近年来,神经机器翻译的突飞猛进让越来越多的人类翻译感到压力山大,瑟瑟发抖,那么如此强大的机器翻译架构内部的运行机制究竟是怎样的?本文用一系列动图带你看个明白。
过去几十年来,统计机器翻译一直是占据主导地位的机器翻译模型[9],直到神经机器翻译(NMT)诞生。神经机器翻译(NMT)是近几年来新兴的机器翻译模式,该模式试图构建和训练能够读取输入文本,并输出翻译结果的单个大型神经网络。
NMT的最初来自Kalchbrenner和Blunsom(2013)等人的提议。今天更为人所知的框架是从Sutskever等人提出的seq2seq框架。本文就将重点介绍seq2seq框架以及如何构建基于seq2seq框架的注意力机制。
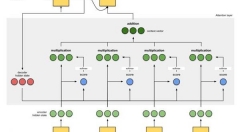
总体来说,注意力层的部署可以分为4步(其实是5步)
第0步:准备隐藏状态。
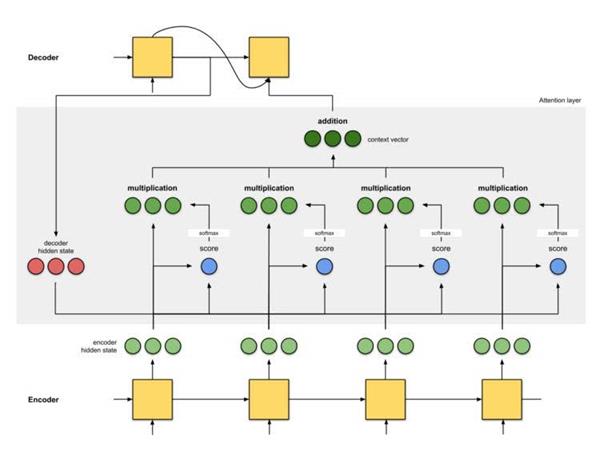
