
电源故障是导致数据中心运行中断的常见原因,但它们并不是唯一的罪魁祸首。随着企业计算环境变得越来越复杂,IT系统和网络故障正在导致越来越多的数据中心宕机。
数据中心设施咨询机构Uptime Institute的主要业务为提供弹性服务,为建立和运行数据中心提供建议以及认证服务。该公司一直在研究公开发表的宕机报道,以追踪导致意外停机的原因。过去三年中,他们已经从传统媒体或社交媒体上报道出来的162次宕机报告中筛选出了一些信息。可用的数据在这三年内不断增加,研究人员收集到了2016年27次宕机、2017年57次宕机以及2018年78次宕机的数据。
Uptime Institute的研究执行董事AndyLawrence表示:“曝光出来的宕机事故成为新闻的次数正变得越来越多。”
在研究结果公布的同时,Lawrence指出,目前他们正记录着全球每天发生的几乎所有的重大运行中断事件。虽然这并不一定意味着运行中断的次数在急剧增加,但是宕机时间正在受到越来越多的关注。“我们很清楚,运行中断产生的影响肯定会增加。”
Uptime Institute的一个重要研究发现是,电源在整个故障中影响较小,但网络和IT系统的影响则较为深远。导致变化的一个原因是电力系统比过去更加可靠,这减少了本地数据中心发生电力故障的次数。
技术行业在过去二十年中一直专注于如何设计电力系统,即使电力系统某处出现故障或整个系统发生故障,IT资产也能继续运行。Uptime Institute首席技术官Chris Brown称:“供应双线IT设备的2N配电系统的出现使得IT系统能够在经历一系列独立事件和事故后仍能继续保持运行。”

同时,日益复杂的IT环境导致了更多的IT和网络问题。Uptime Institute负责IT优化和战略的副总裁Todd Traver称:“数据现在分布在多个地方,这些数据极为依赖网络。应用程序的构建以及数据库的复制同样也非常依赖网络。这是一个非常复杂的系统。”
对数据中心运行中断的严重性的评估
为了区分可能导致业务崩溃的运行中断和仅仅造成不便的运行中断,Uptime Institute对此进行了分级。该评级系统可让研究人员了解运行中断的整体情况是如何随时间而变化的。Uptime Institute的评估分为五个等级:
●1级为可忽略不计的中断。该级别的中断会被记录下来,但是对服务的影响很小或没有明显影响,也没有出现服务中断。
●2级的特点为最低程度的服务中断。服务出现中断,但对用户、客户或声誉的影响微乎其微。
●3级为重要业务发生服务中断,涉及客户或用户服务,主要特点是范围、持续时间或影响有限。对财务的影响轻微甚至没有,但是会产生一些声誉或合规方面的影响。
●4级为严重的业务或服务中断,涉及服务和/或操作。波及面包括财务损失、数据泄露、声誉损害并可能出现安全问题。可能会导致客户损失。
●5级为关键业务或任务出现中断,包括服务和/或运营出现重大和破坏性中断。可能会造成重大财务损失、安全问题、数据泄露、客户损失和名誉损失。
在分析了三年内所有公开的数据中心运行中断(级别1到5)事件后,Uptime Institute发现IT系统和网络问题已经超过了电源成为了主要原因(见图)。
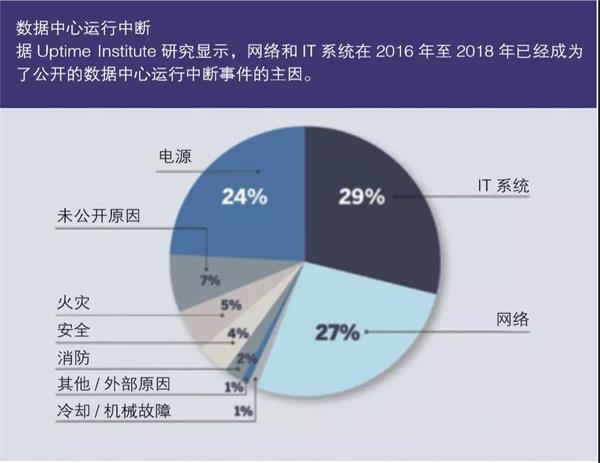
在逐年对原因进行比较后,这种趋势会显得尤为突出。2017年,电力是28%运行中断事件的罪魁祸首。次年,仅有11%的运行中断事件的主因为停电。与IT系统有关的故障则在这两年中基本保持一致。其中,2017年32%的运行中断事件的主因为系统故障,2018年这一比例为35%。网络作为运行中断的主要原因在显着增长。其中,2017年19%的运行中断事件被归咎于网络,2018年这一比例飙升到了32%。
