IT是一个风口快速变换的产业,如何在快速变换中提前捕捉风向是众多IT企业的诉求,而这些风向变换的“蛛丝马迹”,就隐藏在用户的需求变化中。
亚马逊的创始人贝索斯曾在一个内部的高层会议上,对一群高管大发雷霆:“你们要么共享数据,要么离开公司!”公司内部不同的业务部门把持着各自的数据,不愿共享,怕共享数据降低本部门权威的事,当然不仅是发生在亚马逊。
怎么能够让跨部门、跨系统的数据更好地共享,使企业内部的数据分析专家想什么时候获得就可以获得,让高质量的数据不仅可以自动化、随时随地推送给有需求的人,同时在数据权限和隐私等各个方面做到合规,这是数字经济时代企业进行数字化转型的基石和梦想。
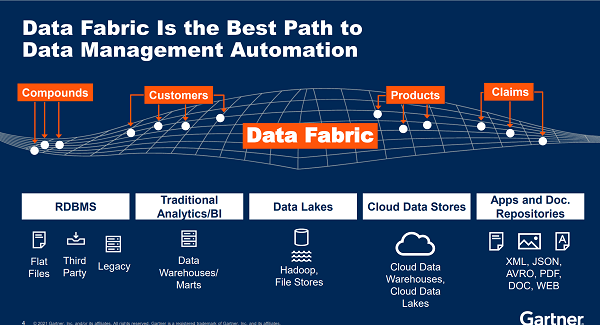
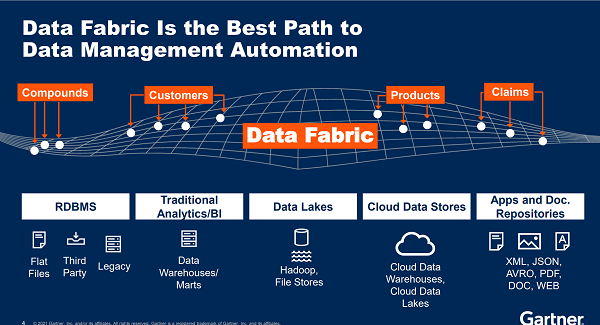
怎么实现“数据找人而不是人找数据”的梦想,“Data Fabric”悄然登场。
Data Fabric悄然登场
2018年“Data Fabric”首次出现在Gartner的十大数据与分析技术趋势中,其后的每一年,它都会如期出现在《Gartner十大数据与分析的趋势》上,2019年其位列趋势六,2020年其位列趋势三,其排位正不断前移动。
Data Fabric的中文名字到底怎么翻译,IBM公司与Gartner有了分歧。IBM大中华区科技事业部云计算与认知软件部数据与人工智能信息架构产品总监王积杰将其称为“数据经纬”,而Gartner高级研究总监孙鑫认为“数据编织”更为合适,因为他认为数据编织更凸显“动态”。
在Data Fabric出来之前,数据结构的设计都主要部署成静态基础设施,而在未来将需要采用更动态的数据网格方法全面重新设计。
孙鑫在接受记者采访时表示,Data Fabric不是一个产品而是一种设计理念,是利用AI、机器学习和数据科学的功能,访问数据或支持数据动态整合,以发现可用数据之间独特的、与业务相关的关系。
而IBM对Data Fabric的看法,与Gartner专家提到的“动态”、“数据网格”和AI赋能并无冲突,IBM解释道“数据经纬”的译法是由IBM中国研发中心首席技术官赵军伟提出,赵军伟解释说,“经纬作为名词,本意为织物的直线与横线,引申为连接万物的规律,《左传.昭公二十五年》中写道:‘礼,上下之纪,天地之经纬也。’作为地理概念,经纬度可以定位地球上任何一个位置,而‘数据经纬’则可以在纷繁复杂的企业数据目录里定位任意一个数据源。经纬用作动词,是规划治理的意思,《周书.静帝纪》中提到的‘经天纬地’就是治理天下的意思。
“我们可以把Data Fabric想象成一张虚拟的网,这张网并不能理解为一种点对点的连接,而是一种虚拟的连接,每个节点都可以是不同的数据系统,不同系统上的数据在网上都可以迅速地被定位和找到。Data Fabric的主要功能是把正确的数据,在正确的时间,给到正确的人。通过Data Fabric,对的人可以从对的地点,在对的时间,获取对的数据。”王积杰对记者说。
孙鑫认为,现在的数据连接的架构设计还主要是“人找数据”,而Data Fabric设计核心是“数据找人”,在合适的时间、将合适的数据、推送给需要的人。
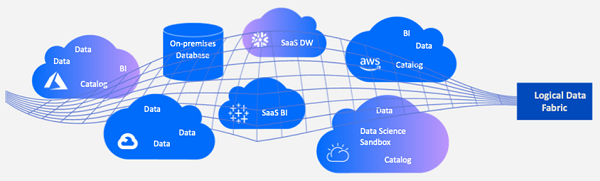
为什么Data Fabric将会成为一种趋势,为什么越来越多的企业将在未来采用这样的方式进行部署?王积杰谈及了数据利用结构模式的变化,传统IT时代,无论是早年的”数据仓库“还是近几年的“数据湖”和“大数据”时代,其实数据利用都是集中式的架构,把数据收集到一起,让企业的数据分析师、BI分析师对数据进行分析。但在云计算时代,用户业务部署在多云的环境下,要想将分布在不同云上的数据集中在一起成本很高,也很费劲,于是采用去中心化、分布式的数据网络架构就成为了必然选择。
“《通用数据保护条例》(GDPR)、《数据安全法》等越来越严的数据安全与数据监管措施的出台,想要先集中数据再进行数据分析的模式,已经行不通了。”孙鑫说。
Data Fabric可以同时给业务和技术团队带来明确的价值,王积杰表示,从业务层面来看,由于企业能更容易地获得高质量的数据,从而能更快和更精确地获得企业数据洞察。从技术层面来说,由于较少的数据复制的次数和数量,从而减少了数据集成的工作,方便维护数据质量和标准,也减少了硬件架构和存储的开销。由于减少了数据复制和大大优化了数据流程,加快并简化了数据处理过程,从而通过实施自动化的整体数据策略,减少了数据访问管理的工作。
Gartner认为,随着数据的日益复杂以及数字化业务的加速发展,Data Fabric已成为支持组装式数据分析及其各种组件的基础架构。由于在技术设计上能够使用/重复使用及组合不同的数据集成方式,Data Fabric可缩短30%的集成设计时间、30%的部署时间和70%的维护时间。IBM 7月发布的Cloud Pak for Data 4.0的软件组合增加了智能化的Data Fabric的功能,其中AutoSQL(结构化查询语言),可以通过AI来自动访问、整合和管理数据,可以帮助客户以8倍的速度、不到一半的成本,获得分布式查询的答案。
如何实现Data Fabric
究竟如何实现“数据找人而不是人找数据”,Data Fabric究竟如何“编织”?