首先准备第一个解码器隐藏状态(红色)和所有可用的编码器隐藏状态(绿色)。在我们的例子中有4个编码器隐藏状态和当前解码器隐藏状态。
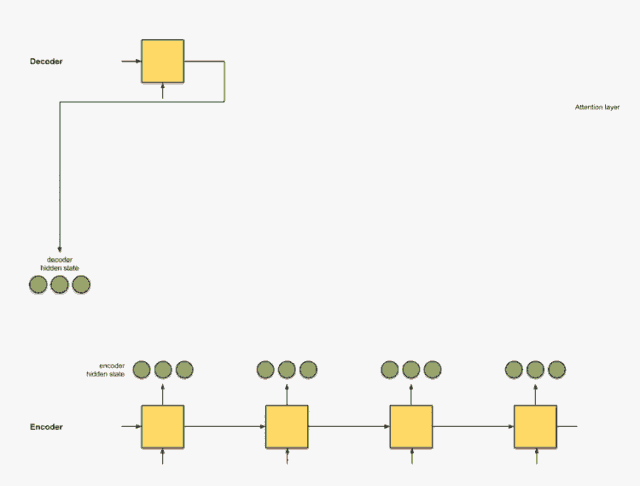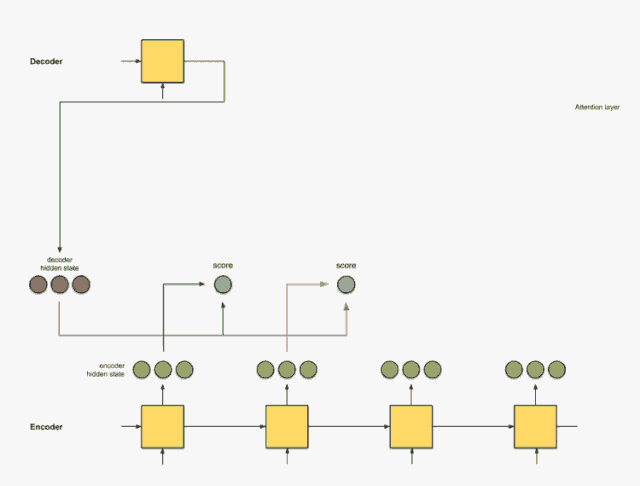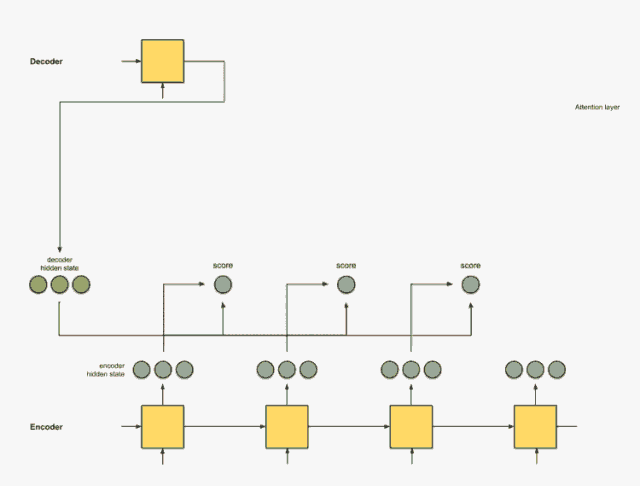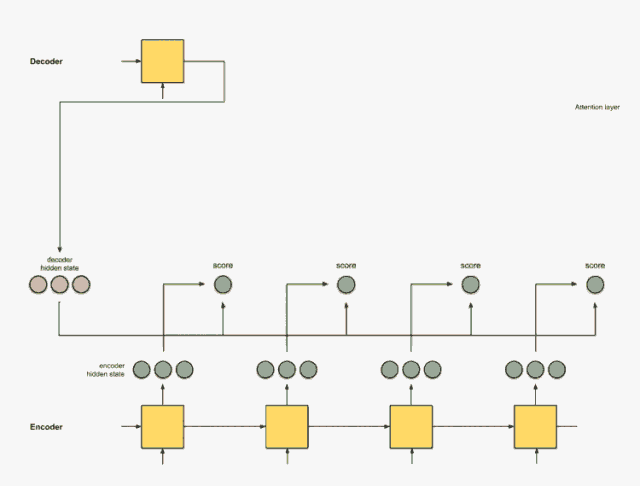
步骤1:获取每个编码器隐藏状态的分数
通过评分函数(也称为比对评分函数或比对模型)获得评分(标量)。在该示例中,得分函数是解码器和编码器隐藏状态之间的点积。
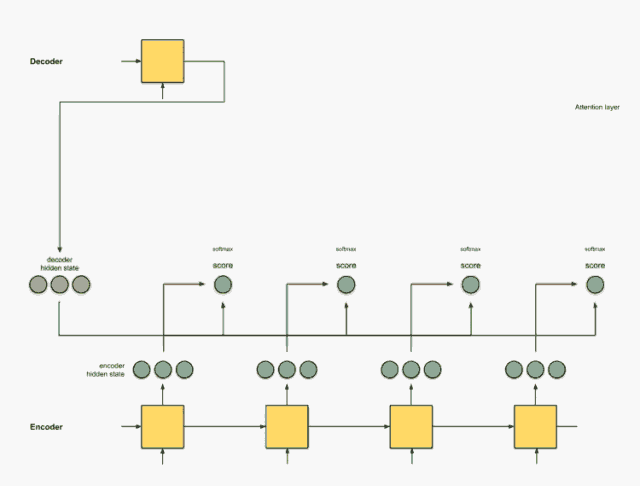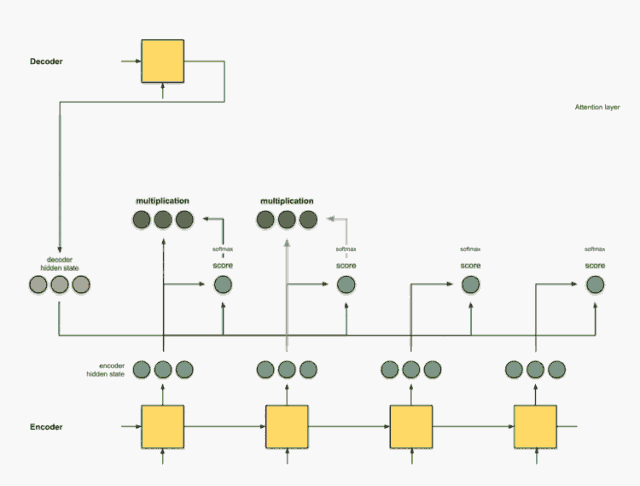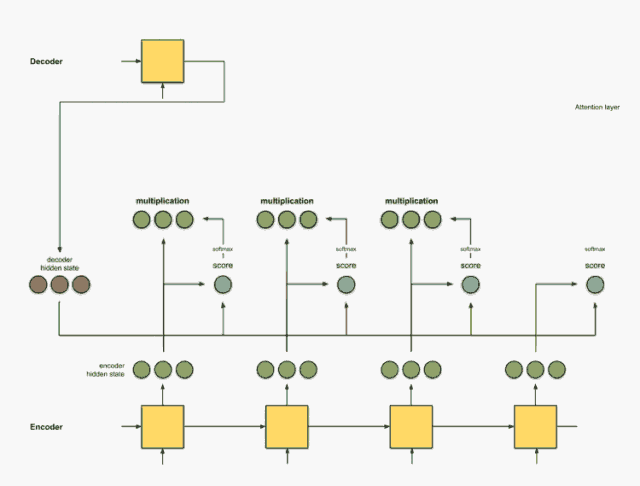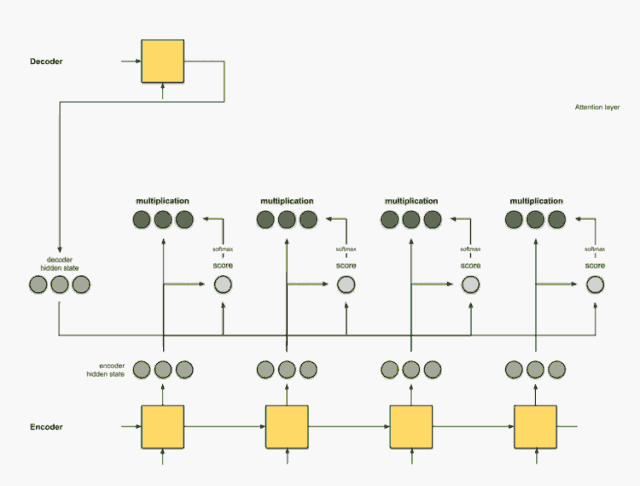
