【产品介绍】
(一)样本数据的收集和管理
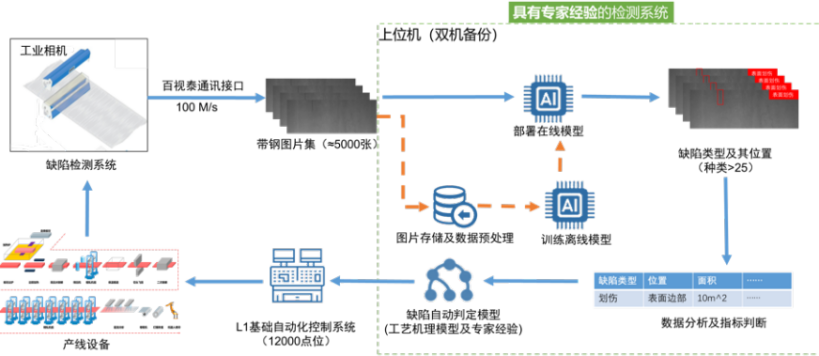
本项目所涉及的样本数据包括图像数据和生产过程中的相关参数,包括化学成分和工艺参数。对于钢铁缺陷图像数据,存在以下几个问题:部分缺陷易混淆,类间差异小;部分缺陷类内形貌差异大;样本存在小样本和长尾分布的特征;缺陷图片不能完整展现缺陷的整体形貌。因此,对样本收集造成较大的难度,在保证量的前提下,如何保质是面临的主要问题。
此外,除了图像数据的收集,还收集了包括与生成过程相关的参数(如钢种信息、材料的厚度等约30个关键参数),该部分的数据主要用于概率知识图谱的搭建。
为了保证图像样本的质量,一方面,采用数据增强、对抗网络生成小样本的缺陷图片,解决数据量不均衡的问题;另一方面,建立一套数据质量评价方法,基于交叉验证等手段,验证数据的一致性,保证数据的质量。
(二)结合专家经验的模型搭建
专家经验主要指专家根据多年的生产经验总结得到的判定机理模型,产品的化学成分、工艺参数与缺陷之间的关系等。同时,通过对既往生产数据进行数据分析,挖掘缺陷与设备生产数据之间的关联,并通过知识图谱等形式进行表示。通过将上述专家经验、机理模型,挖掘参数与图像模型算法进行有机融合,作为一个特征融入到图像模型当中,使得训练的模型理解图像和工艺参数,不仅看到图像的表面,更能洞悉背后的工业逻辑和复杂性。这种融合专家经验的模型,极大地增强了我们处理图像数据的能力,解决了传统图像处理方法可能遇到的局限和缺陷。
(三)智能表检大模型开发
为了满足实际的现场需求,针对客户的操作习惯,尤其是工业现场的使用特点,开发了一套具备数据收集、数据管理、模型训练和部署的表检配套工业大模型。该模型的开发基于B/S架构,表检结果数据存储在云端,满足客户在不受时空限制的条件想,随时在线查看缺陷的,有助于上下游用户对产品的质量的追溯和把控。
本项目关键指标参数包括分类准确率和判定准确率,分别为缺陷分类准确率和时间。21类缺陷平均分类准确率至90%,分类时间不超过180秒。其中,严重等级较高的缺陷要达到95%以上,较低的缺陷要达到75%以上。
【技术优势】
在钢铁产品的表面缺陷检测领域,华院计算致力于开发一个划时代的基于表检大模型的智能检测平台,它融合了最新的技术成果,以实现对产品质量的全面把控。以下是本项目的技术优势:
1.多模态神经网络的创新设计。设计了一个多模态网络架构,它能够同时处理缺陷图像、专家知识与生产中设备的运行数据。这种融合了专家知识与生产数据的多模态网络设计显著提升了模型的推理和语义理解能力,使其能够更深入地洞察数据背后的复杂关系。
2.小样本学习与数据增强。面对钢铁产品缺陷的长尾效应和分布不均衡问题,采用了小样本学习技术和数据增强技术。这些技术使我们的平台能够高效地处理那些罕见但关键的缺陷类型,即使它们的发生频次较低,也能被模型准确地捕捉和识别。
3.多任务多尺度缺陷检测集成模型。为了满足不同尺度缺陷类型的检测需求,搭建了一个多任务多尺度集成模型。它不仅能够快速准确地识别各种缺陷,还能够保证检测速度与实际生产节奏相匹配,从而大幅提升生产效率。
4.自学习技术的开发。鉴于钢厂产品调整和产线改造的频繁性,我们开发了自学习技术。这一技术能够对模型的误解、漏检以及置信度较低的缺陷进行持续的收集和训练,确保模型性能始终与时俱进,满足当前的生产需求。
5.自动标注与类激活映射。为了提高缺陷标注的效率,我们基于无监督学习技术开发了自动标注系统。该系统能够对无监督信息的样本数据进行特征聚类,并利用类激活映射的方法实现特征的可视化。通过图像处理技术,我们最终实现了缺陷的自动标注,极大地提升了标注工作的效率和准确性。
6.基于专家知识的缺陷自动判定模型。在实际生产中,我们深知判断钢卷是否为良品或不良品需要综合考虑下游客户的需求、缺陷分类结果以及专家经验。因此,开发了一个基于专家知识的缺陷自动判定模型,它能够对缺陷类型、数量、大小及分布情况进行综合分析和判定,从而提供更为精准的质量评估。
通过这些创新的技术手段,华院的智能检测平台将成为钢铁行业质量控制的强大助手,不仅能够提升检测的准确性和效率,还能够为产品的持续改进提供有力的数据支持。这标志着我们在智能制造和质量控制领域迈出了坚实的一步。