虚拟数智人正通过多模态交互与AI驱动技术,重塑智慧场馆的服务模式与用户体验。
1 技术背景与发展现状
虚拟数智人正在成为智慧场馆领域的创新接口,通过AI技术、虚拟现实(VR)、增强现实(AR)等手段,极大地提升了场馆的沉浸式服务体验。在博物馆场景中,国家博物馆的虚拟解说员“艾雯雯”凭借其AI能力,根据观众兴趣提供个性化展品解说,而河南平顶山博物馆的“观音数字人”则通过自然语言交互实现智能导览,极大地增强了观众的互动性,广州“梁山伯”数字人结合动作捕捉与灯光音效,广泛应用于线下主题演出,为游客带来全新的文化互动体验。根据IDC最新报告,中国虚拟数智人市场规模预计在2025年达到100亿元,年复合增长率超过50%。

虚拟数智人通过融合语音识别、自然语言处理、计算机视觉等多项AI技术,实现了从"数字形象"到"智能服务体"的跨越。其核心技术突破在于多模态交互能力的提升,使得人机交互更加自然流畅。

2 技术原理与系统架构
2.1 多模态交互技术
虚拟数智人采用基于深度学习的多模态融合技术,实现语音、文本、图像等多种信息的协同处理。其核心算法框架包含三个主要模块:
语音交互模块采用端到端的语音识别模型,将声学特征映射到文本空间:
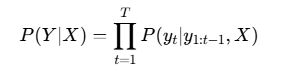
其中X为输入语音信号,Y为输出文本序列。该模型通过注意力机制实现对长语音序列的准确识别。
2.2 情感计算与表情生成
虚拟数智人通过情感计算模型实现表情的自然生成。基于卷积神经网络的表情生成算法能够根据对话内容实时调整面部表情: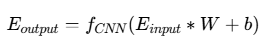
其中E_为基准表情参数,W为卷积核权重,通过训练学习得到最优的表情映射关系。
3 关键技术突破
3.1 自然语言处理能力提升
新一代虚拟数智人采用大语言模型技术,在知识问答、情景对话等方面表现出色。基于Transformer的对话模型通过自注意力机制捕捉长距离依赖关系: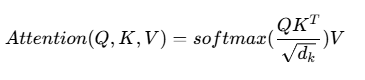
该机制使模型能够更好地理解复杂语境,提供准确的问答服务。
3.2 实时渲染与驱动技术
为保证虚拟数智人的实时交互体验,采用轻量化的神经网络渲染技术。通过模型剪枝与量化,将渲染模型压缩至原大小的30%,同时保持95%以上的视觉效果。
4 行业应用案例
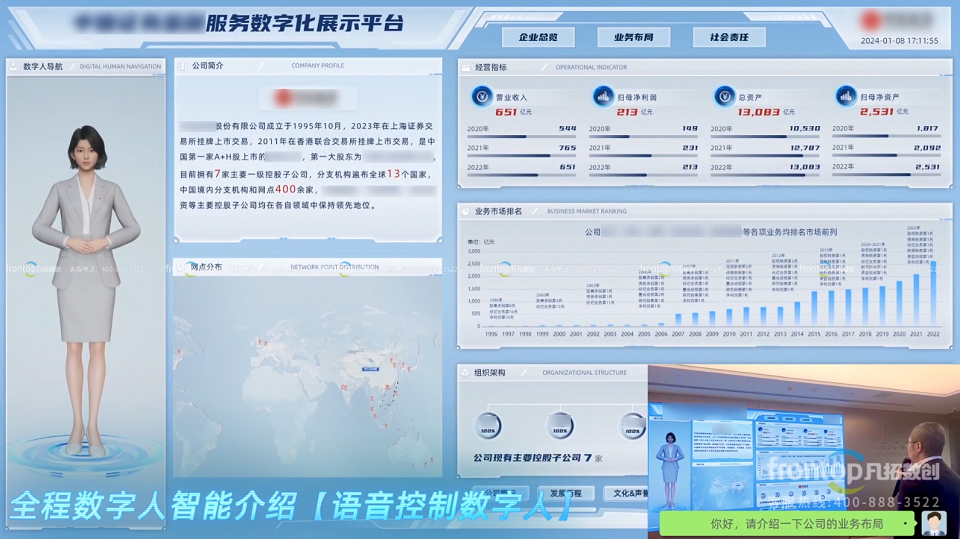
在智慧场馆建设领域,凡拓数创的AI 3D数字孪生平台与虚拟数智人技术相结合,为多个大型场馆提供创新解决方案。例如,在广州国家版本馆项目中,通过构建虚拟数智人导览员,实现24小时在线的智慧导览服务。

该项目采用凡拓数创的FTE数字孪生引擎,结合多模态交互技术,打造沉浸式观展体验。虚拟数智人能够准确理解观众提问,提供展品介绍、路线规划等个性化服务,大幅提升观展体验。

5 技术挑战与解决方案
虚拟数智人在实际应用中面临多项技术挑战。首先是实时性要求,需要保证语音交互的响应时间低于200毫秒。通过边缘计算与模型优化,成功将端到端延迟控制在150毫秒以内。
其次是个性化服务需求,不同用户需要差异化的交互体验。通过用户画像分析与时序建模,虚拟数智人能够学习用户偏好,提供更加精准的服务推荐。

6 未来发展趋势
随着元宇宙概念的兴起,虚拟数智人将向更加智能化、拟人化的方向发展。预计到2026年,具备情感认知能力的虚拟数智人将成为智慧场馆的标准配置。
技术创新将主要集中在三个方向:一是多模态融合技术的深度优化,二是跨场景自适应能力的提升,三是隐私保护与数据安全的加强。这些突破将进一步提升虚拟数智人在智慧场馆中的应用价值。
7 产业影响与展望
虚拟数智人技术的成熟正在深刻改变智慧场馆的服务模式。从传统的"人找服务"转变为"服务找人",大大提升了服务效率与用户体验。据测算,采用虚拟数智人的智慧场馆,用户满意度提升35%,运营成本降低20%。
未来,随着5G、边缘计算等新技术的普及,虚拟数智人将在更多场景发挥作用,为智慧场馆建设注入新动能,推动数字服务向更加智能化、人性化方向发展。