王积杰认为Data Fabric至少需要四个维度的能力,一是能够在数据之间建立虚拟链接,简化数据访问的模式,从而减少数据复制的数量。二是需要建立一个企业的数据目录,并需要利用AI技术,自动化地实现基于语义和知识的分析,理解数据及其业务含义,并建立知识图谱,从而使数据目录变得智能化和自动化。能够让需要数据的用户,随时了解他所需要的数据在哪里、数据质量如何等。三是建立自动化的数据平台,允许用户通过自服务的方式,访问并获取数据。四是通过提供整体的自动化策略,确保数据安全,增加数据的隐私和权限保护,并提高数据的质量。
孙鑫特别强调,数据编织是一种新的设计理念,它是数据管理、数据收集理念的变化,与数据仓库、数据湖等技术并不是替代的关系,既可以运用现有的数据中枢、数据湖和数据仓库的技术和技能,也可以在未来加入新的方法和工具。
孙鑫谈到了实现Data Fabric的一些关键技术,比如增强型数据目录,要想实现数据找人,而不是人找数据,需要增强的数据目录,它要涵盖用户使用数据的频度与机制,了解数据与业务的关系,还包括知识图谱,通过知识图谱找到数据与业务之间的关系,找到元数据利用的整合策略,也包括推荐引擎以及在数据准备阶段的低代码等工具,低代码工具的作用在于降低数据使用的门槛,加速数据产品化。
从Data Fabric推动的难点来看,“一是理念层面的难题,中国的用户还没有意识到,数据利用和使用的方式已经发生改变,传统的集中收集再利用的方式已经不能满足需要。二是目前很多企业对于元数据不够重视。三从人的角度看,需要提升企业的数据工程师对知识图谱、图语言、图建模等数据工具的能力培养。四,数据编织的实现并不是找到一个厂商就能够完成,它是一个旅程需要分几步走。”孙鑫认为,从用户的角度看,率先采用Data Fabric的是金融电信行业以及数据应用场景比较复杂的用户。
在这一点上,王积杰表达了与孙鑫一致的观点,这是一个方向,但并不能一蹴而就,用户需要分步实施,关键是要意识到趋势,在接下来的项目实施中,按照Data Fabric的理念来构建。
面对新风口,国内厂商为何还不动
尽管Gartner、Forrester等分析机构在几年前就提出Data Fabric是数据利用与分析领域的革命性变革,是未来方向,但记者联系国内大数据相关领域企业进行采访,对此了解或进行布局的企业并不多,甚至找不到。
孙鑫认为,这与国内大数据厂商的分布有关,“国内有很多做数据库的企业,也有很多做BI(商业智能)的企业,但做数据整合的企业很少,而事实上,在国外做数据编织的往往是数据整合、数据虚拟化的厂商,这就很好理解为什么国内的大数据厂商迟迟未入场Data Fabric,因为这类型的企业就不多。”
从公开信息看,目前IBM、informatica和Telend等推出了针对Data Fabric的解决方案,王积杰透露IBM的Cloud Pak for Data针对上述Data Fabric必须具备的四个基本能力,都能给予很好的支持,而且在IBM内部是以前所未有的力度在推动。但除了IBM之外,那些传统关系型数据库、云数据库的大公司们目前并没有积极入场。
孙鑫认为,大厂商们没有入场很好理解,因为在Data Fabric的理念下,往往需要采用点和边新方式去描述数据关系,这需要知识图谱、图数据库等,这往往是新锐公司在做的领域,而大厂商们往往有自己的数据整合工具,他们都希望在自己的平台上进行整合。但是未来这样的局面一定会在接下来的几年发生变化。
“Data Fabric这个概念在国际上已经热起来了,但目前国内的IT用户知道的人还不多。10年前大数据的概念在国外兴起后,不到三年就被中国用户广泛接受,未来这个Data Fabric概念,中国将需要多久接受并加以应用呢?等待时间给出答案。“王积杰说。