今天,谷歌发布了一个端到端的移动端全神经语音识别器,来处理 Gboard 中的语音输入。该新型语音识别器可内置在手机设备中,离线状态时依然可用。更重要的是,它可以实现字符级实时输出,对用户的语音输入提供快速及时的响应。
2012 年,在深度学习技术的帮助下,语音识别研究有了极大进展,很多产品开始采用这项技术,如谷歌的语音搜索。这也开启了该领域的变革:之后每一年都会出现进一步提高语音识别质量的新架构,如深度神经网络、循环神经网络、长短期记忆网络、卷积神经网络等等。然而,延迟仍然是重中之重:自动语音助手对请求能够提供快速及时的反应,会让人感觉更有帮助。
今天,谷歌发布了一个端到端的移动端全神经语音识别器,来处理 Gboard 中的语音输入。在相关论文《Streaming End-to-End Speech Recognition for Mobile Devices》中,谷歌研究者展示了一个使用 RNN transducer (RNN-T) 技术训练的模型,它非常紧凑,因而可以内置在手机设备中。这意味着不再有网络延迟或 spottiness,新的语音识别器一直可用,即使是离线状态也可使用。该模型以字符级运行,因此只要用户说话,它就会按字符输出单词,就像有人在你说话的时候实时打字一样。
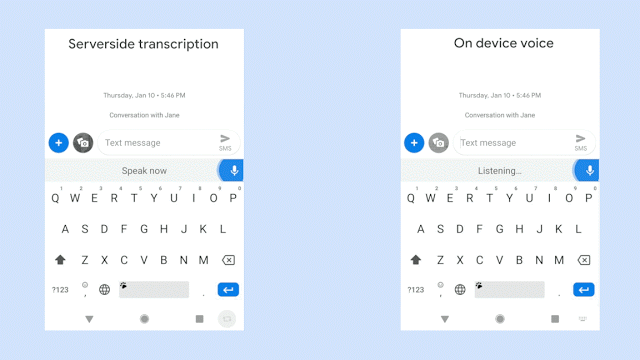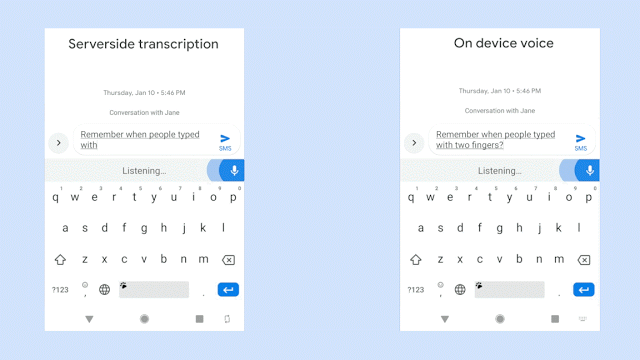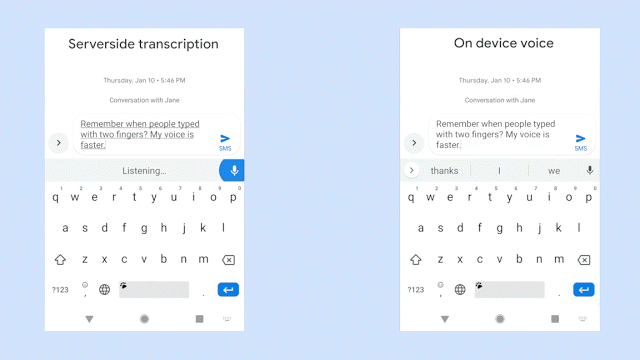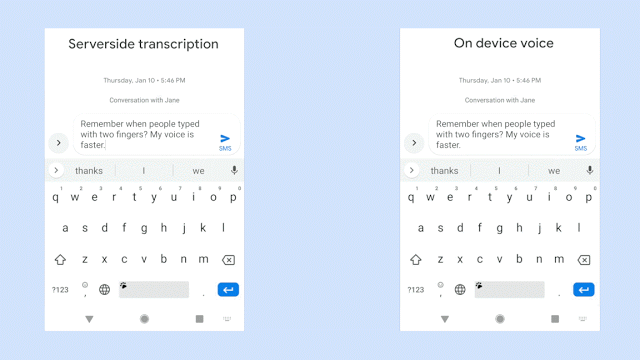
该视频在识别相同的语音句子时将服务器端语音识别器(左侧面板)与新型移动端识别器(右侧面板)进行对比。GIF 来源:Akshay Kannan 和 Elnaz Sarbar
语音识别历史
一直以来,语音识别系统包含多个组件:将音频片段(通常为 10 毫秒帧)映射到音素上的声学模型、将各音素结合在一起形成单词的发音模型,以及表达给定短语似然的语言模型。在早期语音识别系统中,这些组件保持独立优化。
2014 年左右,研究人员开始着重训练单一神经网络,直接将输入的音频波形映射到输出语句上。这种序列到序列的方法基于给定音频特征序列生成单词或字素序列,从而学习模型,这促进了「基于注意力」和「倾听-注意-拼写」(listen-attend-spell)模型的发展。虽然这些模型能够极大地保证准确性,但它们通常需要检查整个输入序列,并且在输入的同时无法实现输出,而这又是实时语音转录的必要特征。
与此同时,一种名为 connectionist temporal classification(CTC)的自主技术已经帮助生产级识别器将自身延迟减半。事实证明,这对创建 RNN-T 架构(最新发布版本采用的架构)来说是很重要的一步,RNN-T 可以看作是 CTC 技术的泛化。
