作为数据领域技术名词解释的第一篇,讲讲数据湖,因为我认为数据湖是现代分析型数据架构的核心。
01
什么是数据湖
数据湖是BI厂商Pentaho的CTO James Dixon在2010年提出的。当时流行的是数据仓库或数据集市架构,实施周期长,就算实施完了,也支持不了预设之外的灵活分析需求,因为没有原始数据。作为同行,我想我能深刻体会Dixon当时的心情,一堆人投进去啃哧啃哧干了几个月,完了客户说我想干啥你怎么还是支持不了呢,验收回款就别想了,那个欲哭无泪啊。当时线下的Hadoop和云上的S3都已经起来了,所以Dixon就想,不如先把数据都导进来,反正Hadoop或S3这样的平台成本低计算能力强也好扩展,这样不就想做什么分析都可以做了吗。Dixon就是基于这样朴素的思想提出数据湖这个概念。
数据湖的概念不复杂。Gartner对数据湖的定义是:
A data lake is a concept consisting of a collection of storage instances of various data assets.These assets are stored in a near-exact,or even exact,copy of the source format and are in addition to the originating data stores.
大致意思就是说数据湖是一个存储各种比较“原始”的数据资产的存储系统。今天在云下主要是Hadoop体系,云上除了Hadoop,还有S3、OSS这样的对象存储,或者Snowflake这样背后使用对象存储的云原生数仓(这点存疑)。
我觉得Gartner的定义准确,但有点过于精简,没有体现数据湖的丰富内涵。我认为除了Gartner提到的原始数据,还有以下两个内涵也是非常重要的:
标准接口:数据湖一定有一个被业界广泛接受的标准接口,比如存存储层面的HDFS、S3和格式层面的ORC、Parquet。有了标准接口,各个来源的数据才能顺畅的流到湖里来,各种计算引擎、分析工具才能顺畅的对接湖里的数据做分析计算。
超低成本:要不是HDFS、S3这样的存储平台成本超低,哪能把原始数据都弄到湖里冗余一遍。这个成本是相对的,我们互联网人觉得还是挺贵啊,因为我们规模太大了,后来一看传统数据仓库的价格才知道相对而言数据湖存储确实已经是“超低”了。
综合一下,我认为:数据湖是一个存储各类结构化、半结构化甚至非结构化原始数据,提供标准接口支持各类数据源和分析工具,成本超低的存储系统。
01
数据湖是现代分析型数据架构的核心
现代数据分析是一个极其庞大的技术体系,有好多种计算引擎如Hive、Spark、Flink、Impala、Presto、CH,有数据科学平台、机器学习框架,有数不清的BI工具(见数据基础设施创新如火如荼,主要方向有哪些(上))。在这个复杂体系中,有没有一个技术是居于核心地位的呢?
数据湖就是核心。
美国风投机构a16z在去年提出了一个分析型数据架构(如下图所示),被很多其他分析师引用,很有影响力。a16z的创始人是大名鼎鼎的Marc Andreessen,他们对24位数据领域的大咖做了深入访谈,总结出下图的架构。可以看出,数据湖处于当仁不让的中心位置。数据湖汇聚了所有类型的数据,更重要的是数据湖还支持了所有类型的分析范式,包括数据仓库、数据科学、机器学习、即席查询、实时分析等等等等。
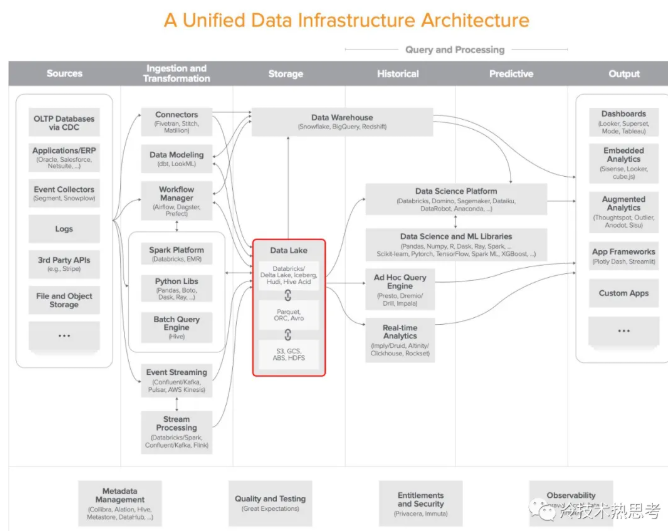
老的核心正在被数据湖取代。如果说经典的分析型数据架构的核心是数据仓库或数据集市的话,那么他们很快就会被数据湖所包养了,也就是这两年流行起来的湖仓一体架构。湖仓一体指的是仓在湖里,只是数据湖中的一块水域,一类应用而已。
很多时髦的概念都离不开数据湖。比如最近很多人说要ELT,不要ETL。ELT就是先把数据load进来,分析时再根据需要transform。load到哪里呢?当然是数据湖。在比如Snowflake火了后云原生数仓的概念也瞬间时髦起来,其实云原生数仓的核心就是存算分离,而存在哪里呢?又是数据。
