在传统的Web中,用户数据存储在自己能够完全控制的集中式存储服务器上。这种控制能力,为他们提供了在用户不知情或未经用户同意的情况下可能会滥用的高级特特权。此外,集中存储可能存在可用性问题,尤其是如果数据仅存储在一个位置时,会因此产生单点故障。
Web上的文件存储
web使用基于位置的寻址来存储和检索文件。假设我们想从域名abc.com访问一张关于猫的图片cat.png。我们会先通过Web浏览器访问这个位置(如abc.com/cat.png),然后,我们将得到猫的图片。但是,如果由于某种原因,文件已经从abc服务器上删除,我们就无法再访问该图片。现在有一种可能性是,网上的其他人也有这只猫的照片,但是我们无法联系到他们,也无法获取这只猫的照片。互联网上的许多文件都可能具有相同的名称,但内容可能不同。

IPFS解决方案
IPFS是一种用于文件存储的对等网络协议,采用的是基于内容的寻址,而非基于位置。这意味着要查找文件,我们不需要知道它在哪里(abc.com/cat.png),而是它包含的内容(QmSNssW5a9S3KVRCYMemjsTByrNNrtXFnxNYLfmDr9Vaan)——由内容的哈希进行表示。
哈希函数为每个文件创建唯一的“指纹”。因此,如果我们想要检索一个文件,只需询问网络“谁拥有这个文件(QmSNssW5a9S3KV…)”,然后来自IPFS网络的某个拥有该文件的人将提供给我们。我们可以通过将请求的哈希值与接收到的哈希值进行比较来验证文件的完整性,如果哈希值匹配,则可知该文件没有被更改。这个哈希函数还可以帮助消除网络的重复,这样具有相同内容的文件就无需提交两次,因为相同的内容会产生相同的哈希。这优化了存储需求,也提高了网络的性能。
IPFS如何存储文件
文件存储被为IPFS对象,后者是一种数据结构,包括:
·数据(Data )——一个二进制大对象(BLOB),可以存储高达256 KB。
·链接(Links)——链接IPFS对象的一个数组。
如果我们的文件大于256 KB,那么它将被拆分并存储在多个IPFS对象中,然后创建一个空对象,链接文件的所有其他对象。如下图所示:
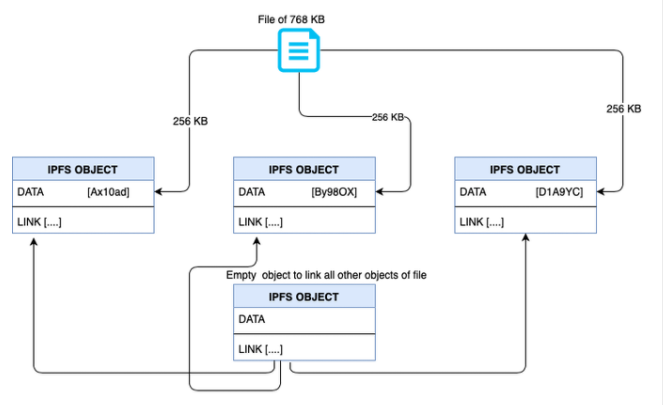
IPFS数据对象
IPFS作为一种不可变的存储方式工作,一旦某个东西被添加到网络中,它就不能被更改,因为更改文件将更改哈希。那么我们如何更新文件呢?为此,IPFS使用了版本控制系统,该系统特别是在开源社区中被广泛使用,被称为Git。IPFS具有“提交对象”,这有助于跟踪文件创建以来的所有版本。每当我们在IPFS网络上添加一个文件时,都会为该文件创建一个提交对象,当我们更新该文件时,会创建一个新的提交对象,该对象指向该文件的旧提交对象,如下图所示:
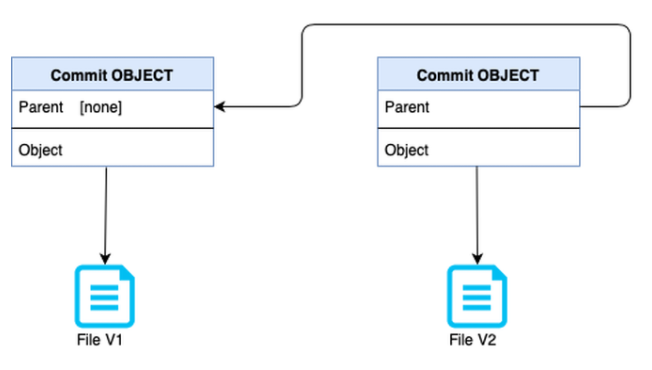
IPFS提交对象
我的文件永远存在于网络上吗?
只有重要的文件保存在网络上,不重要的文件会被垃圾回收器删除,其中文件的重要性由“Pinning”决定。通过Pinning一个文件,我们将该文件标记为一个重要的文件,这样不重要的文件只会被作为临时缓存,而该文件将持续存在。
IPFS的问题
现在,我们需要讲讲IPFS的相关挑战。IPFS最大的问题之一是保持文件可用,IPFS具备持久性,但无法保证持续性。也就是说,如果Alice上传了一个文件,让Bob来访问该文件;当Alice离线时,在垃圾收集器没有删除它时,Bob才可能继续访问它。另一方面,如果Bob已经Pinning了该文件,那么即使Alice的节点离线了,它也仍然可以访问。因此,Pinning是一个主要问题。目前有许多的公共Pinning服务,获得持续性是要付出一定代价的。
另一个限制是文件的实际共享。你必须通过传统的通信机制(例如即时消息、电子邮件、Skype、Slack等)与网络上的其他人共享文件链接(内容地址)。这意味着文件共享没有内置到系统中。现在有人已经开发出了网络爬虫和搜索引擎,但真正解决这个问题可能还需要一段时间。
原文作者:Usman Fazil 来源:Medium