步骤2:通过softmax图层运行所有分数。
我们将得分放到softmax函数层,使softmax处理后的得分(标量)之和为1。这些得分代表注意力的分布。
步骤3:将每个编码器隐藏状态乘以其softmax得分。
通过将每个编码器隐藏状态与其对应的softmax得分(标量)相乘,获得对齐向量或注释向量。这就是对齐的机制。
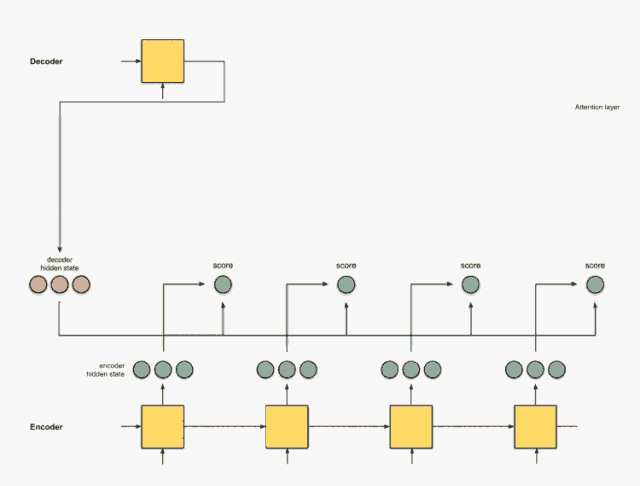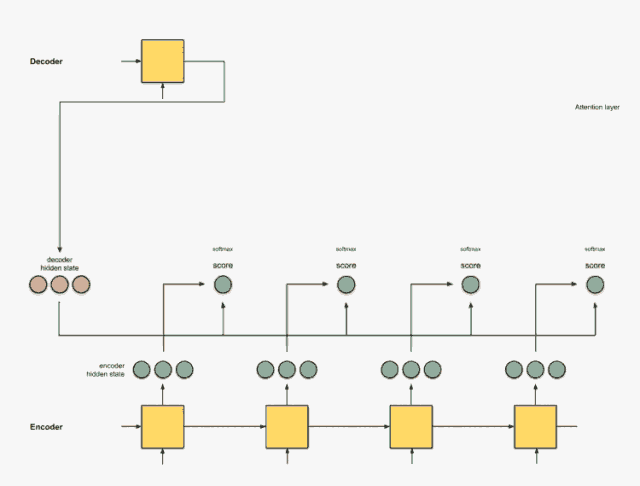
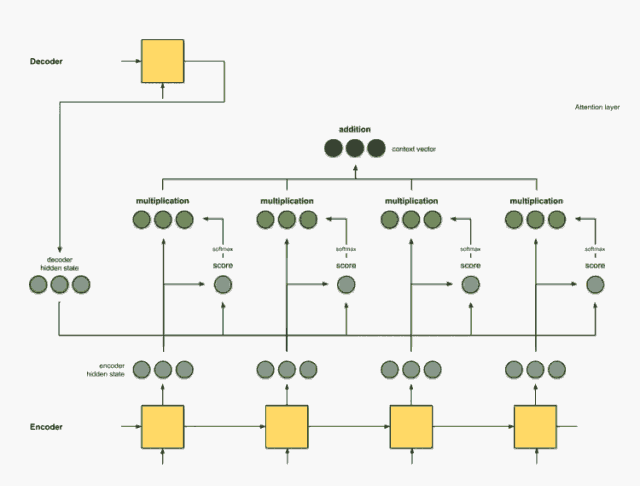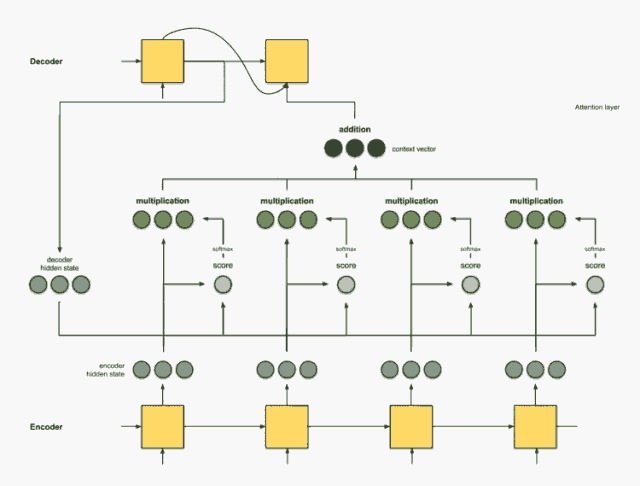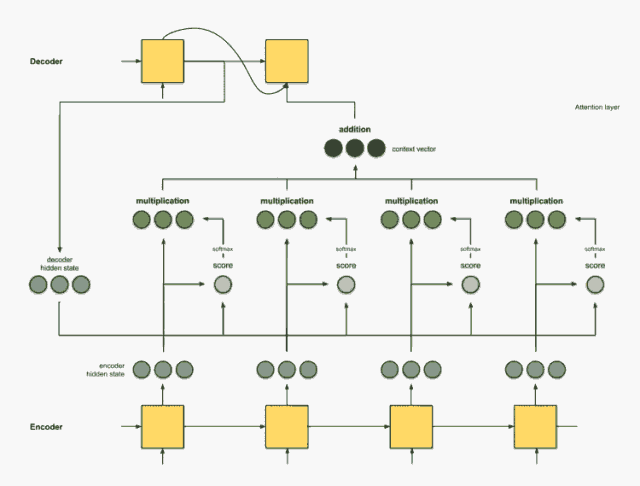
步骤4:总结对齐向量。
对齐向量的总结可以生成上下文向量。上下文向量反映的是前一步的对齐向量的聚合信息。

步骤5:将上下文向量送到解码器。