RNN transducer
RNN-T 是一种不使用注意力机制的序列到序列(sequence-to-sequence)模型。大部分序列到序列模型通常需要处理整个输入序列(在语音识别中即波形)从而生成输出(句子),而 RNN-T 不一样,它连续处理输入样本,生成输出信号,这非常适合语音听写。在谷歌的实现中,输出信号是字母表中的字符。随着用户说话,RNN-T 识别器逐个输出字符,且在合适的地方加上空格。在这个过程中,该识别器还具备反馈循环(feedback loop),将模型预测的信号再输入到模型中,以预测下一个信号,如下图所示:
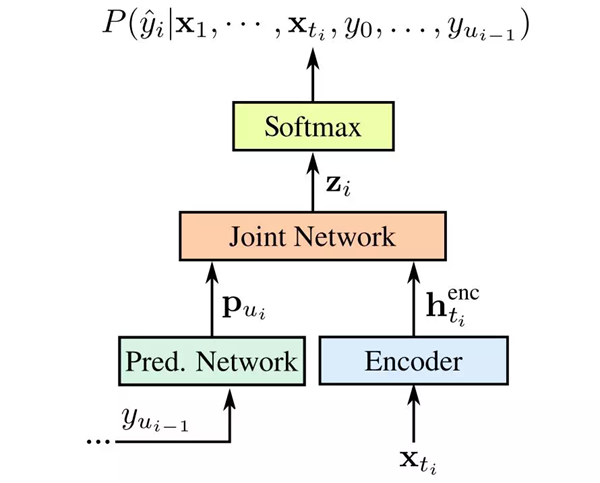
RNN-T 图示,输入语音样本为 x,预测信号为 y。
如上所示,RNN-T 通过预测网络(如 y_u-1)将预测信号(Softmax 层的输出)返回至模型,以确保预测结果基于当前语音样本和之前的输出得出。预测网络和编码器网络是 LSTM RNN,联合模型是前馈网络。预测网络由 2 个 LSTM 层组成,每个层包括 2048 个单元,以及一个 640 维的映射层。编码器网络有 8 个 LSTM 层。
高效训练此类模型已经非常困难,而在使用谷歌新型训练技术后(该技术将错词率降低了 5%,详见论文《MINIMUM WORD ERROR RATE TRAINING FOR ATTENTION-BASED SEQUENCE-TO-SEQUENCE MODELS》),训练变得更加计算密集。为此,谷歌开发了并行实现,这样 RNN-T 损失函数就可以在谷歌的高性能云 TPU v2 硬件上大批量高效运行。而这使训练速度实现了 3 倍加速。
离线识别
在传统的语音识别引擎中,上述的声学、发音和语言模型被「组合」成一个大型的搜索图。该搜索图的边是用语音单元及其概率来标记的。当语音波形被输入给识别器时,「解码器」会在该图中搜索给定输入信号的最大似然路径,并读取该路径采用的单词序列。通常,解码器假设底层模型的有限状态转换器(FST)表示。然而,虽然有复杂的解码技术,搜索图仍然很大,对谷歌的生产模型来说差不多是 2GB。因此该技术无法轻易地在移动手机上部署,而是需要在线连接才能正常工作。
为了提高语音识别的有用性,谷歌通过直接在设备上部署新模型,来避免通信网络的延迟和固有的不可靠性。所以,其端到端方法不需要在大型解码器图上进行搜索。相反,解码包括通过单个神经网络进行集束搜索(beam search)。谷歌训练的 RNN-T 模型的准确率能够媲美基于服务器的传统模型,但大小只有 450MB,本质上更智能地使用参数和更密集地打包信息。但即使是对现在的智能手机来说,450MB 也是不小的容量了,而在如此大的网络上传播信号会有些慢。
