Hadoop对与喜欢大数据或者是想在参加大数据培训以及正在学习大数据开发的小伙伴不算陌生,但是Hadoop生态新增列式存储系统Kudu有多少的小伙伴了解呢?本编文章扣丁学堂小编就带大家看一下大数据分析教程Hadoop生态新增列式存储系统Kudu。

大数据培训
Hadoop生态系统发展到现在,存储层主要由HDFS和HBase两个系统把持着,一直没有太大突破。在追求高吞吐的批处理场景下,我们选用HDFS,在追求低延迟,有随机读写需求的场景下,我们选用HBase,那么是否存在一种系统,能结合两个系统优点,同时支持高吞吐率和低延迟呢?
有人尝试修改HBase内核构造这样的系统,即保留HBase的数据模型,而将其底层存储部分改为纯列式存储(目前HBase只能算是列簇式存储引擎),但这种修改难度较大。Kudu的出现有望解决这一难题。
Kudu是Cloudera开源的列式存储引擎,具有以下几个特点:
C++语言开发
高效处理类OLAP负载
与MapReduce,Spark以及Hadoop生态系统中其他组件进行友好集成
可与Cloudera Impala集成,替代目前Impala常用的HDFS+Parquet组合
灵活的一致性模型
顺序写和随机写并存的场景下,仍能达到良好的性能
高可用,使用Raft协议保证数据高可靠存储
结构化数据模型
Kudu的出现,有望解决目前Hadoop生态系统难以解决的一大类问题,比如:
流式实时计算结果的更新
时间序列相关应用,具体要求有:
查询海量历史数据
查询个体数据,并要求快速返回
预测模型中,周期性更新模型,并根据历史数据快速做出决策
Kudu架构如下图所示:
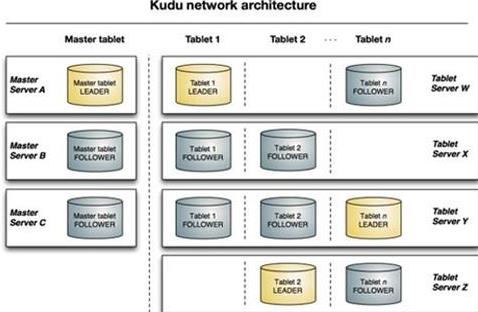
大数据学习
目前Kudu处于beta版,仍在不断开发迭代中,不久将提交并成为Apache Software Foundation incubator,据有关资料介绍,国内小米参与了kudu的开发,并做出不少贡献。据小米首席架构师介绍:"作为Hadoop生态系统的长期用户和贡献者,小米在Kudu项目初期就开始了和Cloudera的合作开发,并已经将Kudu独特的实时数据分析功能用到了小米业务中。"