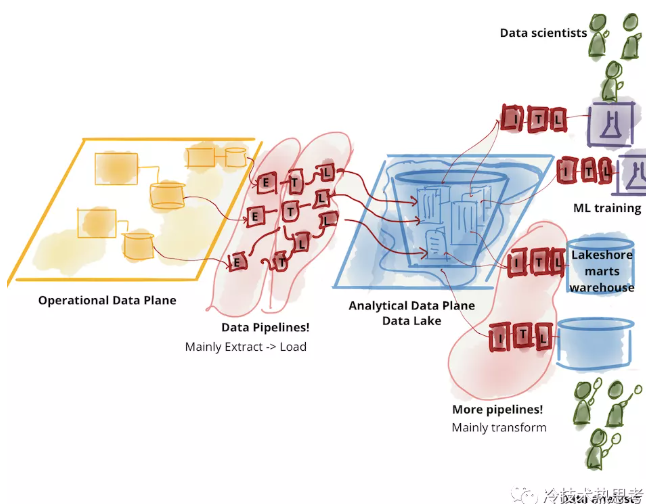
就连那些号称反对数据湖的技术其实都反不了数据湖,反而会进一步强化数据湖。业界有这么几个号称反对数据湖的概念:Data Mesh、Data Fabric、Data Virtualization。这些技术的提出者(包括大名鼎鼎的Gartner和ThoughtWorks)把数据湖想象成是下面这样的一大坨,一个超级大湖,要劳师动众把所有数据通过一大团ELT搬进来,使用的时候可能还需要另外一大团ETL。这样看当然会觉得搬运成本太高,湖太大很难治理,很容易成为臭气熏天的“数据沼泽”。但这是不对的,因为数据湖并没有存储所有数据的意味。数据湖强调的是可以存储多种类型的数据、支持多种类型的分析范式,从来没说过要存储所有数据,*存所有数据那是数据洋啊,咋能叫数据湖呢*。这只是某些CEO、CIO、CTO们想建一个超级大湖体现政绩带来的问题,不是数据湖本身的问题。过度集中不好不能说东西不好。关系数据库好,但把所有交易数据都放到一个库当然也不好;大楼好,但一个城市就建一座大楼当然也不好。Data Mesh、Data Fabric和Data Virtualization都强调不要过于集中化,要分布式治理,在我看来这些理念都是好的,但是说这些技术反对数据湖是没道理的,他们反对的是集中制。另一方面,这些技术一定会强化数据湖的采用,因为分散了之后,每个单元都要考虑为其他单元提供数据分析服务,这对分析的要求就更灵活,而支持灵活的分析范式,正是数据湖最擅长的。在我看来,这些技术只是把一个大湖变成多个小一些的湖,最后的结果是分布式数据湖或逻辑数据湖。反对数据湖,最后到处都是湖。“杀不死,反而更强大”,这就是强者。
数据湖有强大的技术生态。一个技术要成为核心,生态非常重要。数据湖现在有Hadoop、对象存储、DeltaLake/Hudi/Iceberg等好几个实现ACID的技术。Hadoop和对象存储都是发展了十多年。Hadoop云上云下很多厂商都在做,就是没养出世界顶级的厂商,但厂商不赚钱恰恰是客户得利啊。对象存储原来是云巨头的标配,现在云下的MinIO等也开始发展起来。实现ACID的数据湖技术可以支持湖仓一体、批流一体,虽然现在都还不成熟,但一下子就三个竞争,态势很好。有这样的生态在,数据湖肯定会变得越来越价廉物美。
所以,数据湖是转型现代分析型数据架构的核心,只是要注意不要过度集中,可以分散、分步建设,比如各BU有各BU的湖,集团有集团的湖。
01
为什么数据湖能成为核心
作为架构师,还值得思考为什么数据湖能成为现代分析型数据架构的核心而不是其他的技术。a16z的架构体现了数据湖的核心位置,但这是结果,不是原因。数据湖为什么有今天的核心地位,背后有一系列深层次的原因。
首先,数据湖很好的匹配了大数据的特性。大数据的特性统称4V:Volumn、Velocity、Varity和Value。数据湖定位于存储各种类型的原始数据,恰好满足了大数据的大容量(Volume)、高通量(Velocity)和多样化(Varity)的需求,而大数据具有大价值(Value)的特性则保障了数据湖的投资回报。舍恩伯格在《大数据时代》一书中总结的大数据时代思维变革的第一条就是“要全体数据而非抽样数据”,数据湖存储原始数据可谓恰逢其时。
其次,数据湖具备成为平台型软件的有利条件。最核心的技术软件是平台型的软件,这类软件构建了一个软件架构中的双边市场,并占据此双边的中心位置。如操作系统,向下管理各类资源,向上支持各类中间件和应用。数据湖完全是一样的格局,向下汇集各类数据,向上支持各类分析范式。
最后,数据湖还有对象存储的神助攻。对象存储来自于云,本来主要是用来存文档、图像,提供在线服务的,和分析本来没啥关系,但因为其成本超低,接口灵活,结果摇身一变又成了很好的数据湖存储系统。这就是《伟大创意的诞生》一书中说的“功能变异”。本来数据湖领域有一个蛮大的问题是HDFS技术不太给力,现在很多人喊“Hadoop已死”,有了对象存储,就算哪天Hadoop真死了,数据湖也不会死。
你看,数据湖符合时代精神,一出场就有成为平台型软件的范,还有对象存储的“天助我也”,成为核心也就理所当然了。