谷歌使用其在 2016 年开发的参数量化和混合核技术来进一步缩小模型体积,然后使用 TensorFlow Lite 库中的模型优化工具包使其公开可用。模型量化对训练好的浮点模型提供了 4 倍的压缩,实现了 4 倍的运行时加速,因此 RNN-T 在单核上的运行速度比实时语音要快。经过压缩后,最终模型只有 80MB 大小。
谷歌发布的这一新型全神经移动端 Gboard 语音识别器将首先用于所有使用美式英语的 Pixel 手机。谷歌希望可以将这项技术应用到更多语言和更多应用领域。
更为普及的语音输入
此外,今年一月份百度发布了同样关注语音识别的「百度输入法 AI 探索版」,其默认为全语音输入方式。如果不讨论使用场景,目前它的语音输入确实在准确度和速度上已经达到非常好的效果,包括中英混杂、方言和其它语种等。与谷歌关注移动端推断不同,百度的语音识别更关注在线的实时推断,他们提出了一种名为「流式多级的截断注意力(SMLTA)」模型。
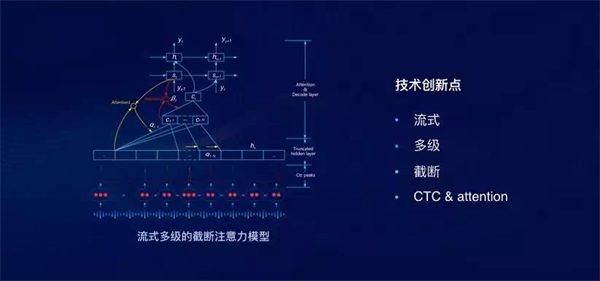
SMLTA 模型最核心的概念是利用 CTC 模型的尖峰对连续音频流做截断,然后在每个截断的小语音片段上进行注意力建模。这种模型利用了截断多级注意力对长句建模的优势,同时也解决了 CTC 模型的插入或删除错误对注意力模型的影响。此外,它采用的是一种局部注意力机制,因此能做到实时在线推断。
百度的 SMLTA 主要用于在线语音识别,但通过对 Deep Peak 2 模型的大量工程优化,它也能提供离线语音识别。机器之心发现百度输入法 AI 探索版的 APP 包(IOS)有 89.6MB,如果使用离线语音识别,需要额外下载一个 25MB 大小的包。
论文:Streaming End-to-end Speech Recognition For Mobile Devices

论文地址:https://arxiv.org/abs/1811.06621
摘要:根据给定输入语音直接预测输出字符序列的端到端(E2E)模型对移动端语音识别来说是不错的选择。但部署 E2E 模型的挑战也不少:为了应用到实际中,此类模型必须对语音进行流式的实时解码;它们必须稳健地支持长尾使用案例;它们必须能够利用用户特定的上下文(如联系人列表);此外,它们必须要非常准确。在本文中,我们用循环神经网络转换器(RNN transducer)构建了 E2E 语音识别器。经过试验评估,我们发现在很多评估项目中,该方法在延迟和准确率方面远超基于 CTC 的传统模型。
原文地址:https://ai.googleblog.com/2019/03/an-all-neural-on-device-speech.html