Traver在谈到2018年运行中断事件数量大幅增长时指出,“这些事情之间的确是相互联系的。这也就是为什么网络中断的大幅上升会导致运行中断的原因所在。这些东西不是连接在一个或两个站点上,而是连接在三个、四个站点,甚至更多的站点上。如今,网络在IT弹性方面正发挥着越来越大的作用。
此外,随着更多IT资源被移交给服务提供商,并且不再受使用它们的企业的直接控制,管理和操作也变得越来越复杂。Traver称:“在2018年,三分之二的运行中断事件与网络和IT有关。这是在过去几年中出现的一个重大变化。”
深入研究数据中心的宕机时间
Uptime Institute对导致数据中心运行中断的具体原因进行了深入的研究。在网络方面,导致运行中断的常见原因包括:
● 连接数据中心的外部光纤被切断,并且未充分选择备份路由。
● 主要交换机间歇性故障,且未部署次要路由器。
● 主要交换机故障且没有备份。
● 维护期间未正确配置流量。
● 路由器和软件定义的网络未正确配置。
● 无备用的单个组件(如交换机和路由器)发生断电。
Traver指出,“错误配置的路由器和软件定义的网络是常见的网络问题。这一问题应当可通过测试被检测出来。”
当谈到光纤被切断问题时,Traver说,企业此时往往没有意识到他们发生了单点故障。“企业可能有两个独立的服务提供商,但他们不知道,两个提供商的光纤埋在同一个沟渠中。同时,企业也没有对这一问题展开恰当的尽职调查。”
当IT为罪魁祸首时,造成运行中断的主要原因如下:
● 对升级工作管理不善,对软件级别测试不充分。
● 大型磁盘驱动器或存储区域网络发生故障并出现数据损坏。这可能是由硬件故障引起的,配置或编程错误让问题雪上加霜。
● 负载平衡或流量管理系统中发生同步故障或程序错误。
● 未能对故障/同步或灾难恢复系统进行正确的编程。
● 无备用的单个组件(如服务器或大型磁盘驱动器)发生断电。
谈到负载均衡/流量管理问题,Lawrence表示,在企业尝试将IT资源部署的更为分散时,可能会出现程序错误和同步问题。Lawrence说:“减少对单一站点的依赖性通常是企业战略的一部分,但是它们就像挤压气球一样,问题突然出现在其他地方。”
Traver补充道,如果企业没有认真规划他们在所有平台上的应用程序和数据,或是没有展开经常性测试,那么这些问题就会发生。

当电源是罪魁祸首时,导致运行中断的一些主要原因包括:
● 雷击导致出现电涌和断电。备份软件/配置失败。
● 转换开关出现间歇性故障,导致无法启动发电机,或转移到第二个数据中心。
● UPS故障和无法转移到辅助系统。
● 操作错误,关闭或未正确配置电源。
● 公用电力断电,随后发生发电机或UPS故障。
● 电涌导致IT设备损坏。
● IT设备未配备两种互为备份的电源供给方式。
Brown称,在以电源问题为主因的运行中断事件中,所有具体原因大家都非常熟悉。“这些都是数据中心的工程师们几十年来一直在努力解决的问题,即如何围绕这些问题进行设计,以及如何利用他们的设计缓解这些问题。”
Traver表示,总的来说,企业需要更加关注数据中心的弹性。他说:“要知道自己的系统是如何设计的,充分理解各部分之间的关联性。同时还要知道故障是如何发生的,以及故障发生后的应急预案。而我认为这一块是缺失的。”
Lawrence总结道,“如今设备正越来越好,管理越来越出色,经验也越来越丰富。整个行业正变得越来越成熟。但即便如此,运行中断仍将是一个非常重要和代价高昂的问题。”
作者:Ann Bednarz,主要负责为《网络世界》采访报道IT职业、外包和互联网文化方面的新闻。
编译:陈琳华
原文网址:https://www.networkworld.com/article/3373646/network-problems-responsible-for-more-data-center-outages.html
