语言是人与人之间最重要的交流方式、能与机器进行自然的人机交流,是人类一直期待的事情。随着人工智能快速发展。语音识别技术作为人机交流接口的关键技术、发展迅速。在AI领域也是经常被提及。作为人工智能领域的从业者认识语音识别也是必须的。接下来就让我们科普科普。话不多说,直接上菜!
语音识别概述
语音识别技术就是让机器通过识别和理解过程,把语音信号转变为相应的文本或命令的技术。
语音识别涉及的领域包括:数字信号处理、声学、语音学、计算机科学、心理学、人工智能等,是一门涵盖多个学科领域的交叉科学技术。
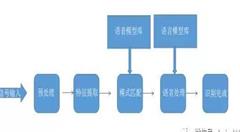
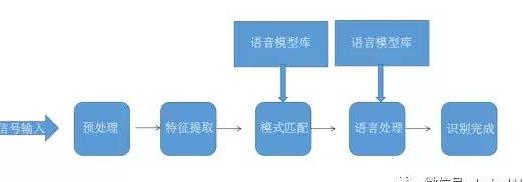
语音识别的技术原理是模式识别,其一般过程可以总结为:
预处理---特征提取---基于语音模型库下的模式匹配---基于语言模型库下的语言处理---完成识别
预处理
声音的实质是波。语音识别所使用的音频文件格式必须是未经压缩处理的文件,如人类正常的语音输入等
语音输入所面对的环境是复杂的主要存在以下问题
对自然语言的识别和理解。首先必须将连续的讲话分解为词、音素等单位,其次要建立一个理解语义的规则。
语音信息量大,语音模式不仅对不同的说话人不同,对同一说话人也是不同的,例如,一个说话人在随意说话和认真说话时的语音信息是不同的。一个人的说话方式随着时间变化。
语音的模糊性。说话者在讲话时,不同的词可能听起来是相似的。这在英语和汉语中常见。
单个字母或词、字的语音特性受上下文的影响,以致改变了重音、音调、音量和发音速度等。
环境噪声和干扰对语音识别有严重影响,致使识别率低。
所以预处理环节需要做到两个方面 静音切除、噪音处理和语音增强
01静音切除
又称语音边界检测或者说是端点检测是指在语音信号中将语音和非语音信号时段区分开来,准确地确定出语音信号的起始点然后从连续的语音流中检测出有效的语音段。它包括两个方面,检测出有效语音的起始点即前端点,检测出有效语音的结束点即后端点。经过端点检测后,后续处理就可以只对语音信号进行,这对提高模型的精确度和识别正确率有重要作用。
在语音应用中进行语音的端点检测是很必要的,首先很简单的一点,就是在存储或传输语音的场景下,从连续的语音流中分离出有效语音,可以降低存储或传输的数据量。其次是在有些应用场景中,使用端点检测可以简化人机交互,比如在录音的场景中,语音后端点检测可以省略结束录音的操作。有些产品已经使用循环神经网络( RNN)技术来进行语音的端点检测。
02噪音处理
实际采集到的音频通常会有一定强度的背景音,这些背景音一般是背景噪音,当背景噪音强度较大时,会对语音应用的效果产生明显的影响,比如语音识别率降低,端点检测灵敏度下降等,因此在语音的前端处理中,进行噪声抑制是很有必要的。噪声抑制的一般流程:稳定背景噪音频谱特征,在某一或几个频谱处幅度非常稳定,假设开始一小段背景是背景噪音,从起始背景噪音开始进行分组、Fourier变换,对这些分组求平均得到噪声的频谱。降噪过程是将含噪语音反向补偿之后得到降噪后的语音。
03语音增强
主要任务就是消除环境噪声对语音的影响。目前,比较常见的语音增强方法分类很多。其中基于短时谱估计增强算法中的谱减法及其改进形式是最为常用的,这是因为它的运算量较小,容易实时实现,而且增强效果也较好。此外,人们也在尝试将人工智能、隐马尔科夫模型、神经网络和粒子滤波器等理论用于语音增强,但目前尚未取得实质性进展。
声学特征提取
人通过声道产生声音,声道的形状决定了发出怎样的声音。声道的形状包括舌头,牙齿等。如果我们可以准确的知道这个形状,那么我们就可以对产生的音素进行准确的描述。声道的形状在语音短时可以由功率谱的包络中显示出来。因此,准确描述这一包络的特征就是声学特征识别步骤的主要功能。接收端接收到的语音信号经过上文的预处理以后便得到有效的语音信号,对每一帧波形进行声学特征提取便可以得到一个多维向量。这个向量便包含了一帧波形的内容信息,为后续的进一步识别做准备
本文主要介绍使用最多的MFCC声学特征。
01MFCC简介
MFCC是Mel-Frequency Cepstral Coefficients的缩写,顾名思义MFCC特征提取包含两个关键步骤:转化到梅尔频率,然后进行倒谱分析
Mel频率倒谱系数的缩写。Mel频率是基于人耳听觉特性提出来的,它与Hz频率成非线性对应关系。Mel频率倒谱系数(MFCC)则是利用它们之间的这种关系,计算得到的Hz频谱特征
02MFCC提取流程
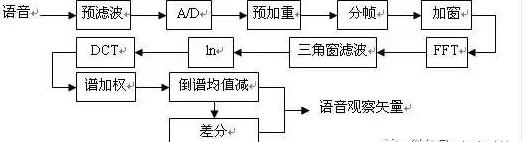
MFCC参数的提取包括以下几个步骤:
预滤波:CODEC前端带宽为300-3400Hz的抗混叠滤波器。
A/D变换:8kHz的采样频率,12bit的线性量化精度。
