前言
表格存储Tablestore是阿里云自研的面向海量结构化数据存储的Serverless NoSQL多模型数据库。Tablestore在阿里云官网上有各种文档介绍,也发布了很多场景案例文章,这些文章收录在这个合集中《表格存储Tablestore权威指南》。值得一提的是,Tablestore可以支撑海量的数据规模,也提供了多种索引来支持丰富的查询模式,同时作为一个多模型数据库,提供了多种模型的抽象和特有接口。本文主要对Tablestore的存储和索引引擎进行介绍和解读,让大家对Tablestore引擎层的原理和能力,索引的作用和使用方式等有一个认识。
基本架构
Tablestore是一款云上的Serverless的分布式NoSQL多模型数据库,提供了丰富的功能。假设用户可以采用各种开源组件搭建一套类似服务,可以说是成本非常高昂,而使用Tablestore仅需在控制台上创建一个实例即可享受全部功能,而且是完全按量计费,可以说是0门槛。
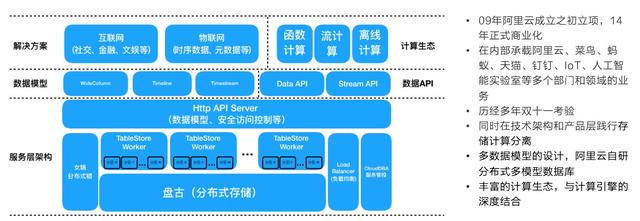
整体架构如下图所示,本文不展开叙述每个模块的功能。
在服务端引擎层中,存在两个引擎:存储引擎和索引引擎。这两个引擎的数据结构和原理不同,为了方便读者理解,本文将这两个引擎称为表引擎(Table)和多元索引引擎(Searchindex)。整体来说,引擎层是基于LSM架构和共享存储(盘古),支持自动的Sharding和存储计算分离。
表引擎
表引擎的整体架构类似于Google的BigTable,在开源领域的实现有HBase等。
数据模型可以定义为宽行模型,如下图所示。其中不同的分区可以加载到不同的机器上,实现水平扩展:

首先说明一下为什么Tablestore的主键可以包含多个主键列,而像HBase只有一个RowKey。这里有几点:
多列主键列按照顺序共同构成一个主键,类似MySQL的联合主键。如果使用过HBase,可以把这里的多列主键列,拼接起来看作一个RowKey,每一列其实都只是整体主键的一部分。
第一列主键列是分区键,使用分区键的范围进行分区划分,保证了分区键相同的行,一定在同一个分区(Partition)上。一些功能依赖这一特性,比如分区内事务(Transection),本地二级索引(LocalIndex, 待发布),分区内自增列等。
业务上常需要多个字段来构成主键,如果只支持一个主键列,业务需要进行拼接,多列主键列避免了业务层做主键拼接和拆解。
许多用户第一次看到多列主键列时,常会有误解,认为主键的范围查询(GetRange接口)可以针对每一列单独进行,实际上这里的主键范围指的是整体主键的范围,而非单独某一列的范围。
这个模型具有这样的一些优势:
完全水平扩展,因此可支撑的读写并发和数据规模几乎无上限。Tablestore线上也有一些业务在几千万级的tps/qps,以及10PB级的存储量。可以说一般业务达不到这样的上限,实际的上限仅取决于集群目前的机器资源,当业务数据量大量上涨时,只要增加机器资源即可。同时,基于共享存储的架构也很方便的实现了动态负载均衡,不需要数据库层进行副本数据复制。
提供了表模型,相比纯粹的KeyValue数据库而言,具有列和多版本的概念,可以单独对某列进行读写。表模型也是一种比较通用的模型,可以方便与其他系统进行数据模型映射。
表模型中,按照主键有序存储,而非Hash映射,因此支持主键的范围扫描。类似于HashMap与SortedMap的区别,这个模型中为SortedMap。
Schema Free, 即每行可以有不同的属性列,数据列个数也不限制。这很适合存储半结构化的数据,同时业务在运行过程中,也可以进行任意的属性列变更。
支持数据自动过期和多版本。每列都可以存储多个版本的值,每个值会有一个版本号,同时也是一个时间戳,如果设置了数据自动过期,就会按照这个时间戳来判断数据是否过期,后台对过期数据自动清理。
这个模型也有一些劣势:
数据查询依赖主键。可以把这个数据模型理解为SortedMap,大家知道,在SortedMap上只能做点查和顺/逆序扫描,比如以下查询方式:
主键点查:通过已知主键,精确读取表上的一行。
主键范围查:按照顺序从开始主键(StartPrimaryKey)扫描到结束主键(EndPrimaryKey),或者逆序扫描。即对Table进行顺序或逆序遍历,支持指定起始位置和结束位置。
主键前缀范围查:其实等价于主键范围查,这里只是说明,主键前缀的一个范围,其实可以转换成主键的一个范围,在表上进行顺序扫描即可。
针对属性列的查询需要使用Filter,Filter模式在过滤大量数据时效率不高,甚至变成全表扫描。通常来说,数据查询的效率与底层扫描的数据量正相关,而底层扫描的数据量取决于数据分布和结构。数据默认仅按照主键有序存储,那么要按照某一属性列查询,符合条件的数据必然分布于全表的范围内,需要扫描后筛选。全表数据越多,扫描的数据量也就越大,效率也就越低。
那么在实际业务中,主键查询常常不能满足需求,而使用Filter在数据规模大的情况下效率很低,怎么解决这一问题呢?
