近日,由清华-伯克利深圳学院(TBSI)与 华扬联众 联合主办的“2019数据科学研究与商业应用国际研讨会”在清华大学深圳国际研究生院隆重举行,华扬联众研发副总裁李响博士受邀担任研讨会主席,并以《具有用户隐私意识的机器学习框架》为题发表演讲,就用户数据隐私,大数据机器学习等当下热门话题展开讨论。

华扬联众研发副总裁李响博士
当下大数据的特征
李响博士在演讲中表示,现如今互联网技术不断发展,数据的收集与传输速度也在不断提升;与此同时各种网站、APP如雨后春笋般涌现,它们的分类愈发细化,并在运营中不断产生大量数据,因此当下的大数据领域正呈现出:数量大、速度快、多样性等特征。
大数据带来的责任
数据科学的不断发展为人们生活提供的便利不可忽视,但由于互联网的开放性,数据库中累积的数据会不断与不同的服务器、运营商进行连接与交换,这也势必会带来信息泄露的风险。近来大型用户数据泄露事件层出不穷,消费者对互联网数据安全的信任度跌至低谷,针对这一现状,我们确实需要思考如何在数据交换的过程中保障用户隐私,提升公众对数据科学的信任度与安全感。
保障用户的数据隐私
在法律层面,不同的国家及地区正在做出各自的尝试——在欧洲,通过设立GDPR(General Data Protection Regulation)个人隐私保护法,以较为苛刻的条款严格保护用户的数据信息,但这种严格的规定客观上也一定程度地导致了欧洲地区在数据科学领域发展的相对滞后;美国的做法则相对宽松,他们提出的D4GX(Data For Good Exchange)更倾向于规范数据的使用和管理,以及保证用户的知情权。
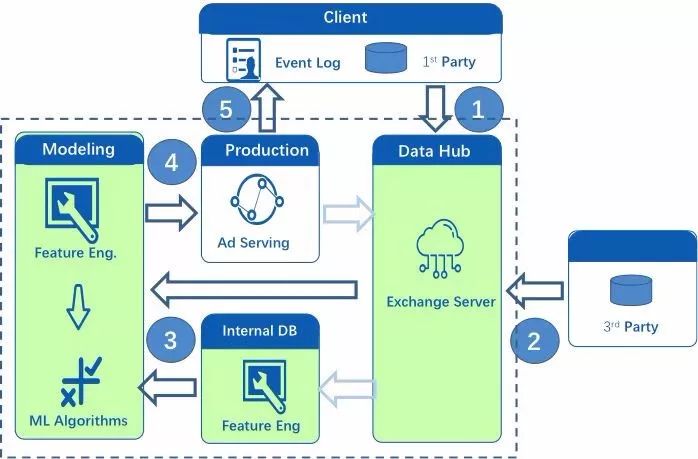
除了完善的法律制度外,技术领域近年来也出现了很多的工具和方法——数据加密(data encryption)、数据匿名化(data anonymization)、微分隐私(differential privacy)等,帮助解决数据挖掘和应用过程中对个人隐私的保护问题。华扬联众在数据开发和使用过程中,也在不断为保护个人信息安全做出新的尝试,探索出一套基于用户隐私保护的机器学习流程和框架——从数据的键值和标签分别着手,综合运用数据加密技术,对数据清洗、加工和流转各个环节中的个人数据信息进行保护,并且通过数据匿名化技术,限制了数据信息的应用范围,避免了一直困扰业界的未经授权数据二次使用问题。在演讲中,李响博士也通过具体实例,展示了如何在保护用户数据隐私的同时,保证机器学习模型的性能、实现数据隐私和应用效果的平衡。
最后,李响博士表示当下一些数据使用失当的行为使大众对数据科学的信任度大幅度降低,保护用户隐私安全是未来大数据领域研究的重点;在技术升级、完善的同时,我们也要通过数据科学的普及教育,提升大众在这一领域的认知,使消费者们相信合理规范的数据挖掘、使用行为,完全可以实现用户隐私保护和提供生活便利之间的平衡。
李响博士自2016年加入华扬联众,负责华扬联众数字营销平台的规划和研发,致力于利用数据科技的手段提升华扬联众的营销服务水平和产品竞争力;同时他也带领华扬联众HDTC团队整合华扬联众核心数据与技术资源,开发出HY-MADE(华扬联众营销数据分析引擎)、GRAPHy(华扬联众图分析综合数据服务平台),为客户与合作方带来更高效、更具竞争优势的数字营销,实现“数据思维创造的行动力”。
