本文来自微信公众号“科技云报道”
随着野蛮增长的时代远去,精细化和效率将是未来企业竞争的胜负手。

作为一座隐形的“金矿”,日益增长的数据规模为企业发展带来了崭新机遇。
以数据为驱动的模式正备受企业重视,并且逐步从基本的可视化分析,向更高的智能化分析阶段持续进化。这个过程中,人工智能将全面落地在数据分析决策之中。
“增强分析(AugmentedAnalytics)”被视为数据分析与人工智能、机器学习结合的产物,这一概念于2017年由Gartner首次提出,并对其进行定义:增强分析是下一代数据和分析范式,它面向广泛的业务用户、运营人员和数据科学家,利用机器学习将数据准备、洞察发现和洞察共享等过程自动化。
这个概念刚开始比较模糊,后来逐渐清晰。
直接到2021年,Gartner在发布的《HypeCycle for ICT in China,2021》中做了最新的定义:增强数据分析包括机器学习(ML)和人工智能(AI),在统一的平台上提供数据管理和分析能力。
它通过将ML和AI应用于现有的操作流程中,使数据管理和分析自动化,从而更有效地进行数据分析。
它使更多的用户获得更深入的洞察力,减少了当前依赖IT处理所带来的效率问题和口径偏差。
大数据与机器学习的交汇点
大数据时代,基础数据的维度、数量、类型(结构化和非结构化)更大、更分散,企业要分析和探索的数据越来越复杂。
另一方面能兼顾专业数据分析和业务洞察的人才少之又少,增强分析正是解决这一矛盾,让数据分析普惠所有业务用户的良药。
简单地说,增强分析可以理解为借助AI技术进行智能化、自动化的数据分析,挖掘数据价值,降低分析门槛,提高分析深度。
增强分析的实现过程可以简单概括为:通过培训未知数据和已知问题,最终列出各种可能性和影响因素,帮助用户加快和进行有效的数据分析。
“增强分析”并不是说让用户会写AI或者数据科学背后的一些代码,而是说如何把它封装好、让用户依旧用非常傻瓜、简单易用的形式,比如用拖拽、自然语言的方式,去进行更高级的数据分析。
未来,我们将会越来越多地看到增强分析技术,赋能到大数据产业之中,能够让更多人以更低门槛进行更深度的分析。
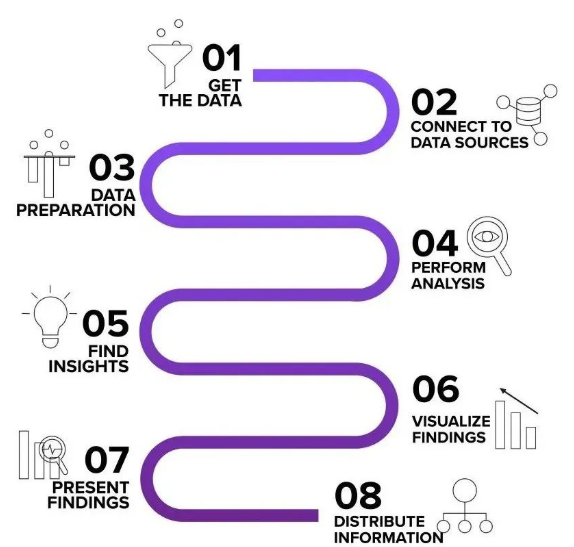
增强分析的特点是BI产品开发中最重要、最显著的发展趋势之一。
当云生态系统也影响人们做出选择决策时,增强分析能力将成为区别普通分析平台和BI平台之间的关键因素。
目前,增强分析正成为用户体验的一个重要部分,其优势包括以下几个方面:
数据准备速度增快。由于增强型数据准备可以更快地将多个数据源整合到一起,因此可以快速检测重复的操作、联接,加速获取见解和提高工作效率,从而生成完全数据自动化和高质量的建议,帮助提供个性化的用户体验。
分析偏差降低。增强型分析支持计算机执行通常用于数据分析工具的分析,通过对更大范围的数据执行操作并仅专注于统计意义因素,可以降低潜在的偏差。
信任度提高。用户和数据进行交互能够为机器学习算法提供线索,随着时间的推移,为用户提供的建议更加相关且准确,这些建议有助于获取用户的信任。
增强数据素养。通过提供对结果的自动化分析,用户可以用最少的工作量轻松地搜索见解和对见解进行可视化,从而增强数据素养。
节省更多时间。业务人员无需再花费时间收集和分析大量数据集,以及从分析结果中提取可行项,这样他们将有更多时间专注于高级业务策略和特殊项目。
增强分析三大关键技术能力
从技术角度看,增强分析相关的技术可以分为了三类:增强数据准备、增强数据分析和增强机器学习。
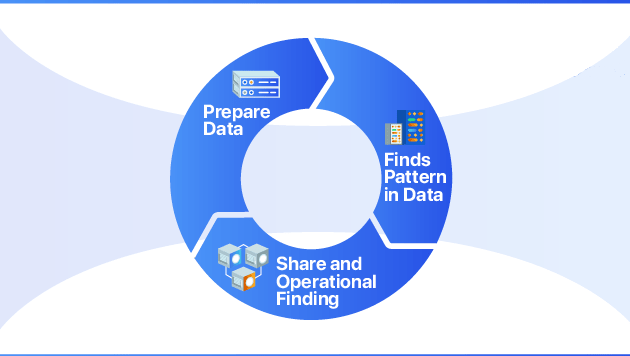
数据准备是数据分析的前提,也是最耗时的工作。
数据准备通常包含数据探查、数据质量、数据模型、数据清洗等工作,涵盖了数据管理的各个方面,甚至还包括数据集成和数据仓库的管理。
增强数据准备主要通过两个方面来提升效率,一方面是可视化交互,通过拖拉拽的方式实现可视化的数据配置、数据源的混合以及数据清洗工作,让数据准备变得更加快捷。
另一方面是算法辅助,利用ML和AI技术实现部分流程的自动化。
例如自动查找数据之间的关系,对数据质量进行评估,推荐用于连接、丰富、清洗数据的最佳方法,还有自动查找元数据和血缘关系等功能。