上面提到,数据查询的效率与底层扫描的数据量正相关,而Filter模式慢在符合条件的数据太分散,必须扫描大量的数据并从中筛选。那么解决这一问题也就有两种思路:
让符合条件的数据不再分散分布:使用全局二级索引,将某列或某几列作为二级索引的主键。相当于通过数据冗余,直接把符合条件的数据预先排在一起,查询时直接精确定位和扫描,效率极高。
**加快筛选的速度: **使用多元索引,多元索引底层提供了倒排索引,BKD-Tree等数据结构。以上面查询某属性列值为例,我们给这一列建立多元索引后,就会给这一列的值建立倒排索引,倒排索引实际上记录了某个值对应的所有主键的集合,即Value -> List, 那么要查询属性列为某个Value的所有记录时,直接通过倒排索引获取所有符合条件的主键,进行读取即可。本质上是加快了从海量数据中筛选数据的效率。
全局二级索引
全局二级索引采用的仍然是表引擎,给主表建立了全局二级索引后,相当于多了一张索引表。这张索引表相当于给主表提供了另外一种排序的方式,即针对查询条件预先设计了一种数据分布,来加快数据查询的效率。索引的使用方式与主表类似,主要的查询方式仍然是上面讲的主键点查,主键范围查,主键前缀范围查。常见的关系型数据库的二级索引也是类似的原理。
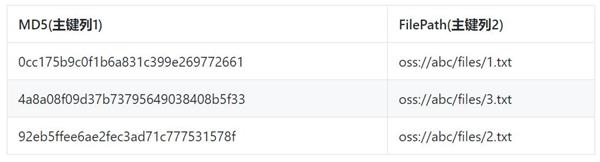
列举一个最简单的例子,比如我们有一张表存储文件的MD5和SHA1值,表结构如下:

通过这张表,我们可以查询文件对应的MD5和SHA1值,但是通过MD5或SHA1反查文件名却不容易。我们可以给这张表建立两张全局二级索引表,表结构分别为:
索引1:
索引2:
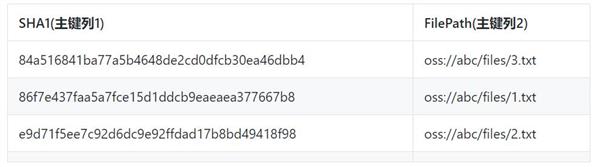
为了确保主键的唯一性,全局二级索引中,会将原主键的主键列也放到主键列中,比如上面的FilePath列。有了上面两张索引表,就可以通过主键前缀范围查的方式里精确定位某个MD5/SHA1对应的文件名了。
多元索引引擎
多元索引引擎相比于表引擎,底层增加了倒排索引,多维空间索引等,支持多条件组合查询、模糊查询、地理空间查询,以及全文索引等,还提供一些统计聚合能力(统计聚合功能待发布)。因为功能较单纯的二级索引更加丰富,而且一个索引就可以满足多种维度的查询,因此命名为多元索引。
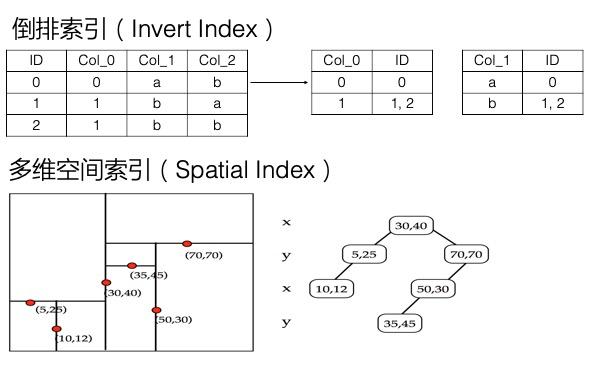
上面在讲解决Filter模式查询慢的问题时,提到倒排索引加快了数据筛选的速度,因为记录了某列的Value到符合条件的行的映射,Value -> List 。实际上,倒排索引这一方式,不仅可以解决单列值的检索问题,也可以解决多条件组合查询的问题。
我们举一个订单场景的例子,比如下表为一个订单记录:

上面一共16个字段,我们希望按照任意多个字段组合查询,比如查询某一售货员、某一产品类型、单价在xx元之上的所有记录。可以想到,这样的排列组合会有非常多种,因此我们不太可能预先将任何一种查询条件的数据放到一起,来加快查询的效率,这需要建立很多的全局二级索引。而如果采用Filter模型,又很可能需要扫描全表,效率不高。折中的方式是,可以先对某个字段建立二级索引,缩小数据范围,再对其中数据进行Filter。那么有没有更好的方式呢?
