人工智能对许多行业都产生了实际影响,它在一些图像识别和语音识别任务上超过了人类,在各种游戏中也击败了专业玩家。人工智能能够应用于医学、媒体、娱乐以及安全领域。自动驾驶汽车每年会大幅减少130万的道路交通死亡人数,这些事故主要是因为人为失误。
“除非你与世隔绝,否则你一定会知道人工智能革命方兴未艾,”Nvidia首席科学家兼研究主管Bill Dally在最近的VLSI研讨会上说道,“人类生活和商业的每个方面都将受到人工智能的深刻影响。”
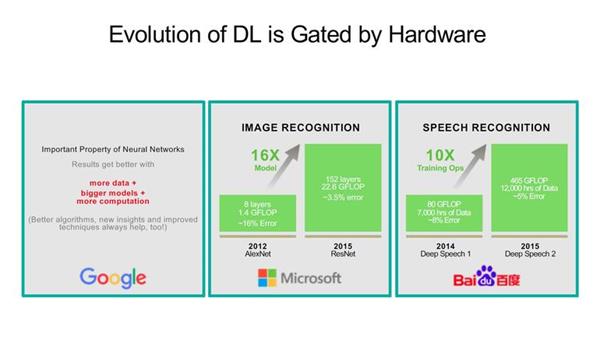
Dally说道:“尽管取得了这些进步,深度学习依然是‘完全由硬件支撑’,因为处理的工作量越来越大。目前,ImageNet被认为是一个小型数据集,在超过10亿个图像上进行训练的一些云数据中心,并使用超过1,000个GPU”。微软的ResNet-50神经网络需要77.2亿次操作来处理一个低分辨率(225x225)图像。在他的演讲中,Dally讨论了电路设计可以提高训练和在线推断效率,以满足这些不断增长的要求的一些方法。
“深度神经网络中的算法主要由卷积和矩阵乘法组成。训练需要至少半精度(FP16),”Dally说,“最先进的是Tesla V100的Tensor Cores,每秒可进行120万亿次操作,效率非常高。”“CPU和FPGA的数量级下降,即使是定制芯片,每瓦性能也会提高30%。”
Tesla V100是当前世界上最快超级计算机的核心。Summit有4608个计算节点,每个节点都有两个IBM Power9处理器和6个Tesla V100,总共有27648个GPU,理论峰值吞吐量为3亿亿次(官方测量HPL实测性能为122.3PFlops)。Dally表示橡树岭国家实验室已经在“有意义的应用程序”上运行了能够支撑1.6 exaops(相当于160亿亿次)的多重精度人工智能运算模拟实验。
但是运行这些训练模型是不一样的。就在线推断技术而言,在INT8上已经有了足够的精确度,而且降低精确度能够节约能源,因为矩阵乘法会已二次方的数量增加,同时也会减少芯片面积(因此会降低成本)。Xavier SoC的计算力只有V100的1/10,但是有了类似谷歌TPU的固定函数深度加速器(fixed-function deep-learning accelerator),能够进行每秒20万亿次的运算操作。需要注意的是,谷歌将其TPU和老款的Nvidia K80进行对比,Dally表示基于Pascal架构的Tesla P40已经能够进行更加优秀的推理运算。
在线推理技术的挑战在于解决实时使用最少数量能源时的大量的运算操作。例如,Nvidia DriveNet有12个摄像头,在4个分开的神经网络中运行。高清分辨率要求其在每张照片上每秒要进行9.4万亿次的运算操作。Dally说道:“这是很庞大的计算载量,需要在能源有限的工具中完成。”
访问本地SRAM每个字消耗5皮焦耳,片上高速缓存消耗50皮焦耳,而低功耗DDR DRAM(或高带宽内存)则为640皮焦耳,“所以你必非要停止芯片运行”。在10焦耳时,计算成本非常低,甚至从SRAM中提取数据也开始占主导地位。 Dally提出了一些降低三级通信成本的技术:片上、模块和模块之间。
在降低精度之后,下一个技巧是利用大多数神经网络模型中的数据稀疏性。 Nvidia之前提出了一个三步流程,包括训练网络以了解哪些连接很重要,修正不重要的参数,然后重新训练网络以微调剩余连接的权重以恢复准确性。通过在乘法累加运算中重用数据,系统可以最小化存储器带宽和功率。
当你需要进入存储器时,片上导线非常密集,但并不节能,而且由于电源电压增长非常缓慢,因此也不太可能改善。 Nvidia提出了首次在ISSCC上展示的这个想法——电荷再生信号,它使用堆叠的线路中继器使片上能效提高了四倍。为了避免干扰,Nvidia借用平衡线路上的流量平衡概念——通常用于半定制材料以穿越更长的距离——以创建仅消耗一平方毫米芯片面积的网络芯片结构并具有每秒4TB的带宽。
在模块级别,Dally谈到了一个阵列,该阵列由4个DRAM内存堆栈包围的GPU组成。这些多芯片模块还需要密集且节能的信号。每个GPU需要每秒1兆兆位的DRAM带宽——这个数字随着GPU性能提高而增长——并且GPU需要以相当的带宽相互连接。由于每个芯片在每个边沿上只有几百个可用分配信号管脚(signal pins),因此你需要20Gbps或更高的信号速率才能达到此吞吐量水平。传统的SerDes链路使用大量功率,但Nvidia一直在尝试一种称为地参考信号(GRS)的技术,Dally表示该技术可以在高达25bps的速度下可靠运行,同时使用大约20%的功率。 GRS可用于在单个模块中连接多个芯片或连接在印刷电路板上紧密排列在一起的多个Package。
在顶层,Nvidia谈到了一种更有效的方式来连接多个模块。为了训练像ResNet-50这样的大型模型,每个GPU需要大约每秒400GB的I / O带宽来交换参数。使用印刷电路板中的带状线和通孔,在模块之间发送高速数据的传统方法,每比特消耗10至15皮焦耳。相反,Nvidia建议将模块与液体冷却紧密地封装在一起,然后将它们直接连接到柔性印刷电路板链路上。当以25Gbps发送信号时,40mm的封装边缘可以支持每GPU 400到500GBps的I / O带宽,而每位仅使用两个皮焦耳。
Nvidia是否会在未来加速器和DGX系统中采用任何这些研究思路尚不清楚。然而,显而易见的是,该行业不再指望摩尔定律每两年提供相同的性能改进。由于原始计算能力在每瓦性能方面达到极限,因此移动数据的成本已经成为瓶颈,并且在系统设计的各个层面都需要一些创造性的想法来继续扩展人工智能。
原文作者:John Morris