我国当前发展的重点之一。而企业想要从中脱颖而出,如何突破算力的迷局,找到更加高效的算力形态,就变得至关重要。据英特尔预测,全球的算力需求预计到2025年将提升1000倍。那么算力需求如此旺盛,哪里才能得到这样的算力呢?算力的形态如此丰富,最终的答案究竟是什么?是CPU?GPU?ASIC?还是FPGA?近年来,我们看到了一个更加可靠的答案,那就是:“我全都要。”
异构计算:不仅仅是多面手
“我全都要”并非一种贪心,而是一种趋势。
数字化建设的根源在数据,也在智能。而各行业日趋复杂的大数据和AI应用环境下,算力需求爆发式增长,这不仅是量在增加,形态也在变化。但是,作为一家企业,算力与架构及系统的绑定关系使得他们不可能频繁更换底层,因此,当算力的供给增长无法跟上算力需求的脚步,多元化算力的概念就被人开始提起。
异构计算是多元算力的典型。跨越标量(CPU)、矢量(GPU)、矩阵(ASIC)、空间(FPGA)的异构计算,如今已经成为企业推动IT基础设施重构的重要力量。其能够将不同架构的运算单元整合到一起进行并行计算,以最适合的专用硬件去做最适合的事如密集计算或外设管理等,从而达到性能和成本的最优化。因此很多企业开始尝试使用异构计算来化解算力瓶颈,挖掘和实现算力增长。
多元算力的应用场景正在变得越发广泛,以快手为例,其在内容生产、内容理解、内容分发、内容消费等过程中都多元算力有着大量需求。尤其是在推荐系统方面,快手采用了计算与存储分离的架构模式,推荐系统中的存储型服务主要是用来存储和实时更新上亿规模的用户画像、数十亿规模的短视频特征、以及千亿规模的排序模型参数。其中参数服务器是一个容量和带宽受限的系统,需要支撑每秒数亿次的KV请求;参数服务器的KV请求也高达每秒数亿次,大规模查表会消耗大量CPU资源,成为其性能的主要瓶颈。
异构计算正是快手与英特尔联手给出的答案,通过将负载卸载到专门优化的芯片上,将有助于消除性能瓶颈,在吞吐量与延时方面实现显著改善。
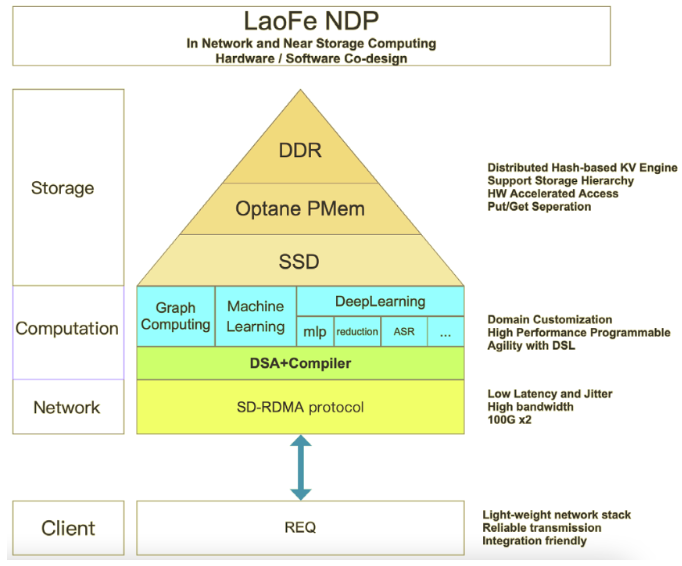
快手LaoFe NDP异构计算架构
快手可提供异构加速选项的LaoFe NDP架构在计算层采用英特尔CPU、FPGA、PMEM等器件,实现了基于LaoFeNDP架构的FPGA based KVS实践落地,进一步提升快手在推荐、搜索、广告、风控等各种场景的应用性能。同时,其通过计算体系结构创新、软硬一体化、领域专用加速器设计,通过网络存、存储、计算三重加速来提供低延迟、高并发、高吞吐、低总体拥有成本(TCO)的基础资源。
三重加速,正是异构计算独有的魅力所在。
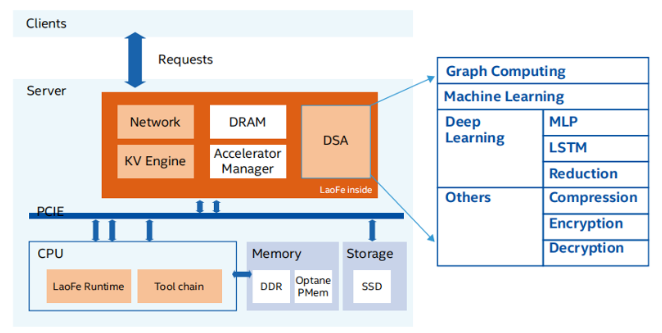
快手LaoFe NDP架构图
网络方面,LaoFe NDP架构将CPU收发网络数据操作,卸载到FPGA上。Client发送的请求包直接发送给FPGA。相比gRPC基于TCP/IP,功能过于复杂,性能和延时方案无法保证。而使用基于FPGA实现了一套SD-RDMA协议,通过应用层添加字段的方式,保证了类似gRPC的可靠性传输,这大大降低了请求时延。
存储方面,LaoFe NDP架构将CPU存储操作也卸载到FPGA上。为了可以最大程度发挥FPGA的能力,快手基于通用KV存储场景定制了一套易于FPGA访问的KV(Key-Value)引擎。同时,其支持SSD/英特尔®傲腾™持久内存/DRAM内存、基于hash的Key-Value存储引擎,能够有效加速存储性能。通过实战检验,使用KV查表的吞吐相比CPU方案提升了足足5倍以上。