预加重:通过一个一阶有限激励响应高通滤波器,使信号的频谱变得平坦,不易受到有限字长效应的影响。
分帧:根据语音的短时平稳特性,语音可以以帧为单位进行处理,实验中选取的语音帧长为32ms,帧叠为16ms。
加窗:采用哈明窗对一帧语音加窗,以减小吉布斯效应的影响。
快速傅立叶变换(Fast Fourier Transformation, FFT):将时域信号变换成为信号的功率谱。
三角窗滤波:用一组Mel频标上线性分布的三角窗滤波器(共24个三角窗滤波器),对信号的功率谱滤波,每一个三角窗滤波器覆盖的范围都近似于人耳的一个临界带宽,以此来模拟人耳的掩蔽效应。
求对数:三角窗滤波器组的输出求取对数,可以得到近似于同态变换的结果。
离散余弦变换(Discrete Cosine Transformation, DCT):去除各维信号之间的相关性,将信号映射到低维空间。
谱加权:由于倒谱的低阶参数易受说话人特性、信道特性等的影响,而高阶参数的分辨能力比较低,所以需要进行谱加权,抑制其低阶和高阶参数。
倒谱均值减(Cepstrum Mean Subtraction, CMS):CMS可以有效地减小语音输入信道对特征参数的影响。
差分参数:大量实验表明,在语音特征中加入表征语音动态特性的差分参数,能够提高系统的识别性能。在本系统中,我们也用到了MFCC参数的一阶差分参数和二阶差分参数。
短时能量:语音的短时能量也是重要的特征参数,本系统中我们采用了语音的短时归一化对数能量及其一阶差分、二阶差分参数。
MFCC提取一般流程
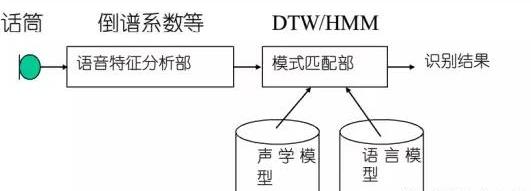
模式匹配 和语言处理
 」
」
通过语音特征分析以后接下来就是模式匹配和语言处理
声学模型是识别系统的底层模型,并且是语音识别系统中最关键的一部分。声学模型的目的是提供一种有效的方法计算语音的特征矢量序列和每个发音模板之间的距离。声学模型的设计和语言发音特点密切相关。声学模型单元大小(字发音模型、半音节模型或音素模型)对语音训练数据量大小、系统识别率,以及灵活性有较大的影响。必须根据不同语言的特点、识别系统词汇量的大小决定识别单元的大小。
语言模型对中、大词汇量的语音识别系统特别重要。当分类发生错误时可以根据语言学模型、语法结构、语义学进行判断纠正,特别是一些同音字则必须通过上下文结构才能确定词义。语言学理论包括语义结构、语法规则、语言的数学描述模型等有关方面。目前比较成功的语言模型通常是采用统计语法的语言模型与基于规则语法结构命令语言模型。语法结构可以限定不同词之间的相互连接关系,减少了识别系统的搜索空间,这有利于提高系统的识别。语音识别过程实际上是一种认识过程。就像人们听语音时,并不把语音和语言的语法结构、语义结构分开来,因为当语音发音模糊时人们可以用这些知识来指导对语言的理解过程,但是对机器来说,识别系统也要利用这些方面的知识,只是如何有效地描述这些语法和语义还有困难:
小词汇量语音识别系统。通常包括几十个词的语音识别系统。
中等词汇量的语音识别系统。通常包括几百个词至上千个词的识别系统。
大词汇量语音识别系统。通常包括几千至几万个词的语音识别系统。这些不同的限
制也确定了语音识别系统的困难度。模式匹配部是语音识别系统的关键组成部分,它一般采用“基于模式匹配方式的语音识别技术”或者采用“基于统计模型方式的语音识别技术”。前者主要是指“动态时间规整(DTW法”,后者主要是指“隐马尔可夫(HMM)法”。
隐马尔可夫模型(HMM)是语音信号处理中的一种统计模型,是由Markov链演变来的,所以它是基于参数模型的统计识别方法。由于其模式库是通过反复训练形成的与训练输出信号吻合概率最大的最佳模型参数而不是预先储存好的模式样本,且其识别过程中运用待识别语音序列与HMM参数之间的似然概率达到最大值所对应的最佳状态序列作为识别输出,因此是较理想的语音识别模型。
动态时间归整)算法:在孤立词语音识别中,最为简单有效的方法是采用DTW(Dynamic Time Warping,动态时间归整)算法,该算法基于动态规划(DP)的思想,解决了发音长短不一的模板匹配问题,是语音识别中出现较早、较为经典的一种算法,用于孤立词识别。HMM算法在训练阶段需要提供大量的语音数据,通过反复计算才能得到模型参数,而DTW算法的训练中几乎不需要额外的计算。所以在孤立词语音识别中,DTW算法仍然得到广泛的应用。
小结:语音识别在移动终端上的应用最为火热,语音对话机器人、智能音箱、语音助手、互动工具等层出不穷,许多互联网公司纷纷投入人力、物力和财力展开此方面的研究和应用。语音识别技术也将进入工业、家电、通信、汽车电子、医疗、家庭服务、消费电子产品等各个领域。尤其是在智能家居系统中语音识别将成为人工智能在家庭重要的入口,同时,未来随着手持设备的小型化,智能穿戴化也将成为语音识别技术的重要应用领域。