多元索引可以很好的解决这一问题,而且只需要建立一个多元索引,将所有可能查询的列加入到这个多元索引中即可,加入的顺序也没有要求。多元索引中的每一列默认都会建立倒排,倒排就记录了Value到List的映射。针对多列的多个条件,在每列的倒排表中找到对应的List,这个称为一个倒排链,而筛选符合多个条件的数据即为计算多个倒排链的交并集,这里底层有着大量的优化,可以高效的实现这一操作。因此多元索引在处理多条件组合查询方面效率很高。
此外,多元索引还支持全文索引、模糊查询、地理空间查询等,以地理空间查询为例,多元索引通过底层的BKD-Tree结构,支持高效的查询一个地理多边形内的点,也支持按照地理位置排序、聚合统计等。
索引选择
不是一定需要索引
如果基于主键和主键范围查询的功能已经可以满足业务需求,那么不需要建立索引。
如果对某个范围内进行筛选,范围内数据量不大或者查询频率不高,可以使用Filter,不需要建立索引。
如果是某种复杂查询,执行频率较低,对延迟不敏感,可以考虑通过DLA(数据湖分析)服务访问Tablestore,使用SQL进行查询。
全局二级索引还是多元索引
一个全局二级索引是一个索引表,类似于主表,其提供了另一种数据分布方式,或者认为是另一种主键排序方式。一个索引对应一种查询条件,预先将符合查询条件的数据排列在一起,查询效率很高。索引表可支撑的数据规模与主表相同,另一方面,全局二级索引的主键设计也同样需要考虑散列问题。
一个多元索引是一系列数据结构的组合,其中的每一列都支持建立倒排索引等结构,查询时可以按照其中任意一列进行排序。一个多元索引可以支持多种查询条件,不需要对不同查询条件建立多个多元索引。相比全局二级索引,也支持多条件组合查询、模糊查询、全文索引、地理位置查询等。多元索引本质上是通过各种数据结构加快了数据的筛选过程,功能非常丰富,但在数据按照某种固定顺序读取这种场景上,效率不如全局二级索引。多元索引的查询效率与倒排链长度等因素相关,即查询性能与整个表的全量数据规模有关,在数据规模达到百亿行以上时,建议使用RoutingKey对数据进行分片,查询时也通过指定RoutingKey查询来减少查询涉及到的数据量。简而言之,查询灵活度和数据规模不可兼得。
关于使用多元索引还是全局二级索引,也有另外一篇文章描述:《Tablestore索引功能详解》。
除了全局二级索引之外,后续还会推出本地二级索引(LocalIndex),推出后再进行详细介绍。
常见组合方案
丰富的查询功能当然是业务都希望具备的,但是在数据规模很大的情况下,灵活的查询意味着成本。比如万亿行数据的规模,对于表引擎来说,因为水平扩展能力很强,成本也很低,问题不大,但是建立多元索引,费用就会非常高昂。全局二级索引成本较低,但是只适合固定维度的查询。
常见的超大规模数据,都带有一些时间属性,比如大量设备产生的数据(监控数据),或者人产生的数据(消息、行为数据等),这类数据非常适合采用Tablestore存储。对这类数据建立索引,会有一些组合方案:
对元数据表建立多元索引,全量数据表不建立索引或采用全局二级索引。
元数据表可以是产生数据的主体表,比如设备信息表,用户信息表等。在时序模型中,产生数据的主体也可以认为是一个时间线,这条线会不断的产生新的点。
Tablestore的时序数据模型(Timestream)采用的也是类似的方式,对时序数据中的时间线建立一张表,专门用来记录时间线的元数据,每个时间线一行。时间线表建立多元索引,用来做时间线检索,而全量数据则不建立索引。在检索到时间线后,对某个时间线下的数据进行范围扫描,来读取这个时间线的数据。
热数据建立多元索引,老数据不建立索引或者采用全局二级索引:
很多情况下仅需要对非常热的数据进行多种维度查询,对冷数据采取固定维度查询即可。因此冷热分离可以给业务提供更高的性价比。
目前多元索引还不支持TTL(后续会支持),需要业务层区分热数据和冷数据。
总结
本文对Tablestore的存储和索引引擎进行了介绍和解读,并在如何选择和应用索引方面给了一些参考,目的是加深大家对Tablestore的认识和理解,更好的应用Tablestore来解决业务需求。