计算方面,LaoFe NDP架构通过DSA的方式将计算操作卸载到FPGA上,实现了一个领域专用处理器。领域专用处理器是一类针对特定领域量身定制的处理器。它针对特定领域可编程,同时在特定领域问题处理上能带来显著的性能和效率的提升。再加上英特尔®至强®可扩展处理器、英特尔®FPGA等设备,可以帮助快手将LaoFe NDP架构优势发挥到极致。
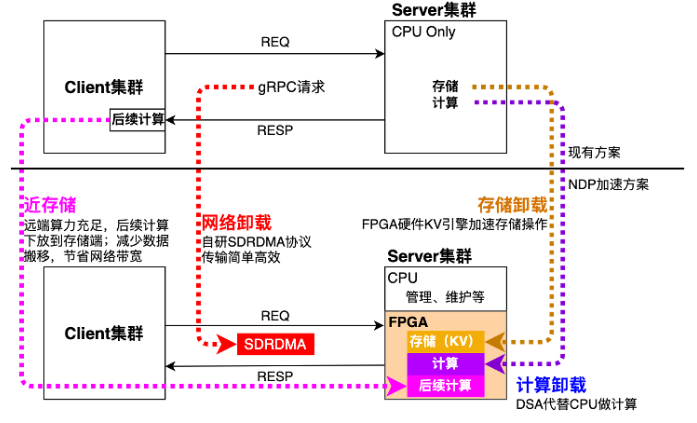
网络、存储、计算加速后示意图
异构计算背后,一场性能的变局
事实上,异构计算并非新的概念,其早在上世纪80年代中期就已经被踢出,当时便被认为有着计算能力强、可扩展性好、资源利用率高等特点。但是,为什么异构计算时至今日,才再次发挥出巨大作用呢?
我们知道技术是发展的,很多在以往无法实现的构思,可能在若干年后发光发热。就比如1956年提出的人工智能技术,在半个世纪后才发展壮大并成为了社会生活必不可缺的一部分。支撑起其变化的一方面是数据处理技术的成熟,另一方面就是算力自身的发展。异构计算也是如此,英特尔在其发展的过程中起到的关键作用。
在快手的LaoFe NDP架构中,英特尔®Stratix®10 FPGA表现十分出众。全新的英特尔Hyperflex™FPGA架构相比前一代时钟频率提高了2倍,功耗降低了70%。此外,更快的时钟频率减小了总线宽度和知识产(IP)的规模,释放了更多分FPGA资源,以添加更强大的功能。同时它采用了超感知设计工具,减少了布线拥塞和设计迭代,提高了设计工作的效率。
一只蝴蝶都可能引发一场风暴,更何况是产品效能的全面提升。当英特尔®Stratix®10 FPGA在LaoFe NDP每个环节中频繁出现,其带来的影响是巨大的。
通过将负载从CPU卸载到FPGA中,并采用Hash表查找优化、随机访存、读写分离等方式,快手将单节点参数服务器的吞吐性能提升了5-6倍,整体请求延时则降低70%-80%,这有助于提升上层应用的实时性,提供更佳的用户交互体验。
由于FPGA based KVS方案能够在单节点服务器中提供远超传统方案的吞吐性能,因此仅需要部署少量的服务器就能够满足特定的性能指标要求(替代比可达1:5),从而降低参数服务器的TCO。
通过使用FPGA来进行查表,能够有效地降CPU由于高频率更新而产生的性能抖动。
总结一下,英特尔®Stratix®10 FPGA为快手LaoFe NDP架构提供了富于弹性的可编程硬件能力,减少延时,实现精确控制,而且其单位算力功耗低、片上内存大,能够适用于延时要求高、批处理(Batch)比较小、并发性和重复性强的应用场景。
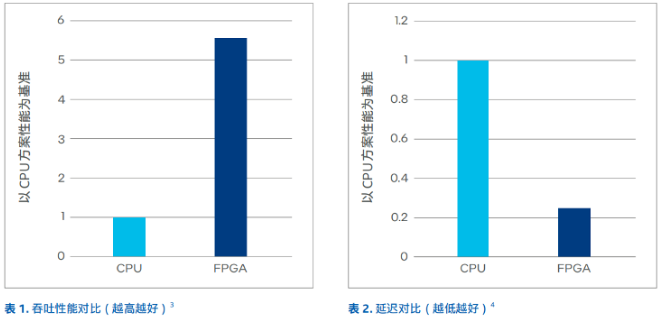
FPGA based KVS方案与传统方案性能对比
英特尔®至强®可扩展处理器针对众多工作负载类型和性能等级而优化的平衡架构,其对于LaoFe NDP非常重要,能够为之提供内置的人工智能加速和高级安全功能,可提供无缝性能基础,帮助从边缘到云加快数据的变革性影响。除此以外它横跨计算、网络、存储的平台创新和硬件增强虚拟化,均支持新型内存创新,促进以经济实惠、灵活、可扩展的方式实现边缘到云的传输,从而一致地提供出色的企业对企业(B2B)和企业对消费者(B2C)体验。同时英特尔硬件增强的安全性有助于抵御恶意攻击,同时保持工作负载的完整性和性能。
