摘要
为推动“人工智能+交通运输”在政务和科技领域的应用落地,交通运输部科学研究院依托长期深耕交通行业科技信息资源和政务信息资源的深厚积淀,联合中电数据产业集团有限公司对公路、水运等重点领域超万项政策法规和标准规范进行了智能标注和深度加工,建成“交科智汇•交通政策法规与标准规范高质量数据集”。该数据集由约15万对的文本问答对组成,涵盖交通运输领域及其相关的法律法规、政策规章及标准,可作为行业政务大模型、科技大模型以及细分子领域模型的训练集和测试集,还可与其他领域或模态数据融合,应用于工程建设、运输管理等场景。该数据集已在第八届数字中国建设峰会上发布,并成功申报北京市政务服务和数据管理局“行业高质量数据集建设成果”。
一、实施背景
交通运输政策法规和标准规范是行业政务信息和科技信息的重要组成部分。高质量的政策法规和标准规范数据集,对于带动人工智能赋能交通运输,提升交通运输信息化服务和科技创新自主化水平具有重要意义。目前,交通运输政策法规与标准规范主要通过政府网站的政府信息公开和行业标准化管理平台发布,存在着全文检索信息过载、标准精准检索需专业背景、政策附件和标准全文需下载后阅读等智能化服务水平不高的问题。本实证研究通过合规采集交通运输领域政策、法规和标准数据,建成“交科智汇•交通政策法规与标准规范数据集”,可用于行业政务或科技大模型以及公路、水路等细分子领域模型的微调训练。同时,基于该数据集还可精选数据样本建立评测数据集,用于评价交通运输细分领域或方向的政策法规与标准问答类模型/场景的泛化能力和理解指令要求的能力。该数据集的主要应用场景包括:
(一)政策法规咨询:交通运输政策法规数据关联地理编码(如行政区划代码),构建“国家-省-市”三级政策法规知识图谱,开发或训练智能检索、精准解读、政策推荐、流程导航、地区政策对比等应用场景,实现国家级法律、部委规章、地方性法规的垂直检索,以及地方政策差异分析,提升政务信息服务水平。
(二)标准管理:应用交通运输标准规范数据,开发或训练标准检索、查重、辅助编写、修订分析、格式审查等应用场景,实现标准自然语言检索、文本相似度分析、编制内容纠错及推荐、修订建议归类及关键问题提取、章条体例结构对比审查等功能,辅助行业标准化工作全链条智能管理。
(三)工程设计审查:交通运输标准数据结合工程设计施工数据,开发或训练交通基础设施工程合规性审查应用场景,检测设计施工指标是否符合标准要求。
二、实施目标
