你也许听说过图形数据库,也知道它不是存储图片文件的数据库。但是:为什么总有人吹捧它是大数据时代的利器?是数据库领域重大的技术革新?它和传统的关系型数据库相比有哪些优劣?本文将带你揭开图形数据库的神秘面纱。
什么是图形数据库
要理解图形数据库,你暂时还不需要具备太多图论的知识。实际上,图形数据库(GDBMS)在笔者眼中比关系数据库(RDBMS)更容易理解。
图(Graph)由顶点(Vertex)和边(Edge)组成。
在图形数据库领域,我们有时候喜欢把顶点和边称为节点(Node)和关系(Relationship),但显然它们是同一回事。
每个节点表示一个实体(个人、地点、事物、类别或其他数据块),每个关系表示两个节点的关联关系。
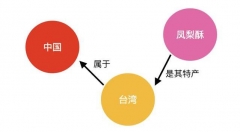
例如,两个节点 中国 和 台湾 的关系是 台湾 属于 中国;而两个节点台湾和凤梨酥 的关系是凤梨酥是台湾的特产。
为什么图数据库是未来的必然趋势?
我们生活的世界充满了对象之间的相互联系,你能举出一个例子,某一对象是完全孤立、不和外界发生任何关联吗?图数据库在描述、存储、查询这些关联时具有天生优势。
我们继续扩展上面的例子,上海也属于中国,陆家嘴位于上海,乔治在陆家嘴上班,佩奇是乔治的姐姐,佩奇来自台湾,乔治虽然出生在内地但是去过台湾,乔治还很喜欢吃凤梨酥。
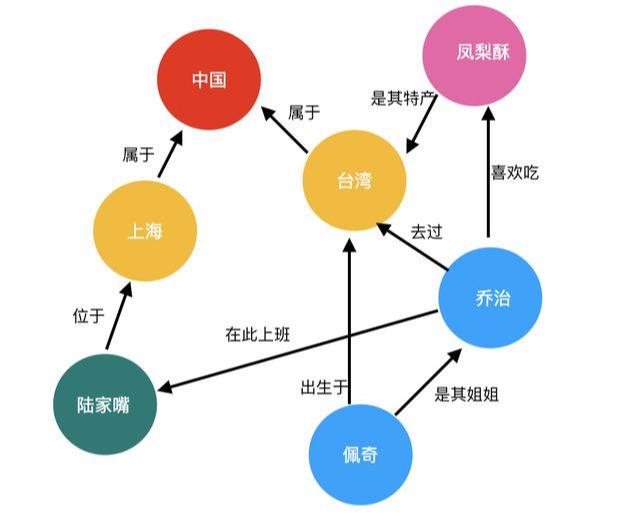
如果你是业务/产品工作人员,你一定希望你的产品或者业务涉及到用户的方方面面。如果你是开发人员,你一定希望能够简单高效地描述这个纷繁复杂的世界。
在传统的技术方中,一般会用关系型数据库对数据进行持久化(长时存储)。那么为了描述上图中的模型,我们需要建立多少张表呢?国家、省/市、人、食品、地标、国家与省/市关系、省/市与食品关系、人与省/市关系、人与……至少十几张表。
这倒没什么大不了的。
现在请查询:在哪个城市上班的人最喜欢吃凤梨酥?
嗯……你只需要关联食品表、人员表、人喜欢的食品关联关系表三张表就可以查到乔治等人喜欢吃凤梨酥,但是你还得再关联两张表找到他们在哪个地标工作,进而再关联两张表找到这些地标在哪个城市。还没完,你还得group by一下,再排个序。
你会觉得这个查询简直有病。但这恰恰是数据分析师最基本的工作,也是大数据时代海量信息处理的一个缩影。
利用图形数据库,我们可以更轻易地描述和更方便地查询上图所示的关系。下一节我们将看到,在关联关系更复杂的情形下,图形数据库的查询效率远远高于关系型数据库。
图数据库 VS 关系型数据库
1.性能
大数据时代,人类社会的数据量呈爆发式增长。任何业务或产品所积累的数据一定是快速增长的,这没有疑义,但更重要的是,数据与数据之间的连接(或者说关系)将呈现平方级增长:
3个点最多有6条有向边,4个点最多有12个有向边,N个节点最多有N * (N-1)个有向边。
在传统的数据库中,随着关系的数量和深度的增加,关系查询的效率将急剧衰减,甚至崩溃。
然而图形数据库的性能将几乎不变,即使数据每天都在增长。
这个性能差异有多大呢,引用Neo4j(一款图形数据库)发布的测试数据,我们希望在一个社交网络里找到最大深度为指定值的朋友组合。
在100万人的人群中,设置每个人大约有50个朋友,随机选择两个人,是否存在一条路径,使得他们之间的关联关系长度为2或3或4或5?
图形数据库与关系型数据库执行时间对比如下表。
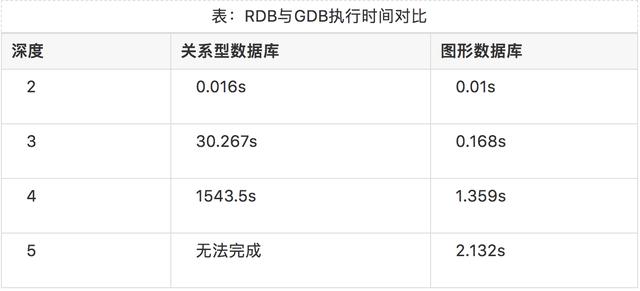
可见,在这种关联关系复杂且关联深度较大的情形下,用图形数据库对阵关系型数据库简直好比降维打击。
2.灵活性
图形数据模型的结构和模式随着解决方案和行业的变化而变化。开发团队不必提前对未来的需求进行详尽的建模(然后在某些业务/产品人员要求更改后彻底地推翻重做);相反,新的节点、关系、节点的属性还有关系的属性都可以后期添加到现有结构中,完全不会危及当前的功能。
一个有趣的说法是:面对图形数据库模型,你只需要口述你的需求,然后让它作出改变;而关系型数据库模型则恰好相反,它告诉你它的需求,迫使你适应它那该死的表格结构。
3.敏捷性
使用图形技术开发完全符合当今的敏捷、测试驱动的开发实践,它允许数据层支持的应用程序随着业务需求的发展而快速迭代更新。
有哪些好用的图形数据库(最好是开源的)?
图形数据库技术日益发展的今天,已经有不少优秀的项目诞生并在各领域大展身手,比如:
Neo4j, Titan, JanusGraph, ArangoDB, OrientDB等。