具体传送方式取决于翻译系统的架构设计。我们将在下文示例中看到不同的架构如何利用解码器的上下文向量。
下面来看看几种seq2seq模型的运行机制,为便于理解,我们采用比较直观的描述(对于每种模型,均以德-英翻译为例)。
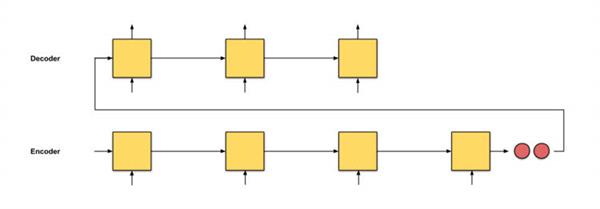
seq2seq
翻译会从头至尾把德语文本阅读一遍,读完开始逐词翻译成英语,如果句子过长,他可能会忘了文章开始时都读过哪些内容。
一个简单的seq2seq模型就是这样了,至于面向注意力层的逐级计算,是下面要讲的seq2seq+注意力模型,下面是这个模型的直观表述。
seq2seq+ 注意力
翻译一遍阅读德文文本,一边从头至尾地记录关键词,然后开始翻译成英语。每翻译一个德语词汇,都要用一次记下来的关键词。
该机制下会为每个单词分配一个得分,根据分数高低投入不同的注意力。然后根据Softmax函数处理过的分数,使用编码器隐藏状态的加权和来聚合编码器隐藏状态,获得上下文向量。注意力层的实现可以分为4个步骤。
注意力机制的运行究竟是怎样的?