(一)整合政策法规与标准数据资源。较全面地收集交通运输领域以及与交通运输行业相关的法律、行政法规、部颁规章、行政规范性文件、地方性法规、国家标准及行业标准等数据资源。
(二)建设高质量交通政策法规与标准规范数据集。通过文本加工大模型自动生成文本问题、评估问题质量、生成问题答案、将问答对组装,形成了高质量数据集。
(三)开展数据集在行业垂直模型中的应用探索。建成数据集用于行业垂直模型的监督微调训练以及知识库构建,提升模型在政策法规与标准领域智能问答的准确率。
三、建设内容
(一)数据采集
为较全面地整合交通运输政策法规与标准数据资源,该数据集选取官方网站和馆藏资源作为数据源,主要为交通运输部政府网站、交通运输法规查询系统,以及图书馆馆藏资源。相应的数据采集内容如表1。

表1数据集采集范围
数据采集采用人工方式,政策法规数据通过访问系统/网站页面,手动采集题录及全文数据;标准数据通过OCR技术进行数字化加工,将印本制作成数字化文件,并手工录入题录信息。以上共采集1644条法规、13667条政策和1657条标准文本数据。采集数据的质量经过人工质检。
为便于数据集建成后在不同领域的应用,除按照政策法规效力、标准适用范围划分外,对采集数据进行专业领域分类。其中,政策法规数据按照业务领域分别划分为17类和21类;标准数据按照标委会标准体系划分为19类。
(二)数据标注
该数据集利用中电数据产业集团有限公司的语料库系统进行标注,主要加工流程如下:
1.预处理
采用语义切分模型对原始文本进行切分,结合上下文对不同的内容切分的颗粒度及语义进行调整,从而更准确地保留文本中完整的语义信息。同时,利用大语言模型,从文本数据中提取关键信息,生成关键词对和摘要。
2.问题生成
基于关键词对和摘要,通过指令引导知识库调用适用于本数据集建设的数据加工Prompts,引导大语言模型生成问题数据。
3.答案生成
将问题数据再次输入大语言模型,运用大语言模型的知识储备和推理能力,结合问题所在的原文内容、业务需求和行业知识,生成详尽的答案数据。
(三)产品化封装
将答案数据与对应的问题数据组合,保留高质量的问答对数据。通过上述流程建成约15万对文本问答对的交通政策法规与标准规范数据集,数据集规模如表2,数据集以JSON/JSONL格式存储,包含编号、输入、输出、分类、来源等字段。

表2数据集规模
(四)质量评估
