
3月12日,中国传媒大学信息工程学院副教授王鑫在CIO时代APP微讲座栏目作了题为《广播电视个性化节目推荐系统》的主题分享,具体从广播电视大数据的由来、广播电视大数据决策知识系统及个性化节目推荐系统三部分进行介绍。
一、广播电视大数据的由来
传统广播电视收视率调查方法采用抽样调查的方法,其中包括日记卡和测量仪两种,日记卡数据采集的方式为对4岁以上的人员,人工填写,每周进行回收;记录时间以15分钟为记录单位;数据提供的速度是15个工作日,人工进行采集。因此,对于一张记录卡,一人一周的数据采用基于回忆的方法进行数据统计。测量仪则不同,它是采用遥控器特殊操作、仪器调查,以1秒钟为测量单位,24小时为一个统计周期,凌晨固定时间回传,但遥控器家庭成员键配合度低不能实时对数据进行采集。
根据统计学理论,样本数据要达到1067个以上,允许的误差才能达到3%以下。另外,广播电视对于测量的样本有一定的要求,需要家庭常驻半年以上,周居住超过5天的,且家里有电视、经常收看电视节目的人群。
1.传统收视率调查方法存在的问题
1)抽样误差
以央视-索福瑞(CSM)为例:全国650个城市,总样本户<5万户,平均每城市不足百户,只有北、上、广等少数城市的样本户达到500个。
2)样本户污染
样本“污染”难以避免。样本户相对固定,隐蔽性差;且日记法、测量仪要求受众参与性强,可以被“收买”。
3)代表性
样本更换及跟踪难度大,要求人员固定,只能是常驻特定居民。
4)数据单一
受制于采集手段,往往只有直播数据,缺乏常见的时移、回看。
5)只支持传统指标
6)时效性差;遇到特殊情况,需要人工修改数据
7)样本户维护成本越来越高
2.电视大数据采集的要求
1)用户行为数据
谁在什么时间看了什么频道、节目、页面
2)用户特征信息
用户是什么人(地区、年龄、性别、职业、学历、收入)
3)媒体资源信息
什么渠道、在什么时间播了什么类型的节目
4)用户消费信息
谁购买了什么服务
5)服务端业务信息
谁在什么时间使用了什么服务
6)终端采集
覆盖三网、多屏;全网数据采集
3.电视大数据分析的要求
不仅需要常规的直播数据,还需包括点播、时移回看、广告业务及其他增值业务等数据。
1)直播
收视时长、收视率、到达率、接触度、市场份额、观众忠诚度等。
创新指标:节目相对吸引力、收视率分布等。
2)点播
VOD业务使用及VOD节目指标。
各时段在线户数、在线率;到达户数、到达率、点播户数、点播率、收看时长、页面点击等。
创新的竞争力指标:时间转化率、点击转化率。
按栏目、按供应商分别分析。
3)时移、回看
业务各时段在线户数、在线率、页面点击率等。
各频道及节目的收视时长、收视率、到达户数、到达率、市场份额等。
4)广告业务
按各广告位、广告包进行指标分析。
各广告位曝光频次、n+曝光率、n+到达户数、有效曝光率、有效到达户数等。
5)其它增值业务
业务各时段在线户数、在线率、页面点击率等。
其它定制指标分析。
4.广播电视大数据的特点
1)数据准确、分析计算误差小;公正、抗污染、不易造假
全网海量用户收视数据分析,全方位、无死角,尤其对弱势频道、非黄金时段节目的数据分析更准确,使其数据有意义,更能反映实际情况;
全网双向用户可达千万以上,用户污染影响微乎其微;
2)指标更有价值
例如忠诚度、竞争力指标等,对低收视率的频道和节目,能提供更多参考依据;
3)能提供舆情分析
根据全网用户的收视行为,结合节目播出信息,可以分析舆情;
涉及舆情及国家信息安全,不建议外资公司参与;
4)能了解每一个用户的偏好,提供个性化服务
5)技术难度大
采用传统手段采集海量用户收视数据,成本太高;
采用终端数据回传,需要掌握嵌入式设备、计算机、网络相关的关键技术;
全网收视数据是海量数据(以歌华为例,420万用户每天>2亿条),传统的数据库技术无法支撑,需掌握大数据处理系统的架构、算法、专业工具等核心技术;
二、广播电视大数据决策知识系统架构
1.系统邮件部署的方式
系统硬件部署采取分级的方式,包括数据采集系统、数据传输存储系统及数据分析挖掘系统。
