HDFS是一套基于区块链技术的个人的数据存储系统,利用无处不在的私人PC存储空间及便捷的网络为个人提供数据加密存储服务,将闲置的存储空间利用起来,服务于正处于爆发期的个人数据存储市场。
HDFS属于什么结构体系?
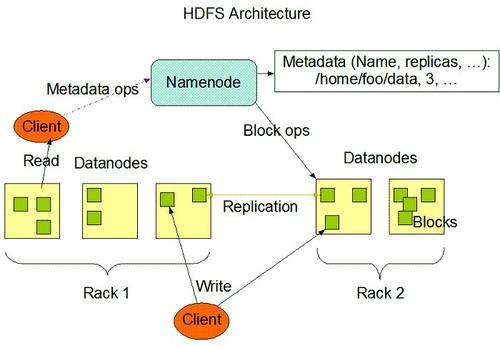
1、HDFS框架分析
HDFS是Master和Slave的主从结构。主要由Name-Node、Secondary NameNode、DataNode构成。
NameNode
管理HDFS的名称空间和数据块映射信存储元数据与文件到数据块映射的地方。
如果NameNode挂掉了,文件就会无法重组,怎么办?有哪些容错机制?
Hadoop可以配置成HA即高可用集群,集群中有两个NameNode节点,一台active主节点,另一台stan-dby备用节点,两者数据时刻保持一致。当主节点不可用时,备用节点马上自动切换,用户感知不到,避免了NameNode的单点问题。
Secondary NameNode
辅助NameNode,分担NameNode工作,紧急情况下可辅助恢复NameNode。
DataNode
Slave节点,实际存储数据、执行数据块的读写并汇报存储信息给NameNode。
2、HDFS文件读写
文件按照数据块的方式进行存储在DataNode上,数据块是抽象块,作为存储和传输单元,而并非整个文件。
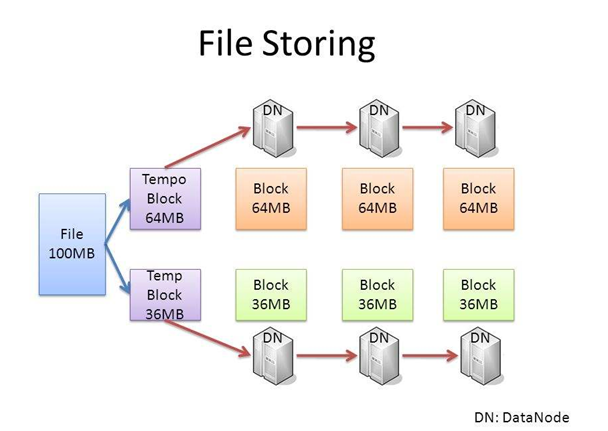
文件为什么要按照块来存储呢?
首先屏蔽了文件的概念,简化存储系统的设计,比如100T的文件大于磁盘的存储,需要把文件分成多个数据块进而存储到多个磁盘;为了保证数据的安全,需要备份的,而数据块非常适用于数据的备份,进而提升数据的容错能力和可用性。
数据块大小设置如何考虑?
文件数据块大小如果太小,一般的文件也就会被分成多个数据块,那么在访问的时候也就要访问多个数据块地址,这样效率不高,同时也会对NameNode的内存消耗比较严重;数据块设置得太大的话,对并行的支持就不太好了,同时系统如果重启需要加载数据,数据块越大,系统恢复就会越长。
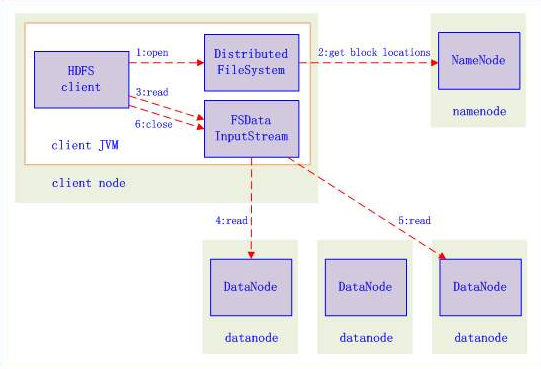
3.2.1 HDFS文件读流程
1、向NameNode通信查询元数据(block所在的DataNode节点),找到文件块所在的DataNode服务器。
2、挑选一台DataNode(就近原则,然后随机)服务器,请求建立socket流。
3、DataNode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)。
4、客户端已packet为单位接收,现在本地缓存,然后写入目标文件,后面的block块就相当于是append到前面的block块最后合成最终需要的文件。
3.2.2 HDFS文件写流程
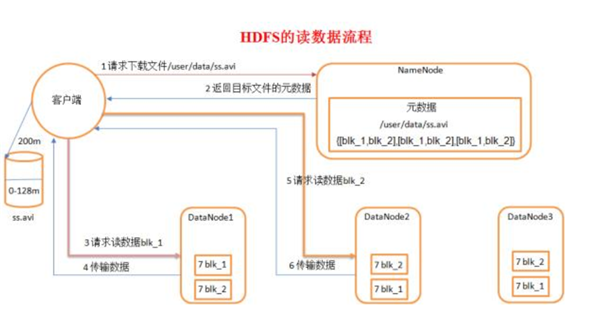
1、向NameNode通信请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
2、NameNode返回确认可以上传。
3、client会先对文件进行切分,比如一个block块128m,文件有300m就会被切分成3个块,一个128m、一个128m、一个44m。请求第一个block该传输到哪些DataNode服务器上。
4、NameNode返回DataNode的服务器。
5、client请求一台DataNode上传数据,第一个DataNode收到请求会继续调用第二个DataNode,然后第二个调用第三个DataNode,将整个通道建立完成,逐级返回客户端。
6、client开始往A上传第一个block,当然在写入的时候DataNode会进行数据校验,第一台DataNode收到后就会传给第二台,第二台传给第三台。
7、当一个block传输完成之后,client再次请求NameNode上传第二个block的服务器。
HDFS致力于用全新的技术解决方案、商业思维、经济模型建立一套的满足现有用户个人隐私数据、商业数据、可信数据的存储需求的全新数据存储解决方案。这就是HDFS数据分布式存储的整体结构。