增强数据分析无需建模和编写代码,帮助用户自动寻找数据规律,将相关结果自动转化为可视化图表,提高分析效率。
增强数据分析的典型技术包括自动洞察(Automated Insights)和自动可视化(Automated Visualization)。
自动洞察是增强分析的核心功能,但同样也是一个宽泛的概念。
如今,大部分主流的BI平台都有自动洞察的相关功能,且方向各有不同,其目标是代替一部分分析师的工作,从数据中发现潜在信息和价值。
自动可视化则是根据数据分析结果自动选择可视化的方式进行展示,与自然语言查询(NLQ)、自然语言生成(NLG)等技术配合,大大加快整个分析流程。
增强机器学习更加关注模型,比如特征工程、模型训练、模型部署、模型解释以及最后的模型监控和管理。
与增强数据分析相比,增强机器学习面向的更多是数据科学家,通过算法将特征工程、模型选择与超参数优化,以及深度神经网络结构搜索等机器学习过程中的关键步骤自动化,帮助数据科学家更高效地得到满意的模型。
这部分的核心技术就是自动机器学习AutoML。
早期的AutoML研究起源于Meta Learning,早在上个世纪八十年代就被提出,数十年间,机器学习领域的相关研究主要集中在超参数优化。
近年来随着深度学习的广泛应用,Meta-Leaning领域在学术界又一次升温。
同时,自动化特征工程、自动化模型评价等技术的研究和商业化也使得AutoML的概念覆盖到了机器学习的全流程。
如何打好大数据与机器学习的
“组合拳”?
机器学习技术主要依赖三大因素,分别是算力、算法、数据。
大数据技术所提供的能力是机器学习建模所需要的必然基础,同时机器学习为大数据技术提供更高的智能,为商业业务产生价值。
大数据技术和机器学习技术本身就是互为因果。
虽然大数据与机器学习的融合看上去应用前景广阔,但目前许多企业客户还没有实现两者的融合。
亚马逊云科技大中华区产品部总经理陈晓建认为,主要有三方面的原因。一是大数据和机器学习目前是分而治之的。
他们本身技术发展路线是两条不同的路线,在很多企业这两个功能都是属于两个完全不同的团队来负责的,数据当然也放在不同的仓库里。
二是数据处理能力不足,很多机器学习的团队不具备处理海量数据规模的能力。三是数据分析人员参与度低。
在大数据与机器学习领域,亚马逊云科技认为,要想帮助客户解决深度数据分析的问题,就要实现大数据和AI从业务上以及用户需求上做深度融合,企业要在云中要打造统一的数据基础底座,实现大数据和机器学习的“双剑合璧”,为企业发展提供创新引擎。
为此,亚马逊云科技提供广泛而深入的服务,既能打通两个领域的数据治理底层服务,还能实现大数据与机器学习之间的相互赋能。
近日,亚马逊云科技宣布推出“云、数、智三位一体”的大数据与机器学习融合服务组合,帮助企业推进大数据和机器学习的融合,将机器学习由实验转为规模化落地实践。
该服务组合具体涵盖三个方面,分别是:构建云中统一的数据治理底座,为机器学习提供生产级别的数据处理能力,以及赋能给业务人员更加智能的数据分析工具。
亚马逊科技助力机器学习由实验转为实践,为机器学习提供生产级别的数据处理能力,不仅专门构建大数据服务,对复杂的数据进行加工处理,而且针对数据规模的动态变化,及时优化数据质量。
Amazon Athena能够对支持多种开源框架的大数据平台,包括Amazon EMR、高性能关系数据库Amazon Aurora、NoSQL数据库服务Amazon DynamoDB、Amazon Redshift等多种数据源,对这些数据源进行联邦查询,快速完成机器学习建模的数据加工。
以Amazon Redshift、Amazon MSK和Amazon EMR为代表的无服务器分析能力,可以让客户无需配置、扩展或管理底层基础设施,即可轻松地处理任何规模的数据,为机器学习项目提供兼具性能和成本效益的特征数据准备。
虽然增强分析一定程度上改变了目前的数据分析模式,但并不意味着数据分析师和数据科学家变得不再重要。
相反,这对数据科学家的专业能力提出了更高的要求,既要更多地着眼于企业数字化转型过程中数据价值的重新考量,又要追求极致的“精专主义”,毕竟简单的题目别人都会做了,留下来肯定都是硬骨头了。