第一级进行数据采集,通过双向网络采集双向机顶盒数据汇集至边际站点;
第二级进行数据传输、存储。汇总边际站点的收视数据、以及用户特征信息和节目信息及分类数据形成收视数据库,同时汇总VOD、时移等业务数据、BOSS等经营数据。
第三级进行数据挖掘分析。将汇总的各类数据回传至数据分析中心进行数据挖掘,将得到的分析结果以PC机、iPad、手机等终端形式呈现。
2.广播电视大数据决策知识系统的体系结构
由此可以看出,广播电视大数据决策知识系统包含了不同的体系结构:
终端层采集数据源包括:标清机顶盒、高清机顶盒和智能电视
数据采集层采集数据包括:直播数据采集、点播数据采集、回看数据采集、时移数据采集、广告数据采集、卡拉OK数据采集等。
数据存储层通过管理控制层和数据服务层对数据进行综合综合传输和存储。
数据分析曾是软件系统架构的核心部分:包含实时数据分析和非实时数据分析两大部分。
3.广播电视大数据采集技术
广播电视大数据采集技术采用了Hadoop的部署方案,采集服务器将终端机顶盒采集得到的数据回传至中心服务器,并交由不同的服务器分别实现实时分析和Web展现等功能。
4.广播电视大数据存储技术
在大数据存储计算方面:充分发挥了Hadoop集群的优势,采用MapReduce的分布式计算系统。
5.广播电视大数据分析挖掘技术
广播电视大数据分析挖掘技术中,采用了SaaS、R、Python、Spss等不同的工具,建立的模型包含了支持向量机、决策树、贝叶斯、神经网络等多种不同的算法。
6.广播电视大数据分析的常规案例
1)节目基因标签标注
打破了传统的广播电视节目分类体系及“知识树”的结构,采用了扁平化的平行关系,通过从互联网采集节目的标签数据,加上广播节目的标签信息,采用扁平化的标签对节目进行标注。
2)用户肖像刻画
基于节目标签,定义用户兴趣度;基于节目类型,分析单个用户对哪类节目最感兴趣。
3)用户分群技术
将用户分群,描述为无收视、低偏好、中偏好、高偏好几类;分析群体偏好,精确至下面的小类。
三、广播电视个性化节目推荐系统
高度信息化的社会每天都会产生海量信息,如何从海量信息中找到用户所喜爱的节目,为用户进行个性化服务常常困扰着用户。目前互联网各大视频网站纷纷推出个性化节目推荐系统,但广播电视领域还处于一片空白。为此,基于大数据提供广播电视个性化节目推荐系统,为用户提供个性化服务。
在陕西省网中收集到40多万双向用户,每天凌晨将前一天的用户的收视数据上传到北京的机房。在北京,北京歌华有线电视网络股份有限公司目前采集到420多万双向用户数据。
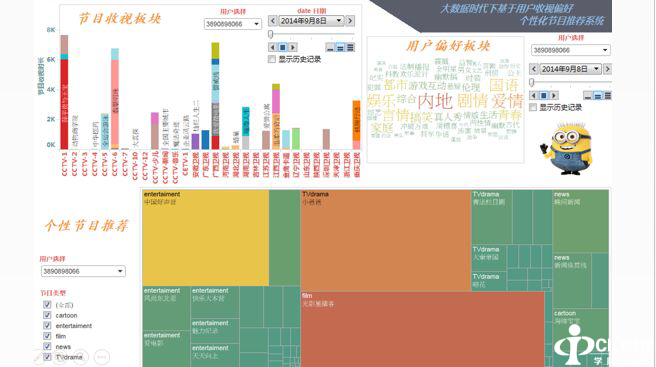
以上图为例,左边是节目收视板块,可以看到不同用户在不同收视日期内看到的不同节目,而不同的节目具有不同的节目特征,在右边的用户偏好板块中,将用户的节目类型进行偏好,可看到用户所喜爱的不同节目类别,当定义到某个用户时,可以看到该用户的节目偏好情况。针对用户的不同偏好提供不同的个性化服务。
本套系统初期选取陕西省网2万家庭用户作为本项目的试点用户,对其免费提供个性化节目推荐服务;未来,将对本套系统进行进一步扩展,扩大用户规模,向陕西40万用户和北京420万用户全面推放本系统,拥有广泛的发展前景。
个性化节目推荐系统面向广播电视各类人群,在为各类人群提供不同服务时,可产生各类回报。对广告商而言,在为用户提供个性化推荐的同时,可精准定位用户偏好,进行广告精准投放;广告收益是本项目的主要收入,节目制作商关心何种节目受欢迎,电视台关心频道收视率如何,从他们那里收取的信息服务费是本项目的增值收入;网络运营商关心VOD价值如何以及潜在使用增值业务的是,个性化节目推荐系统可以完全满足用户的需求,视频点播收入是本项目的另一创收点。另外,本项目弥补了广播电视领域的技术空白,政府职能部门予以一定的支持。
中国传媒大学理工学部,旗下成立了大数据分析挖掘研究院。作为其中的负责人,承担了很多课题,包括广播电视个性化节目推荐系统、广播电视舆情分析系统及未来将进行的电影影视大数据分析系统。愿各位老师加强合作。
