NewSQL技术近几年发展十分迅猛,国内外都有了较成熟的系统。在业界一些开源系统的实现中,Rocksdb起到了核心的存储和查询功能。其中的一个核心设计需求,就是把结构化的表数据以及索引数据转换为kv数据存储到Rocksdb中。本文就该需求的设计方案进行了介绍,以供大家参考。
我们知道Rocksdb是一个kv形式的存储引擎,就像一个有序的大map,map的key,value都是字节数组,其排序顺序就由key这个二进制字节数组决定。Rocksdb除了提供随机读写kv的接口,还提供了创建一个迭代器,从大于等于某个key开始的位置向下扫描数据的接口。
利用上述两种接口,结合设计良好的数据存储格式,Rocksdb就可以作为结构化数据存储和查询的引擎。
比如我们有如下数据表结构:

一、构造主键索引
首先为每一行记录生成一条kv数据,k是temp表id字段,value是其他几个字段序列化后的二进制字节数组。序列化协议可以自定义,也可以使用protobuf协议。
因为id字段是主键索引,当查询条件是 where id = 101 或者where id in ( 101,105,108)的时候,可以根据Rocksdb的get或者mget接口,高效的获取某一条和某几条数据。
当查询条件是 where id > -100 and id < 200 这样的range查询的时候,我们可以创建一个迭代器,指向第一个大于等于-100的记录,然后向下扫描至200的记录。这个操作需要一个seek随机读和一个scan顺序读操作,也有很高的读取性能。
要支持上述的range查询,需要保证表数据在Rocksdb中,按照id字段的字节序递增存储。
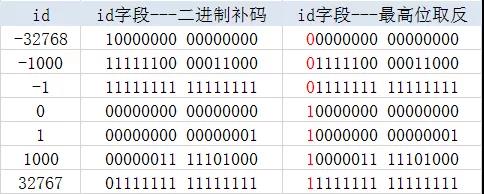
如果直接将id字段的二进制位作为key存储到Rocksdb中呢?我们知道整数在计算机中时按照补码进行存储,正数最高位是0,负数最高位是1,直接存储就会造成负数存储在正数的下面,造成逻辑顺序不一致的现象。
因此只要把非负数的最高位变成1,负数的最高位变成0,就可以保证key的二进制顺序和其代表的整数的数值顺序是一致的。如下图:
就有了下面的转换函数:

主键索引采用大端法进行存储,下面介绍的各个索引也都采用大端法存储。
二、构造整数字段索引
构造完了主键字段,接下来看第一个索引 KEY `i_index` (`i`)。首先这是一个非唯一索引,因此Rocksdb的key字段,必须同时包含i字段和主键id字段,Rocksdb的value为空即可。
key的格式可以是2字节的i字段和2字节的id字段。i字段和id字段仍然按照上述的最高位取反原则进行处理。这样可以保证i_index先按照i字段排序,i字段相同的记录再按照id字段排序。
在查询 where i = 100 或者where i > -100 and i < 200的时候,都可以转换为Rocksdb的迭代器seek加scan操作。在获取了满足条件的主键id集合之后,可以从主键索引数据中,通过mget操作获取id集合的完整数据。
如果i_index是一个唯一性索引,Rocksdb的key字段只需要包含 i字段即可,value字段存储id字段。
三、构造浮点数字段索引
接下来看第二个索引KEY `f_index` (`f`) 。首先这个也是非唯一索引,构造的key中也需要包含f 字段和id字段。id字段仍然采用最高位取反的逻辑。对于f字段,因为其是一个浮点数,首先了解一下浮点数的存储格式。
我们知道浮点数的二进制格式跟整数是不同的。比如float类型,由1个bit的符号位,8个bit的指数部分,23个bit的尾数部分组成。
回顾一下 var f float =10.75 的二进制位是怎么存储的呢?
把十进制小数转换成为二进制小数,整数部分10转换成二进制得到 1010,小数部分0.75转换成二进制得到0.11, 所以10.75的二进制小数表示为1010.11;
对其做规格化处理,小数点向左移动3位,得到1.01011 * 2的3次方;
于是,8bit的指数部分由指数值3+127=130得到,130的二进制位是10000010(加127是固有的换算逻辑);
23bit的尾数部分:因为二进制小数规格化处理之后(1.01011),小数点之前总是1,因此只存储小数点之后的01011五个bit;
最高位是符号位:正数为0;
最终的二进制表示为:0 10000010 01011000000000000000000,16进制表示0x412c0000。
如果浮点数是-10.75呢,只是把最高位变成1即可。其16进制表示:0xc12c0000。
简单验证一下结果:

我们发现绝对值相同的两个浮点数,只是最高位符号位的不同而已,其余各个bit都相同。
继续分析浮点数的二进制位。由于对二进制小数做了规格化,都变成了1.xxx * 2的n次方这种格式。
在8bit指数部分相同的情况下,23bit尾数越大,其浮点数值越大。例如 1.01011 *2的3次方 (十进制10.75) 大于 1.01001*2的3次方(十进制10.25), 其二进制表示也恰好满足字节序的大于关系。
8bit指数部分二进制位越大的浮点数其值也越大。例如 1.000*2的3次方 (十进制8.0) 大于所有的1.xxx*2的2次方数。
有了上述两个规律:我们就能知道浮点数>0的情况,其二进制顺序就能代表其数值顺序。小于0的浮点数仅仅是最高符号位为1,其余各位跟其绝对值小数相同。
于是我们采用如下规则:
大于等于0的浮点数,最高位设为1。小于0的浮点数,其最高位设置为0。这条可以保证:负数的二进制字节序都小于正数的字节序,正数的字节序满足字节序跟数值顺序一致。
负数的最高位设置为0以后,对其它位进行取反。
因为负数的字节序列是原码表示,对原码进行取反即可保证字节序和数值序一致。
得到最终的转换函数:

因此,第二个索引KEY `f_index` (`f`) ,其写入Rocksdb的key格式,可以是4字节经过浮点处理的f字段和2字节的经过整数处理的id字段,value为空。
四、构造字符串字段索引
接下来看第三个索引 KEY `c_index` (`c`) ,也是非唯一性索引,所以key中必须包含字符串c 和id字段,value为空即可。
由于c字段是不定长的字符串,id字段直接放在其后会导致排序字段错乱。
比如下面两条索引数据:

可以看到,第一条索引的id=1006,其二进制由两个字节组成,会参与跟第二条索引的 de两个字符构成的二进制位的比较。1006的二进制最高位取反后大于de两个字符的二进制位,就会导致排序顺序不正确。而且字符串本身也需要一个长度字段,也会影响到整体的排序正确性。
Facebook利用Rocksdb,为mysql实现了一版存储引擎,其中创建字符串索引部分采用了以下算法。(该算法在tidb中也得到了应用)
首先将字符串按照8字节为一组,分成若干组,group_num= len(str)/8 + 1。
最后一组不够8字节,对其补足若干个二进制0。
对每一组末尾添加一个字节,字节的值是 255减去该组填充的0字节的个数。
比如有下面几个字符串的转换示例:

这样构造完成c字段的编码字节数组,在其后接上两字节的经过最高位取反的id字段,组成一个key写入Rocksdb中即可。
简单分析一下该算法:
在两条记录的c字段字符串长度都小于8的情况下,由于都补齐了8字节,后面id字段并不会导致排序错乱。比如有下面三条index数据。

在一条记录的c字段小于8字节,另一条记录的c字段大于8字节的时候,比如有下面两条index数据:

由于c字段为abc的短字符串,其后添加了5个0,已然小于下面的长字符串,其后的字符串长度字段或id字段,再也没有机会影响短字符串跟长字符串的比较了。
五、构造联合索引
接下来我们看一个联合索引KEY `i_f_index` (`i`,`f`) ,这个是一个整数加一个浮点数。因为是非唯一索引,所以写入Rocksdb的key由两字节的i字段(最高位取反) + 4字节的f字段( 最高位取反+负数其他位也取反 ) + 2字节的主键id字段(最高位取反),value为空即可。
最后一个联合索引 KEY `i_c_f_index` (`i`,`c`,`f`) ,key中包含四种数据类型:整数,字符串,浮点数和主键id。只需要按照上述介绍的算法,依次处理每种数据类型拼接出key即可。
六、总结
我们有了索引,就可以像mysql一样,根据索引快速定位数据。如果一个查询语句有很多个过滤条件,涉及多个索引字段,选择不同的索引进行查询,得到的性能是不一样的。因此,也需要像mysql一样根据一些统计信息构造出一个查询计划,选择合适的索引列进行查询。感兴趣的同学可以继续关注一下直方图以及Count-Min Sketch等数据结构。另外,也需要深入了解Rocksdb的get mget seek scan等操作的原理和性能,结合数据库的统计信息才能更好的构造查询计划。
