想学好大数据,首先要了解他的基础,所以,我们需要先了解HDFS和Hadoop以及MapReduce。
首先大家思考一个问题:如何合理的存储10T的电信通话记录?
下面给大家展现一个图片:
大数据之初步了解HDFS、Hadoop和MapReduce
入的知识点:
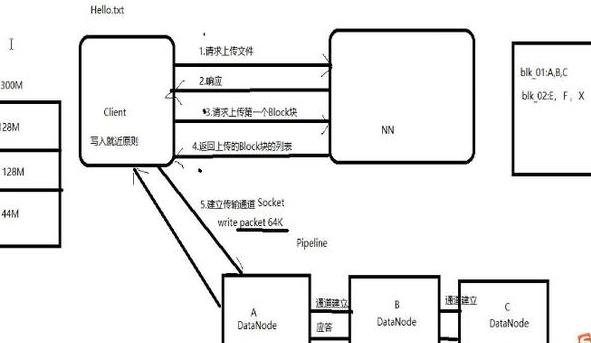
元数据:描述数据的数据,主要描述数据的属性的信息,用来指示存储位置,历史数据文件查找和文件记录等功能;
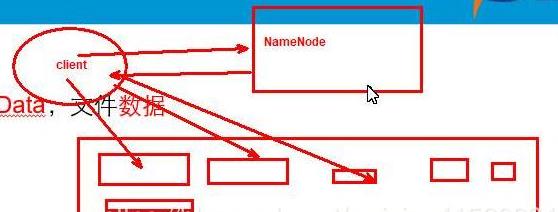
NameNode:文件管理
DataNode:真是存储数据,数据存储
Client:文件获取,客户端实现读取,
这里面体现的一个思想就是分布式存储。
将数据分散存储在多台独立的设备上,传统的存储方式存在系统性能的瓶颈,同时在可靠性和安全性上也存在问题,不能满足大规模存储应用的需要。分布式网络存储采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,他不但提高了系统的可靠性,可用性和存取效率,还易于扩展。
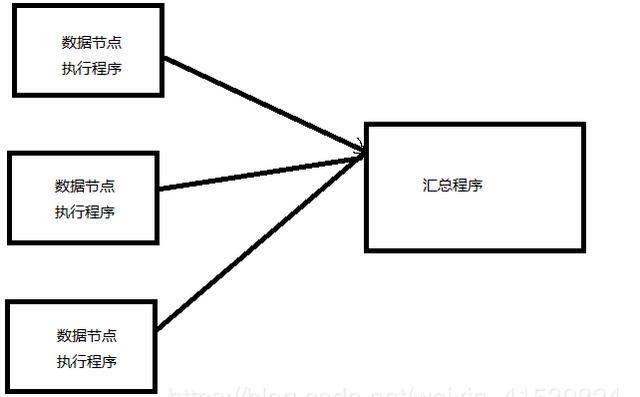
分布式计算(100G数据,统计单词)
计算向数据移动,
大数据之初步了解HDFS、Hadoop和MapReduce
HDFS:Hadoop分布式文件系统(冗余备份)
Map/Reduce:是一个使用简易的软件框架,基于他的应用程序能够运行在上千个商用机器组成的大型集群上,...;
核心思想:分而治之;map(任务分解),reduce(结果的汇总)
Hadoop的两大核心:HDFS和MapReduce
Hive:数据仓库,面向分析处理OLAP(联机分析处理)
RDMS:传统的关系型数据库,面向业务处理PLTP(联机事务处理)
HBase:非关系型数据库,主要存储非结构化数据,面向列处理方式;
Flume:大数据的数据采集工具
Sqoop:数据转移工具(将关系型数据库数据转移到HDFS(可逆))
Zookeeper:分布式协调系统(目录树结构、时间回调、客户端Session)
JobTacker:任务分解
TaskTracker:执行任务
Block:最小1M,默认128M,副本有三个(是连同原始文件一共三个,没有等级之分),分配在不同的节点上,为了可靠性和
完整性,副本数的数量不能超过集群节点的数量,可调整大小,但是会带来蝴蝶效应;
心跳机制:每隔几秒汇报一次;
HdfsClient与NameNode交互元数据信息
HdfsClient与DataNade交互文件Block数据
大数据之初步了解HDFS、Hadoop和MapReduce
NameNode分为两类:
动态元数据:Block块的位置信息(通过DataNode心跳的方式来给NameNode汇报);
静态元数据:文件大小,节点信息,偏移量,block清单;
Client大致分为两类:集群外的客户端和集群内的客户端
Client和NameNode交互的是元数据
Client和DataNode交互的Block块数据
交换:运行时内存和磁盘的双向交互叫交换,运行时从磁盘读取数据到内存
持久化:单向的,运行时会往磁盘中写数据,当出现挂机或重启时从磁盘读回。
Block块的位置信息,不会做持久化;
Edits:存放的是客户端对元数据增删改查的操作;
Editlog:可以做到挂机前的最后一笔操作
fsImage:只能做到某一时点的内存状态;
合并:3600秒,或者64M
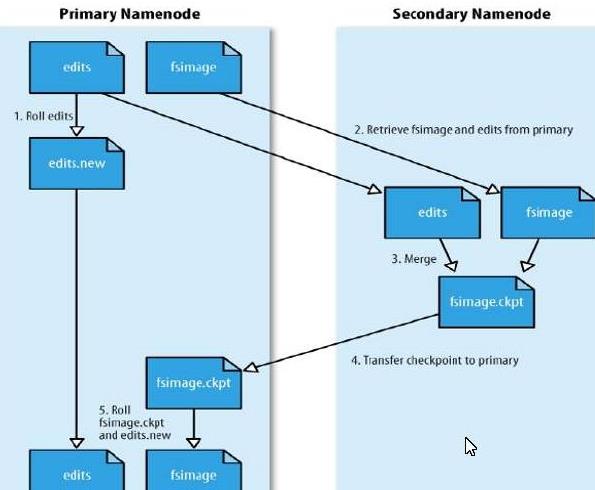
SNN合并流程
大数据之初步了解HDFS、Hadoop和MapReduce
sencongdary NameNode是减少NameNode的启动时间,