在上述数据标注过程中,先后进行两次质量评估。一是在问题生成后,对大语言模型进行微调形成评估模型。评估模型具有增强的数据质量评测能力,能够筛选出优质可用的问题数据。评估内容包括:是否有语病;问题是否有意义(如无意义问题:王建国的中文名是什么?);指代是否明确(如发展目标是什么?没有提到发展目标);与人类提问是否相似等。二是在产品化封装环节,再次利用评估模型对问答对数据进行质量评估,评估内容分为数据元素质量、数据分布质量、数据安全质量等维度,主要评测内容信息量(语料、问答对中信息丰富度)、领域相关性(数据内容是否与行业知识相关)、样本唯一性(问答对去重)、形式规范性(命名不规范、特殊符号等)、安全性(数据无毒性、不包含个人信息等)等。
四、实施效果
该数据集建成后,积极开展了数据集应用推广工作,主要成效包括:
(一)提升交科大模型在政策法规与标准领域智能问答的准确性。
交科大模型是由交科院联合中国电信、中国电子数据产业集团、同方知网、辰安科技、久其软件、智慧互通等行业领军企业建设的领域专业化垂直模型,提供面向交通运输战略研究、技术攻关、产品研发、成果转化、标准化管理、行政管理决策等场景的全流程智能化服务。“交科智汇•交通政策法规与标准规范高质量数据集”建成后,其问答对通过向量化技术用于构建智能检索、精准解读、政策推荐等应用场景的知识库,实现对交通政策法规与标准的精准语义理解与智能问答。
(二)宣传行业高质量数据集建设成果
该数据集建成后于第八届数字中国建设峰会上发布,同时成功申报了北京市政务服务和数据管理局“行业高质量数据集建设成果”,并在2025全球数字经济大会上发布。
(三)推动行业高质量数据集流通交易
为推动高质量数据集流通交易,依托建成的“交科智汇•交通政策法规与标准规范高质量数据集”开展数据产品上架交易探索,完成深圳数据交易所商品展示区上架和北京国际大数据交易所数据产品上架,获得深圳数据交易所数据商证书。
(四)分享行业高质量数据集建设经验
为分享高质量数据集建设经验,该数据集作为典型案例参与了中国信息通信研究院《人工智能高质量数据集建设指南》《交通行业高质量数据集建设指南》的编写工作。两项成果分别在2025全球数字经济大会和2025数据要素发展大会上发布。
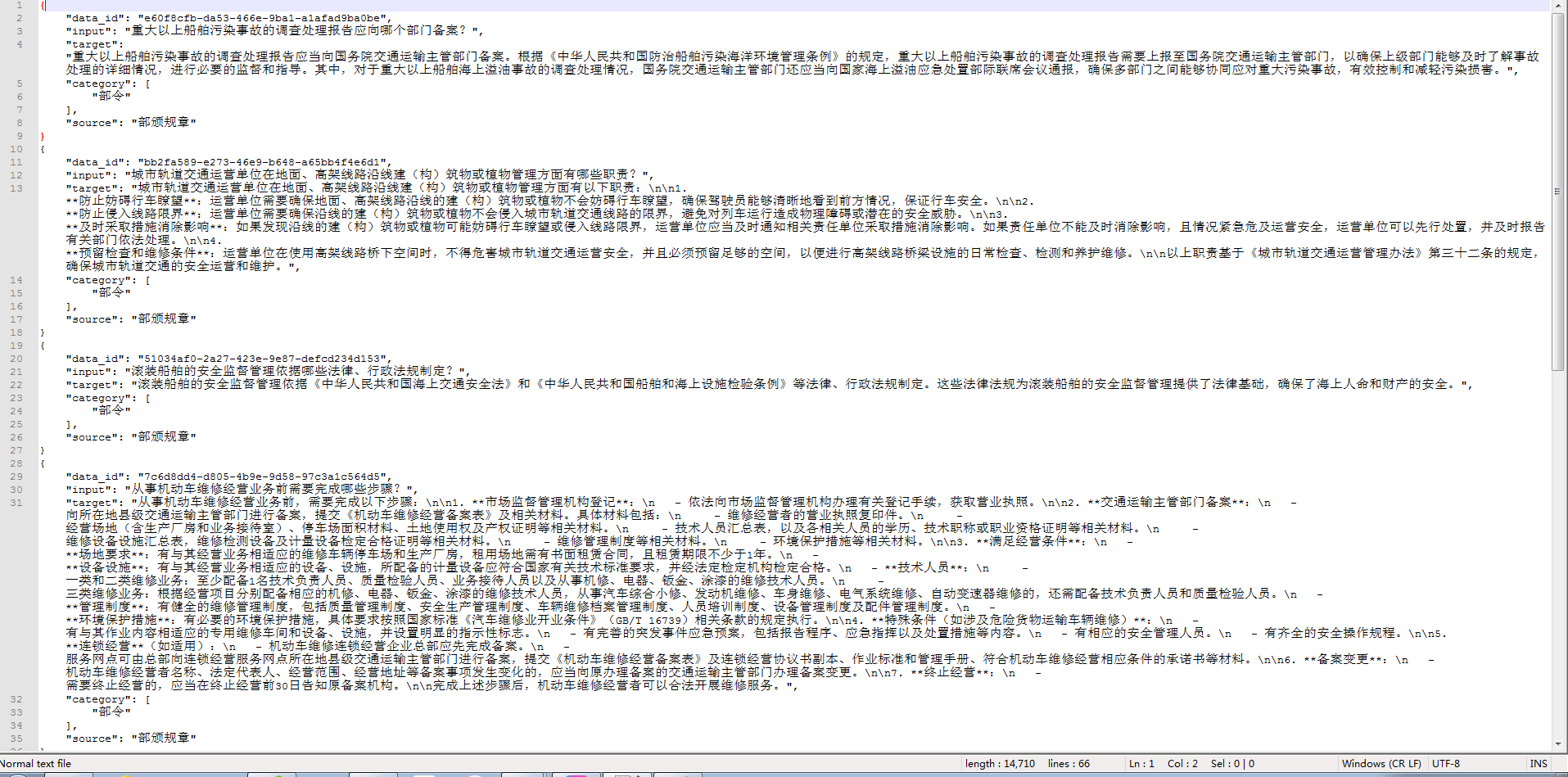
“交科智汇•交通政策法规与标准规范高质量数据集”样例

“交科智汇•交通政策法规与标准规范高质量数据集”在第八届数字中国建设峰会上发布
完成单位:交通运输部科学研究院
完成人:黄莉莉、林垚