英特尔®傲腾™持久内存集高速、高性价比、大容量、持久数据保护和高级加密等优势于一体,在其推出之时便引发了巨大反响。它能够为LaoFe NDP增加全新的内存和存储层级,缩小内存和存储层次架构之间的关键差距,从而实现更智能、更灵活的架构。其能实现每台服务器的内存容量翻倍,且每台虚拟机的成本降低达25%,在进行实时分析和AI工作负载等需要处理大量数据集的服务,性能提升可高达2倍。除此以外它还提供了内存模式(Memory Mode)和应用直接访问模式(App Direct Mode)两种模式。在内存模式下,英特尔®傲腾™持久内存可作为经济高效的DRAM替代品。CPU内存控制器会把持久内存视作易失性的系统内存,表现与DRAM类似,同时CPU内存控制器会将DRAM内存用作持久内存的高速缓存。该模式能够提供更大的内存容量,这对于异构计算的提升效果是巨大的。
软硬并进,异构即兼容
你见,或者不见,算力就在那里。异构计算衍生发展数十年,其就像一座矿山,等待用户的去发掘。宝剑赠英雄,开发者们如何充分挖掘现有异构硬件的性能,获得最优性价比的IT资源才是关键。
“软硬兼施”才能更好的应对异构计算的需求。
在硬件层面,英特尔提出XPU战略,完善在CPU、GPU、ASIC、FPGA领域的产品线。不仅通过性能核心和能效核心战略,使CPU中不同核心负责不同工作负载,实现CPU集群自身的异构,同时通过AMX、SSE、AVX、AVX-512等指令集扩展,大幅度提升CPU的AI运算性能。在全新的第四代英特尔®至强®可扩展处理器中,加入了更多异构加速引擎,比如加速内存拷贝的DSA,加速网络处理的DLB,加速大数据分析的IAA,加速数据加解密、压缩解压缩的QAT,使CPU弹性进一步提升,轻松应对多种工作负载的性能加速需求。
除了CPU,英特尔还提供面向云游戏、视频处理、虚拟桌面和AI推理的Flex系列GPU,面向HPC和AI训练/推理的GPU Ponte Vecchio。而针对特定的AI加速,英特尔还打造了面向AI训练和推理的专用人工智能处理器Habana,丰富ASIC AI芯片的生态系统。
针对数据中心部署和应用中的数据流处理、计算加速和存储加速等问题,英特尔®Stratix®10和最新的Agilex™FPGA芯片,以编程的灵活性、高并发、高吞吐性能和低延迟特性,被广泛使用在各大云计算公司的数据中心中。值得一提的是,为了帮助云服务提供商转移基础设施功能任务,最大化CPU资源,获得更多收入,英特尔还提供能够清晰隔离基础设施功能和租户工作负载的,且基于FPGA和ASIC的IPU,以满足用户的多样化需求。
在软件层面,英特尔也在持续发力,最大化硬件性能。其重磅推出的oneAPI,作为统一的软件编程架构,可以支持多种异构计算单元,为上层的软件开发者提供一套应用开发接口,以解决未来应用功能在CPU、GPU等因为分布或是硬件升级后需要重写软件代码的问题。OneAPI不局限于支持英特尔硬件,也支持其他厂商的硬件。同时提供基于API的各种高性能库,可以在多种异构平台上运行并提供极高的性能,其中很多库将开源,英特尔鼓励生态协作创新,共同推动异构计算的发展与演进。
我们不难发现,异构计算的网,正在铺成智能时代的路。英特尔对于异构计算架构在软硬件层面不断进行调优与支持,软硬兼备,帮助开发者更加高效地进行数据的存储与处理,推动智能化发展进程。LaoFeNDP架构就是英特尔与快手的一次成功尝试,其证明了通过异构计算来加速不同的负载,能够显著提升在推荐等场景下的系统吞吐与延时表现。
面向未来,为构建高性能、低成本、灵活高效的异构计算平台,需要更多的技术协同应用,共同推进数据中心升级。可以预见,PCIe 5.0、DDR5、Scalable IOV、虚拟内存共享技术SVM、CXL等技术都将发光发热。当CPU、XPU、共享内存、共享存储等技术将通过智能网络架构和IPU互联,更加强大的异构计算能力和数据中心必将为数字化的世界提供源源不断的算力支撑。
