本文来自ITPUB(www.itpub.net),编译|卿云 ,原作者| Alex Woodie。
谷歌云4月6日推出了Big Lake,这是一个新的存储引擎,将其数据仓库产品BigQuery的治理与开放数据格式的灵活性和使用开放计算引擎的能力融为一体,从而进入了Lakehouse领域。此外,在其Cloud Data Summit峰会开幕式也宣布推出了BigBI预览版,它将Looker的语义数据层扩展到其他BI产品。
谷歌云不是数据湖领域的新手,它的谷歌云存储产品在兼容S3的对象存储系统中为较少结构化的数据提供了几乎无限的存储。它还通过BigQuery成为数据仓库的领导者,为结构化数据提供传统的SQL处理。
谷歌云产品管理高级总监Sudhir Hasbe表示,虽然谷歌云在提高这两个存储库的规模和灵活性方面取得了进展,但客户往往会根据他们正在处理的数据类型而倾向于使用一种存储环境。
“你从结构化数据开始,这是你在零售环境中的订单和出货量,”Hasbe在周一的新闻发布会上说。“然后是带有点击流的半结构化数据,然后在一段时间内,你有围绕产品图像和机器的非结构化数据,以及我们得到的物联网数据。”
“因此,所有这些不同类型的数据都被存储在不同的系统中,无论是结构化数据或半结构化数据的数据仓库,还是所有其他类型数据的数据湖。这些在历史上提供了不同的能力,而实际上创造了很多数据孤岛。”
Hasbe说,这些数据孤岛以及与数据孤岛相关的问题开始在BigLake中消散。
“具体来说,BigLake允许公司统一数据仓库和湖泊来分析数据,而不必担心底层存储格式或系统,”Hasbe说。“最大的优势是不必在两个不同的环境中重复数据而创造数据孤岛。”
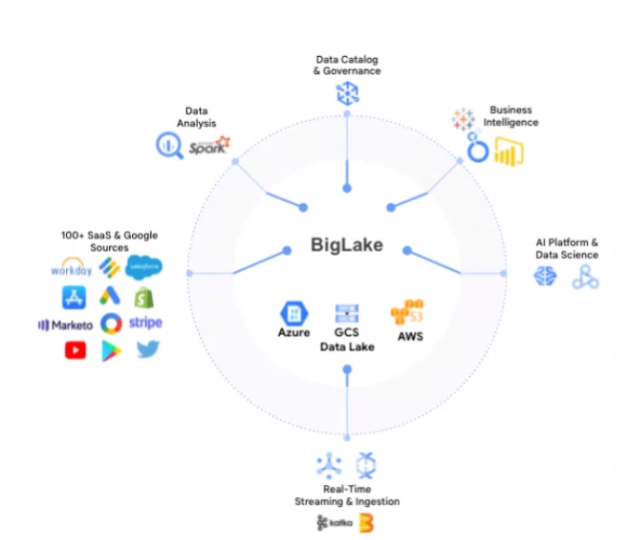
谷歌正在通过BigLake将其数据仓库和数据湖结合起来(图片来源:谷歌云)
谷歌云在BigLake上所做的是,它采用了已经在BigQuery中开发的治理、安全和性能管理功能,并将其扩展到谷歌云存储,即该公司的数据湖环境。据Hasbe说,这些功能也已经扩展到AWS和微软Azure提供的数据湖中。
Hasbe介绍,BigLake的另外两个重要组成部分是对开放标准的支持和对开放处理引擎的支持,这也是BigLake对谷歌云的数据结构解决方案Dataplex支持的组成部分。
BigLake的客户将能够以流行的开放数据格式,如Parquet和ORC,以及新兴的格式,如Iceberg,存储他们的数据。谷歌产品经理说,BigLake将使客户能够利用BigQuery的数据治理和性能管理功能来应对他们以这些格式存储的大型数据集。
“因此,这样一来,你就打破了孤岛,获得了谷歌十多年来投资的创新,而且作为组织你仍然可以继续保持原来喜欢的开放格式和开放标准。”Hasbe指出,“BigLake是我们战略的中心。基本上我们要确保我们过去所建立的所有工具和能力与BigLake无缝整合。”
Hasbe说,在处理引擎方面,客户将能够把谷歌的所有计算引擎用于存储在BigLake的数据上。这包括BigQuery引擎,此外还有Spark、DataFlow、DataProc和其他。

BigBI将提供一个共同的语义层,以便在商业智能产品之间实现一致的指标(图片来源:谷歌云)
谷歌云并不是第一个向客户提供Lakehouse产品的厂商,有趣的是,BigLake也不是谷歌云第一次接受这个概念。但是Databricks几年前推出的Delta Lake产品被认为是引领了Lakehouse,AWS也已经接受了这个架构概念。开放数据生态系统中的许多其他公司,从Dremio到Starburst,都是Lakehouse的支持者。那么,云数据仓库巨头Snowflake呢?不太支持。
“我们是时候结束管理仓库和数据湖之间的人为分离了。”谷歌副总裁兼数据库、数据分析和Looker总经理Gerrit Kazmaier说,“我们在谷歌云的创新是,我们把BigQuery及其独特的架构作为一个独特的无服务模式,一个独特的存储架构,一个独特的计算架构,我们现在把这个扩展到开源文件格式和开源处理引擎。”
谷歌还推出了BigBI的预览版,这是谷歌为统一的自助分析提供的新产品。BigBI的关键创新是将Looker的语义建模层扩展到谷歌云堆栈中的其他商业智能工具,包括Data Studio、Looker和Google Sheets,这个语义层将为各利益相关者在自助服务环境中工作时开发的指标提供急需的一致性。
Hasbe指出,缺乏标准化的指标是自助式商业智能的一个大障碍。“例如,我可以定义一个仪表板,它有一个叫毛利率的指标,”他说,“我可能在其中包括营销费用。我的同事是在商品销售部门,他们把毛利率定义为一个包括商品销售费用的指标,但不包括市场营销。”
这种缺乏标准化的情况导致了错误,这对所有人都不利。BigBI通过让每个人在涉及指标时站在同一起跑线上来解决问题。
“Looker实际上解决了这个确切的问题,它集中了一个组织中对指标的共同理解,”Hasbe继续说。“我们称其为集中式或管理式BI。因此,今天我们把这两个世界结合起来。现在你可以使用Data Studio或Tableau等工具的自助服务能力,并使用looker语义层的中心模型,你可以在一个单一的地方定义你的指标,所有的自助服务工具将与它们无缝工作。”