答案是:反向传播,没想到吧。反向传播将尽一切努力确保产出成果接近实际情况。通过改变RNN中的权重和得分函数(如果有的话)来实现这一目标。这些权重将影响编码器隐藏状态和解码器隐藏状态,进而影响注意力得分。
带双向编码器的seq2seq+注意力
这一机制相当于有两名翻译。翻译A一边阅读德语文本,一边记录关键词。翻译B(比A更高级的翻译,可以从后往前倒着阅读然后进行翻译)也在逐词阅读同样的德语文本,同时记下关键词。
这两个翻译会定期讨论到目前为止阅读的每一个词。一旦阅读完毕,翻译B会负责根据讨论结果和选择的综合关键词,将德语的句子逐字翻译成英语。
翻译A就是前向RNN,翻译B就是后向RNN。
采用双层堆叠编码器的seq2seq+注意力
翻译A一边阅读德语文本,一边记录关键词。翻译B(比A更高级的翻译,可以从后往前倒着阅读然后进行翻译)也在逐词阅读同样的德语文本,同时记下关键词。注意,初级翻译A必须把阅读到的每个单词向翻译B报告。阅读完成后,两位翻译都会根据他们所选择的综合关键词,逐字逐句地将句子翻译成英语。
谷歌的神经机器翻译:带8个堆叠编码器的seq2seq(+双向+剩余连接)+注意力
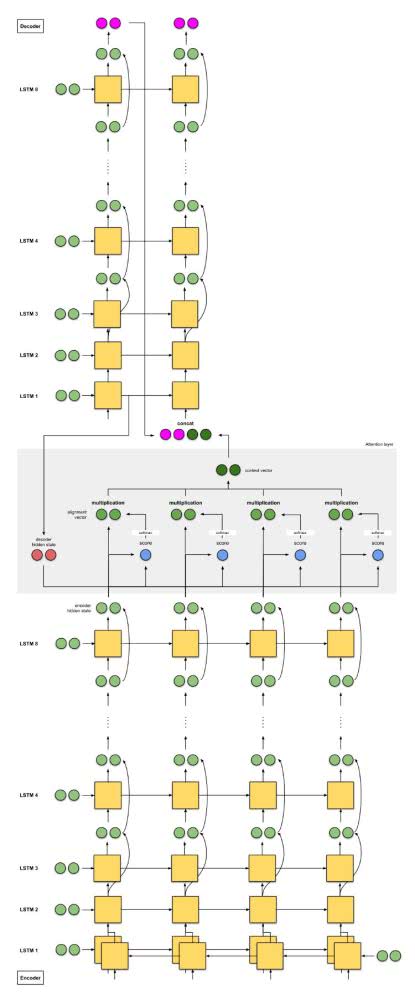
相当于翻译A、B、...到H一共8位翻译,从下到上排成一列。每位翻译都阅读相同的德语文本。每阅读一个单词,翻译A会与翻译B分享发现,翻译B对发现内容进行改进,并与翻译C分享,以此类推重复这个过程,直到翻译H为止。此外,在阅读德语文本时,翻译H会根据自己的知识和收到的信息记录下相关的关键词。
在每个翻译都阅读过英文文本之后,命令翻译A开始翻译第一个单词。首先,翻译A试图回忆起,然后他与译者B分享他的答案,译者B改进答案并与译者C分享,以此类推重复这一过程,直到翻译H。然后,翻译H根据记录的关键词写出第一个翻译。重复这个过程,直到翻译完成为止。