1.1.1.僵尸网络常见的检测方法
DNS解析记录分析法
该方法的理论基础是,bot一定会通过域名来连接C&C服务器,而且C&C服务器的域名带有一定的特征,比如可读性差,字符都是随机生成,请求频率低等。不过这种假设条件一定会带来大量的误报,导致实际的产品还不能以这种检测方法为主。
基于威胁情报的DNS解析分析法是一种较为可行的方案,通过C&C服务器的域名情报共享和更新,实时检测僵尸主机的C&C连接,这种机制对威胁情报的准确性和及时行提出了相当高的要求,在实际环境中威胁情报能否达到预期?用Mirai的作者在论坛中说的一句话来回答:people try to hit my CNC but I update it faster than they can find new IPs.
异常流量分析法
僵尸网络发起攻击(一般是DDoS)时会产生大量的攻击流量,这些流量的统计指标会显著区别于正常的流量,因此通过分析流量日志也可以检测出疑似的僵尸主机。对于已经感染却尚未发作的僵尸主机无效,对于攻击流统计特征不明显的情况(比如攻击流量较小)也无效。
流量特征分析法
僵尸主机的通信流量一定会有特征,通过对数据包payload的深度检测,对比已知的特征即可发现僵尸主机。这种方法准确率和效率都比较高,但只能检测已知的僵尸主机,对于未知的僵尸网络无能为力。
综合来看,目前最有效的检测方法还是用流量特征分析法,保证已知的僵尸主机可以被精确的发现。
1.1.2.僵尸网络检测目标
僵尸网络的检测一定要符合“普适”和“精准”两个原则。普适,就是说检测机制不能仅对某一种或者某一类僵尸网络生效,也不能仅仅对已知的僵尸网络有效;精准,是说最终检测的结果一定要定位到具体的主机(无论是宿主机还是虚拟机),不能仅仅是一个IP地址。
为了达到普适的原则,就一定要做到无论已知僵尸网络还是未知僵尸网络都能检测,要做到高检出率,低误报率,而且要区分出不同的僵尸网络。在现实环境中,肉鸡往往隐藏在NAT之后,僵尸网络检测设备只能定位到公网IP地址这一层次。为了实现“精准”检测的原则,就需要多设备联动,以便找到NAT之内的“肉鸡”。
本文后面的章节会提出一种符合“普适”原则的僵尸网络检测算法,Plantern算法。
1.1.3.Plantern算法
Plantern是“植物大战僵尸”里面的道具----灯笼草,一个会发光的植物,可以让隐藏在迷雾中的僵尸们无所遁形。Plantern算法的目标也是要让隐藏在网络中的“僵尸”暴露在人们眼前,并且还要分清楚目标到底是“铁桶僵尸”还是“撑杆僵尸”。
为了达到这一目标,我们需要重新定义僵尸网络。尽管其形态各异,有集中式,有P2P式,有DDoS攻击型,有发垃圾邮件型,但经过我们研究发现,僵尸网络的本质特征就是以下2条:
1)一组运行相同恶意软件的实例(无论是pc,服务器还是虚拟机)。
2)有相同的C&C通信通道。
所有满足以上两条,且实例数量不少于2个的组合,就是一个僵尸网络。
1.1.4.框架模型
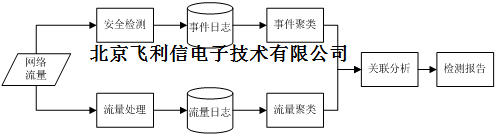
根据3.1.3关于僵尸网络的定义,Plantern模型主要从两个维度对网络流量进行分析,一个是从流量的处理和聚类,目的是找到模式相同的C&C通信通道;一个是从安全事件角度,通过事件的聚类和相似性计算,找到类似的恶意行为模式,然后通过两者的关联分析,进一步加强BOT主机检测的可靠性和准确率。完整的模型框架图如下所示。
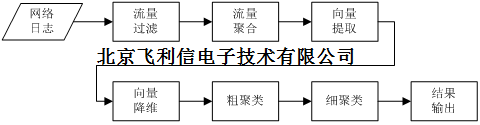
1.1.5.流量聚类
网络流量日志会包含IP五元组(源IP,源端口,目的IP,目的端口,传输协议),时刻,时序时长,双向数据包个数,双向数据字节数等基本信息,我们定义描述一条完整网络连接的信息集合叫一条基本流;我们定义拥有相同源IP,目的IP,目的端口和传输协议的流量叫通信流,一个通信流会包含多条基本流,从基本流到通信流的映射过程就是流量聚合。
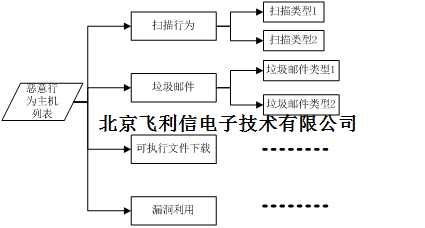
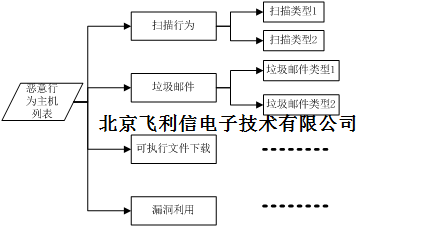
1.1.6.事件聚类
我们把安全事件的聚类分为两级,第一级按行为的类型进行初步分类,例如扫描行为,发送垃圾邮件行为,下载可执行文件,漏洞利用或者探测行为等,然后对每一种类型再进行细划分,例如针对扫描行为,可以依据扫描的端口,扫描速率等划分子类;对于垃圾邮件可以计算其邮件内容的相似度,或者邮件服务器的重叠度等划分子类;可执行文件下载,可以简化为下载相同的可执行文件的就是一个子类;每一个子类都会包含一个主机列表。
安全事件的来源可以随时扩展,不仅仅局限于IDS,主机日志,还可以利用威胁情报等来丰富安全事件的感知能力。
1.1.7.关联分析
有了事件聚类和流量聚类两个结果,下一步就通过关联这两个结果,对每一台主机进行受控可能性进行量化计算。
关联分析的基本思想是这样,每一种恶意行为都有不同的权重代表其危害的严重性,权重由人来指定一个不小于1的数字表示。而且每一种恶意行为的细分类中都会包含个主机列表,当我们对主机host进行受控可能性打分的时候,首先筛选出包含host的所有恶意行为分类集合。打分算法中,当主机host的恶意行为越多,或者和host有一样恶意行为的主机越多,host的分数越高,另外当包含host的恶意行为分类内的列表,与流聚类的某已分类的重叠度越高,就说明和主机host有相似数据流模式的主机越多,同样也会造成host的受控打分变高。
关联分析的基本思想抽象成计算公式,如下: