什么样的快递物流会被用户认可?毫无疑问,一个不丢包裹、没有暴力分拣、送货速度快的企业会成为用户的首选。
如果我们把快递物流所发挥的作用放到数据中心看,那么同样,一个零丢包、低时延、高吞吐的网络更显得十分重要!
众所周知,数据中心有“三大件”:计算、存储和网络。存储主要用于存储业务应用的各类数据,计算从存储设备获取数据并对数据进行处理。网络则建立了计算和存储资源的通道,它是一条高速路、国道还是省道直接影响了数据中心的运行效率。

所以,业内的所有网络厂商都在不遗余力建好这条运送数据的“物流通道”。例如RDMA的出现,就是新型网络的成功探索,它可以实现业务应用直接访问网卡而不需经过CPU内核,从而减少时延又提升CPU利用率。
但是RDMA就是那条最佳的“物流”吗?虽然它有相比TCP/IP的诸多优点,但也存在一个很大的缺点:对网络丢包异常敏感。传统以太网0.1%的丢包,会导致RDMA协议处理能力下降50%,进而使得如今越来越热的AI训练的计算能力下降50%。
其实现行网络存在网络丢包和时延的矛盾点,单独解决某一个问题并不难,难点在于同时解决这两个问题,如何找到这个“跷跷板”的平衡点需要创新的技术。
这项创新技术被华为攻克,其提出的CloudFabric智简数据中心网络面向AI时代的子方案AI Fabric智能无损数据中心网络解决方案,首次解决了网络传输耗时和容易丢失数据这个两难的问题。
近日,AI Fabric所体现的创新与价值得到国际权威测试机构Tolly Group的认可,在其进行的对比测试验证结果表明,华为AI Fabric由CloudEngine系列数据中心交换机组网,相比业界其他主流厂商的组网方案,性能表现卓越,优于Tolly进行的对比测试验证的思科同等款型交换机的相同组网。
具体从高性能计算、人工智能/机器学习和分布式存储三大典型应用场景来看,Tolly对华为AI Fabric解决?案进?了性能评估,并与思科Nexus交换机组?性能进?了对比。华为和思科的?案均基于RDMA over Converged Ethernet(RoCEv2)。在所有三大场景中,华为AI Fabric解决方案的性能均优于思科。
AI训练效率对比高于27%
首先以大热的人工智能来说,在深度学习的AI训练模型中,为了满足处理海量非结构化数据的要求,计算单元从CPU发展到了GPU,存储介质从HDD机械硬盘演进到了SSD闪存盘,它们的性能均提升了100倍以上。然而,网络通信时延却成为整体性能提升的瓶颈。
即使逐渐兴起的RDMA网络,如同前文所说,也没有有效解决这个难题。
Tolly测试验证华为AI Fabric智能无损数据中心网络可以完美地解决此问题。经过严苛测试,在服务器通过AI算法深度学习识别图片的100Gbps时,AI Fabric可以完全做到0丢包,使得GPU每秒可以学习识别478个图片,这个结果高出思科27%。测试结果如下图所示:
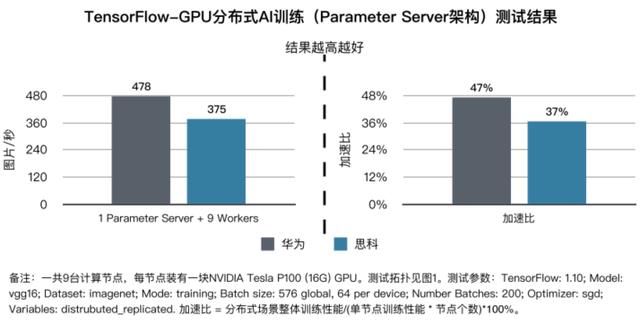
通信时延对比缩短30%
其次以高性能计算来看,由于HPC系统的MPI AllReduce模型常常导致网络中传输的数据量会瞬间撑爆网络管道。也就是网络会周期性爆发多打一的Incast流量,瞬间超过网络设备的承受能力,造成拥塞和丢包。
传统以太网为了防止数据丢失,会把这些数据放入缓存队列排队,并反复不断地重新传送,大大延长了网络传输时间,进而导致计算任务完成时间也被延长。如何平衡好网络丢包和时延成为令人头痛的难题。
Tolly测试验证华为AI Fabric可以很好地解决这个问题。高性能计算一般会把任务分解成8字节或者16字节的子任务。此时,AI Fabric不仅没有丢包,而且完成一次All Reduce计算任务的时间比思科缩短了30%。测试结果如下图所示:
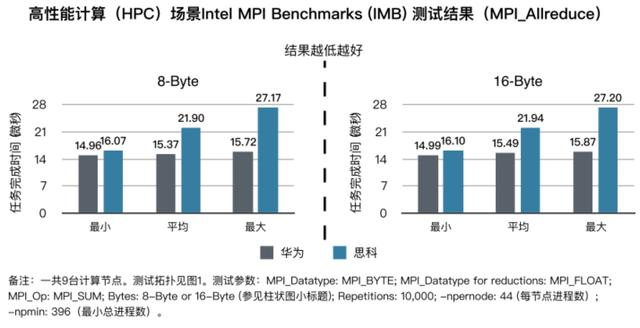
分布式存储IOPS性能对比高于30%
最后再从分布式存储来看,如同前文多次表述,存储介质从HDD到SSD,介质访问时延缩短了100多倍,然而传统以太网的通信时延上升到存储处理时间的50%以上。
通信时延大,存储访问I/O端口的时间就长,每秒可以访问的I/O端口数就少,存储访问I/O端口的IOPS性能就会受到严重制约,数据的实时存储也就无法实现。如何降低网络时延进而提升存储IOPS性能成为极大挑战。
Tolly测试再次验证,AI Fabric可以很好地使存储介质的IOPS性能发挥到极致。测试结果表明,相同的存储介质,部署AI Fabric后存储的IOPS性能相比思科提高了30%以上。测试结果如下图所示:
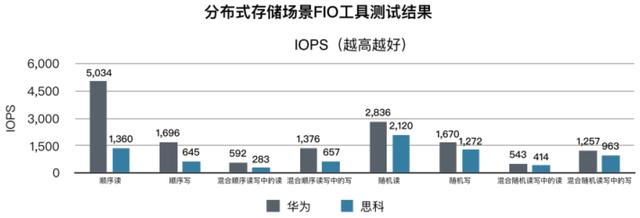
AI Fabric为何能做到“更快、更高、更强”?
其实此前,华为AI Fabric已经通过国际权威第三方独立测试机构EANTC的数据中心高性能测试,此次Tolly测试再一次表明,AI Fabric使数据中心“大脑”处理速度(HPC高性能计算)更快了,比以思科为代表的业界顶级水平提高了30%;“记忆”能力(存储IOPS)更高了,对比提高30%;“认知”能力(分布式AI训练)更强了,对比提高27%。
如果要问,AI Fabric为何能做到“更快、更高、更强”?这就不得不说到其所具备的几大关键技术:华为首次给CloudEngine数据中心交换机装上了智慧的“芯”,并独创了iLossless智能无损算法,实现定时采集流量特征和动态基线智能调整,最终带来0丢包、低时延、高吞吐的极致网络性能。
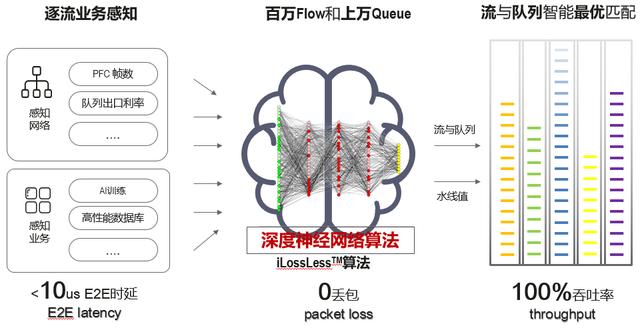
无论是硬件上的“芯”升级,还是软件算法上的突破,这些技术创新得以让华为AI Fabric智能无损数据中心网络解决方案性能表现卓越。
并且,华为AI Fabric在互联网和金融领域已有了成功实践。它让某互联网巨头无人驾驶应用的计算效率提升了40%,让招行存储的IOPS性能提高了20%。以数据说话,可以想见AI Fabric一定会吸引越来越多的企业选用。
新的机遇,AI Fabric正在引领数据中心迈向智能无损网络,推动企业加速迈向AI时代!
